货拉拉Android稳定性治理实践!
App Crash对于用户来讲是一种最糟糕的体验,它会导致流程中断、app口碑变差、app卸载、用户流失、订单流失等。相关数据显示,当Android App的崩溃率超过0.4%的时候,活跃用户有明显下降态势。根据统计2021年初我们的Crash率为5%,大量的研发时间用于定位和解决用户反馈、用户投诉,crash治理刻不容缓。通过去年的大量实践治理,我们app的Crash率降低并且稳定在0.02%,在此做一些总结和分享,希望能为其他团队提供经验和启发。
行业标准
根据《2020移动应用性能管理白皮书 | 基调听云》

治理前的整体状况
App的Crash率高达5+%,随着产品的不断迭代,复杂度不断提升,给Crash率降低带来巨大挑战,我们必须在处理好新生的Crash的同时针对遗留的Crahs进行清理。Crash部分分为两部分,Native部分crash占比高达72%,这部分的Crash主要来源于Flutter、第三方的地图和第三方的SDK,难以解决。Java部分的crash很多没有得到及时解决,大量遗留的历史债,多数有通用的解决方案。
Crash治理方法
常见Crash的处理方式
- 根据Crash统计平台的堆栈,用户日志,操作路径定位和解决
- 寻找共性,机型、品牌、系统版本、所在页面、用户操作等辅助解决问题
- 复现场景,能够复现通常就很容易解决,可以线下复现或者云真机复现
其他处理方式
- 对crash率较高的模块进行业务梳理,排查,重构等
- 与第三方sdk沟通升级解决问题,修改SDK的使用方式
Crash治理实践
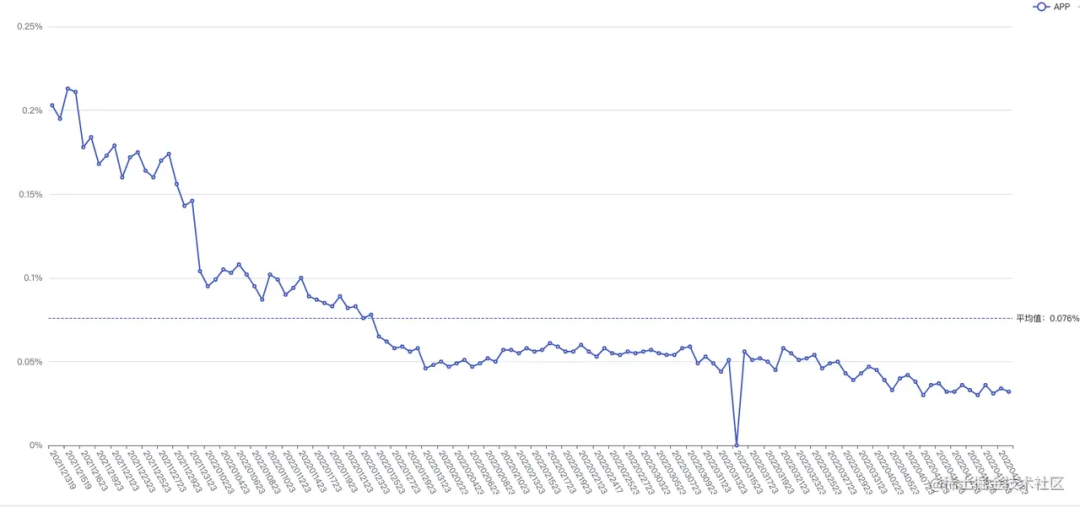
由于内部的统计平台建设比较晚,我们只能获取到近期的Crash率变化,可以看到Crash率明显收敛。
1、代码重构
为应对需求的频繁变化、提高研发效率,货拉拉首页、确认下单页等使用Flutter和小程序实现,而这部分是用户使用率最高的页面,代码量庞大而且复杂。在线上环境中产生了大量的Crash,大部分的Crash为偶发,线下环境无法复现,从堆栈情况很难定位问题的根源,修改起来有可能涉及到多端,各端都需要进行回归校验。经过综合分析,我们决定梳理逻辑,让最重要的这部分代码回归原生,重构上线之后Crash率明显下降,由原来的5%下降到0.5%,稳定性大幅提高。
2、三方SDK和Native崩溃处理
这部分的Crash处理使我们从Crash率由千分位降低到了0.05%。在初期我们很容易解决了java部分的Crash,然而第三方sdk和Native的Crash居高不下,有很长一段时间我们通过提交工单,咨询对接方等形式并没有办法得到解决。对于有些crash,我们升级了sdk发现crash量反而增加,又需要降级回旧版本。对于有些crash,堆栈信息却跟这个sdk没有关系。针对这些部分的崩溃通常用以下两种方式解决:
- 查看Api的调用存在问题(调用时机,调用顺序,传入参数,调用的线程或者进程等)
