Dalvik虚拟机的运行过程分析
在前面一篇文章中,我们分析了Dalvik虚拟机在Zygote进程中的启动过程。Dalvik虚拟机启动完成之后,也就是在各个子模块初始化完成以及加载了相应的Java核心类库之后,就是可以执行Java代码了。当然,Dalvik虚拟机除了可以执行Java代码之外,还可以执行Native代码,也就是C和C++代码。在本文中,我们就将继续以Zygote进程的启动过程为例,来分析Dalvik虚拟机的运行过程。
从前面Dalvik虚拟机的启动过程分析一文可以知道,Dalvik虚拟机在Zygote进程中启动完成之后,就会获得一个JavaVM实例和一个JNIEnv实例。其中,获得的JavaVM实例就是用来描述Zygote进程的Dalvik虚拟机实例,而获得的JNIEnv实例描述的是Zygote进程的主线程的JNI环境。紧接着,Zygote进程就会通过前面获得的JNIEnv实例的成员函数CallStaticVoidMethod来调用com.android.internal.os.ZygoteInit类的静态成员函数main。这就相当于是将com.android.internal.os.ZygoteInit类的静态成员函数main作为Java代码的入口点。
接下来,我们就从JNIEnv类的成员函数CallStaticVoidMethod开始,分析Dalvik虚拟机的运行过程,如图1所示:
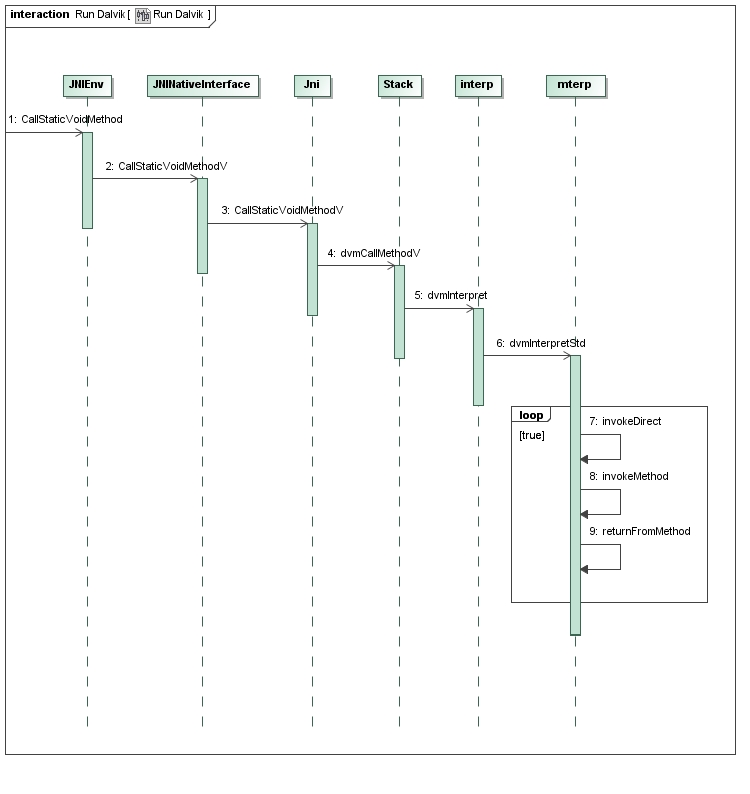
图1 Dalvik虚拟机的运行过程
这个过程可以分为9个步骤,接下来我们就详细分析每一个步骤。
Step 1. JNIEnv.CallStaticVoidMethod
struct _JNIEnv;
......
typedef _JNIEnv JNIEnv;
......
struct _JNIEnv {
/* do not rename this; it does not seem to be entirely opaque */
const struct JNINativeInterface* functions;
......
void CallStaticVoidMethod(jclass clazz, jmethodID methodID, ...)
{
va_list args;
va_start(args, methodID);
functions->CallStaticVoidMethodV(this, clazz, methodID, args);
va_end(args);
}
......
};这个函数定义在文件dalvik/libnativehelper/include/nativehelper/jni.h中。
JNIEnv实际上是一个结构,它有一个成员变量functions,指向的是一个回调函数表。这个回调函数表使用一个JNINativeInterface对象来描述。JNIEnv结构体的成员函数CallStaticVoidMethod的实现很简单,它只是调用该回调函数表中的CallStaticVoidMethodV函数来执行参数clazz和methodID所描述的Java代码。
Step 2. JNINativeInterface.CallStaticVoidMethodV
struct JNINativeInterface {
......
void (*CallStaticVoidMethodV)(JNIEnv*, jclass, jmethodID, va_list);
......
};这个函数定义在文件dalvik/libnativehelper/include/nativehelper/jni.h中。
JNINativeInterface是一个结构体,它的成员变量CallStaticVoidMethodV是一个函数指针。
从前面Dalvik虚拟机的启动过程分析一文可以知道,Dalvik虚拟机在内部为Zygote进程的主线程所创建的Java环境是用一个JNIEnvExt结构体来描述的,并且这个JNIEnvExt结构体会被强制转换成一个JNIEnv结构体返回给Zygote进程。
JNIEnvExt结构体定义在文件dalvik/vm/JniInternal.h中,如下所示:
typedef struct JNIEnvExt {
const struct JNINativeInterface* funcTable; /* must be first */
......
} JNIEnvExt;从这里就可以看出,虽