- 沟通解决,(在没有一对一开发对接的情况下,尝试提工单咨询),将Crash的堆栈发送给第三方SDK进行处理
我们两组Crash量最高的为例:
2.1 第三方VMP线程监控内存情况并关闭App导致
Crash统计平台上有大量的Native崩溃SIGSEGV(SEGV_MAPERR)、SIGABRT和SIGSEGV(SEGV_ACCERR)等,堆栈通常为系统级别的so内部(libgui.so、libGLES_mali.so和libc.so等),从抓取的堆栈中我们无法得知问题根源。我们已知的信息是Vivo手机Android10,Android11崩溃率极高,为此我们病急乱投医式进行了几种尝试:
- 错误堆栈中有出现硬件加速相关的so,我们尝试关闭了整个的硬件加速功能
- 进行大量的内存泄露治理、线程治理
- 降低手机帧率
- 联系手机厂商
多次尝试无果之后,在一次的用户日志对比中发现部分bug存在相同的日志

/proc/pid/mem和/proc/self/task/pid/mem文件监控,如果文件被操作则会退出App,退出方式可能存在问题,导致地图sdk中捕获native崩溃时出现二次崩溃,在将这部分bug处理之后我们的崩溃率降低到0.1%左右,native部分的Crash堆栈没有这部分Crash参杂,堆栈信息更加明确,问题也容易定位一些。
2.2 地图使用
地图是货拉拉应用中必不可少的组件,在用户下单过程中都会用到,贯穿整个主流程。地图部分的crash绝大部分为native,并且有些是特定品牌机型独有的crash。我们将Crash反馈给SDK方,开发人员根据堆栈定位问题,经过多次分析导致Crash的原因一部分是sdk导致,另一部分是我们调用不合理的导致。SDK内部的原因通过升级解决,crash呈收敛趋势。调用不合理部分主要是因为销毁时机不正确导致,我们对各个地图使用场景进行排查修复,在几个版本修复之后总体Crash率降低到了0.05%。
3、OOM治理
OutOfMemoryError是指内存溢出,也是一类难以解决的Crash,通常上报的堆栈信息,用户日志等都没有太多的参考价值,往往内存已经在其他位置增加到内存溢出的临界点,而上报的位置很可能不存在内存问题,而引起内存溢出主要的原因有:内存泄漏,引用大对象,内存抖动,线程使用不合理等。
3.1 内存泄漏
主要是用LeakCanary进行检测,通常Activity的泄漏会显得比较严重,因为它承载了整个页面的控件、数据等,Activity无法回收也会导致这部分对象无法回收。
常见引起Activity泄漏的原因
Handler,Thread等匿名内部类隐式持有外部类导致- 注册的监听器未及时反注册:EventBus,广播
- 单例对象持有
Activity:货拉拉App中有一个页面管理会持有Activity对象,有一部分页面添加之后没有移除造成了大量内存泄漏的场景 - 网络请求,异步任务:由于早期网络部分封装的不好,网络请求没有与页面的生命周期绑定,在弱网或者用户关闭页面较快的情况下会出现内存泄漏。
Context使用Application就可以的时候使用了Activity:例如,Toast,第三方SDK
3.2 线程治理
当线程超过系统设置的上限,也会导致OOM的发生,报错:pthread_create (1040KB stack) failed: Out of memory。通常处理方式如下:
- 对App内部线程池进行统一,对于随意使用的异步任务统一改为使用线程池或者RxJava
- 检查App内Timer,HandlerThread类的合理使用
- 沟通内部其他团队的SDK中增加线程代理,统一使用App端的线程池,避免线程的随意使用
- 分析合理可以替换的线程或者线程池进行插桩替换处理
3.3 大对象处理
通常App中图片都是占用内存的大户,bitmap的管理是内存治理中非常重要的环节。对于这里的处理,我们首先是将图片加载统一使用Glide,再将App中的原生加载图片替换成Glide。
另外,通过MAT工具,筛选、排序大对象,对头部大对象进行优化:
- 原本在同一个SharePreference的数据拆分到多个,使用完毕进行回收。
- 某个类中持有一个非常大的数据,而并不是经常用到,可以放入数据库或者文件中。
3.4 内存抖动
其实针对这部分的优化,我们只是对检测到的、比较严重的、不合理的内存增长进行了优化。通过AndroidStudio的Profiler,我们发现内存出现锯齿状的增长,或者GC频率极高的情况,对着部分不合理的对象分配进行分析和解决。
这里举两个例子:
- a.自定义View的
onDraw方法中创建对象
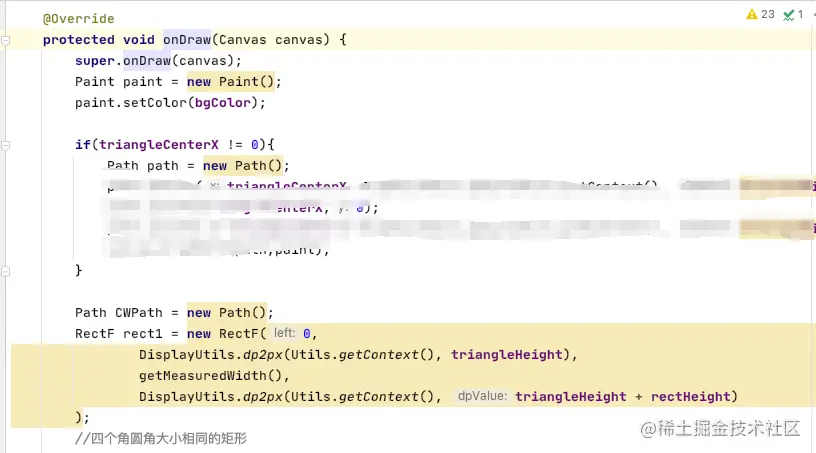
- b.设置监听布局变化,再改变控件的大小,位置等。在改变这个view显示状态时又会出发监听,这里就会不断的执行,造成了内存的疯狂增长,GC频率提高,在一些测试机上十几秒就回进行一次GC。
View.getViewTreeObserver().addOnGlobalLayoutListener(() -> {
//改变view的大小,位置等
int[] view1Location = new int[2];
view1.getLocationOnScreen(view1Location);
int[] view2Location = new int[2];
view2.getLocationOnScreen(view2Location);
});解决的方式主要有两种:
- 1.对象复用:对于onDraw中的使用场景可以将对象作为一个成员变量,其他情况考虑是否可以建立对象池
- 2.增加条件:在达到某种条件下才允许创建对象的逻辑,比如第二个例子中,由于业务原因无法移除监听,我们增加了一些条件,只有少量情况才会执行创建的逻辑。
4.常规Crash
这部分问题通常根据堆栈和用户手机的相关情况很容易定位到问题,不过不能只是修改出问题的那行代码,更不可以随意的进行try catch,需要找到问题的本质,可能这个问题的还会导致其他的一系列问题。比方说:
点击事件的某一行出现了空指针,发现是数据为空导致,数据是从前一个页面的网络接口传递过来,而接口数据为空是因为传入的设备id为空。那么此时我们只在点击事件这里做判空肯定是不够的,需要将设备id为空的原因找到,否则这整个链路都会出现crash或者业务异常。
4.1 空指针NullPointerException
空指针虽然上报的量不大,但却是我们统计到出现次数最多的bug。通常是对象本身没做初始化或者对象被回收的情况下使用该对象导致:
- 代码逻辑分支引起,没走到初始化的位置,却走了相应的调用逻辑。
- 服务端接口返回数据异常,数据库查询数据异常
- 一些
postDelay或者异步回调,回调时也能被回收,可能导致空指针 - 静态变量被回收
通常解决空指针不能直接在代码基础上增加判空处理,应当寻找真正导致对象为空的原因进行规避,常见的解决方式有:
- 做好判空或者使用kotlin语言
- 使用注解
@NonNull和@Nullable - 存在异步任务应当适时停止异步任务或者移除监听回调(例如,页面销毁停止网络请求,移除页面内的
postDelay任务) - 静态变量做好管理,可以本地持久化
4.2 索引越界IndexOutofBoundsException
常见原因:
- 字符串拼接,截取索引不正确,SpannableString 索引设置异常
- ListView,RecyclerView或者ViewPager中数据变化没有通知Adapter数据发生变化
- 多线程情况下使用不安全的集合
解决方式:
- 字符串,SpannableString有关索引操作,应当先判断好字符串长度
- 多线程场景下应当用安全的形式访问集合或者使用线程安全的集合
4.3 系统原因产生的bug
对于这类bug,触发的原因很难查到,我们需要找到堆栈中的关键字、系统版本、机型进行分析,解决方案通常是规避调用或者hook的方式解决。例如下面的bug,关键字“autofill”,版本Android10,对应于Android10的自动填充功能。
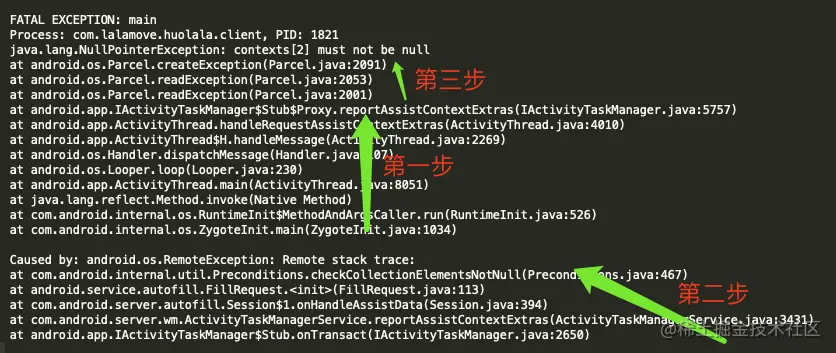
错误名称和堆栈信息
android.os.RemoteException Remote stack trace: at com.android.internal.util.Preconditions.checkCollectionElementsNotNull
简要分析
上面的错误日志涉及到跨进程,分为三段来看会清晰一些。
App进程中ActivityThread的mH接收到Message进行处理handleRequestAssistContextExtras,再调用ActivityTaskManagerService的aidl方法reportAssistContextExtras
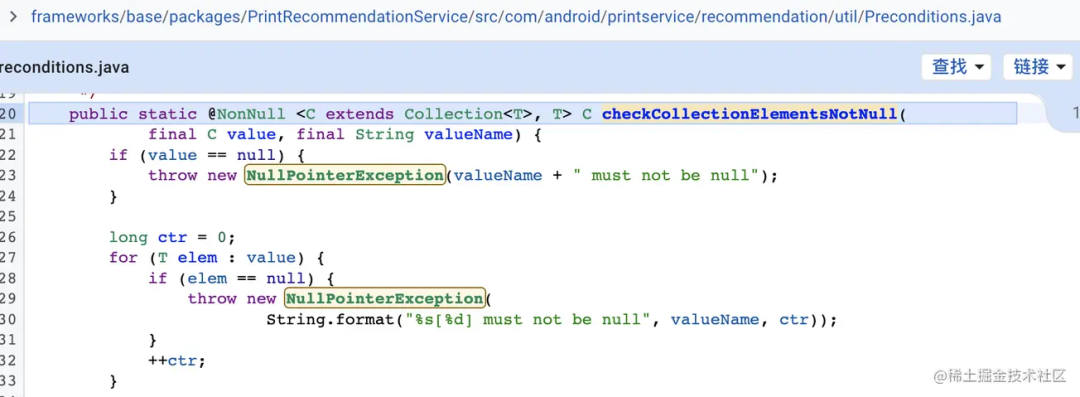
进入到ActivityTaskManagerService.reportAssistContextExtras新建FillRequest的时构造中调用Preconditions.checkCollectionElementsNotNull抛出异常,异常信息发送回我们App进程。Preconditions类异常抛出的位置
调用验证
通过对源码查看,mH中handleRequestAssistContextExtras的调用只有一处,发出这个message的也只有一处。通过hook,确定用户在使用自动填充功能时,会调用这里。
解决方案
- 设置关闭EditText控件的自动填充功能
- Edittext的自动填充引起的Bug_乂星人的博客-CSDN博客_android edittext 自动填充(https://blog.csdn.net/li0978/article/details/105014121)
4.4 其他Crash较多的bug
android.app.RemoteServiceException Context.startForegroundService() did not then call Service.startForeground()
Android8.0启动服务适配问题,App内部和SDK中都有闪退出现,排查App中所有的Service进行适配处理。
android.content.ActivityNotFoundException No Activity found to handle Intent
这个是我们App中js回调安卓跳转页面的方法,由于页面未找到导致的闪退。另外我们发现业务中由
JavaScriptInterface回调安卓端再进行页面的一些操作和发出的Eventbus事件引发了许多莫名其妙的小bug,为此我们将JavaScriptInterface中的回调尽可能都抛回主线程中执行,减少了因子线程操作UI和多线程执行不安全的问题。
com.google.gson.stream.MalformedJsonException
由于后端数据或者本地数据库问题导致数据的解析异常,统一使用了Json解析工具,对异常进行捕获处理
Crash预防和辅助工具
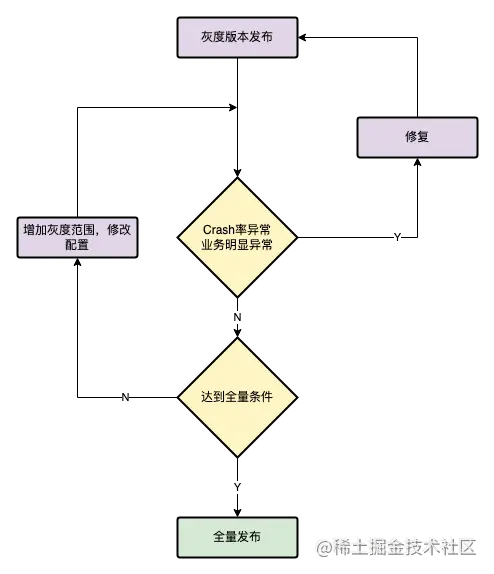
灰度发布
货拉拉的打包发布系统支持持续集成、灰度发布、构建统计、配置下发、强升普升弱升、内测分发等功能,灰度发布支持设置设备ID、数量、百分比、版本号、品牌型号、网络制式、时间、系统版本、业务城市、定位城市等非常灵活。
灰度系统的主要作用:
- 尽早的获得用户的反馈,完善产品功能
- 暴露存在的Crash问题、产品设计问题,及时修改,缩小影响面
货拉拉目前的版本发布会严格按照灰度策略进行逐步放量,在业务需要时会增加对灰度的范围设置例如:城市、品牌型号、版本号等。对于风险较大的需求,我们可能会专门安排一个灰度版本进行发布,最大可能的缩小影响范围。
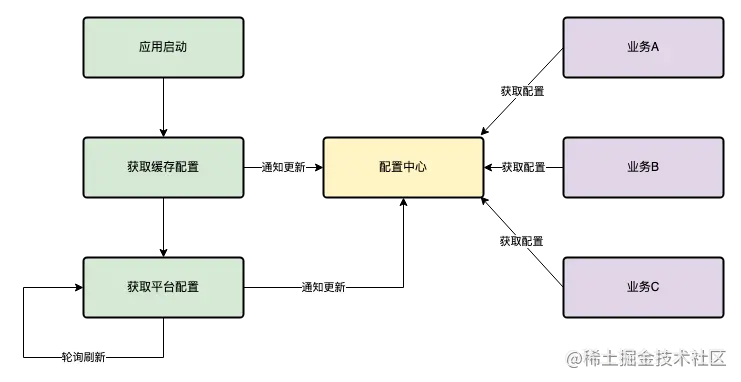
应用配置系统
通过货拉拉的打包发布系统进行配置下发,同时这个配置支持灰度发布,可以像App发布灰度一样下发,对于一些业务可以通过配置下发,控制功能的参数,功能的开关,进行业务降级,修改AB实验等。
代码质量相关措施
建立Code Review 制度
- 保证代码的可读性和风格一致性:便于其他成员对代码的理解,增强维护性
- 发现错误:代码中出现错误很难避免,而这些错误在另外一个人眼中可能很容易被发现
- 发现设计问题:检查代码中的设计不合理,避免后续维护、迭代困难
- 健壮性检查:检查代码的健壮性,是否有潜在的安全问题,性能风险等
- 互相学习:阅读他人的代码也可以从中吸取经验
增加模块Owner
- 模块内代码主要由Owner开发实现,Owner会比较熟悉,并且能够保证代码的一致性。
- Owner可以更好的review其他开发者的代码
业务串讲、思维导图
- 让团队内部成员熟悉业务模块和流程
- 利于团队内沟通、学习
代码扫描:不符合团队规范的代码无法提交
- 保证代码的规范
- 保证代码的一致性
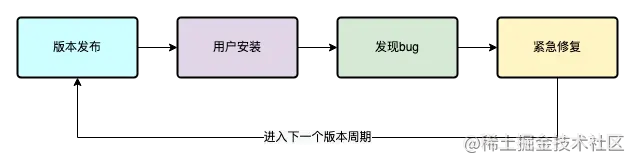
热修复
当App已经大面积发布,而Crash会导致大量用户无法使用、闪退、主流程无法执行等,我们会考虑热修复。如果没有热修复技术,那么我们只能重新发布App版本,甚至需要进行强制升级,会造成极差的用户体验。
货拉拉的日志系统分为两类:
- 实时日志:用户在使用App时产生日志通过上传策略上报到我们平台,支持日志等级筛选、TAG筛选和搜索等常用功能。
- 离线日志:根据用户ID等进行推送用户进行上报,或者用户主动进行上报。
通过日志系统,我们可以根据日志等级、日志时间等得知当前用户的使用场景和操作路径,便于场景复现,是解决Crash的利器之一。
总结
过去的一年我们对App的重点模块进行重构、第三方SDK治理、多次的专项治理,Crash率由5+%降低到了0.02%,稳定性的提升使我们用户反馈问题和用户投诉明显减少,安卓app端相关的投诉反馈由去年4月的12个降低到今年4月的2个,让我们更多地留存用户,保证用户顺利完成订单。我们总结出几点治理原则:
- 举一反三,由点及面,由一个问题引入或者归类出一类问题,进行专项的治理。
- 寻找本质,找到问题的根因而不是一味地try catch,判断绕过。
- 及时解决,Crash问题尽可能在开发和测试环节已经出现应当及时解决,而不是灰度和全量之后再处理。
- 着重预防,将Crash消灭在萌芽阶段,进行代码review、模块划分、技术串讲等措施。
- 控制准入,严格控制模块、sdk、新技术的引入,减少引入风险
Crash治理并非一劳永逸,需要长期治理,建立长效机制。另外一方面,对于新技术和跨平台技术,在业务允许的情况下我们应当需要勇敢的去尝试,利用现有的预防措施做好防范工作,而不会是直接摒弃这些技术的应用。
参考链接:
- 友盟+U-APM 移动应用性能体验报告:Android崩溃率达0.32%,OPPO 、华为、VIVO 崩溃表现良好
- 移动应用性能报告 归档 | 基调听云
- 移动端性能标准值及定义整理 - 掘金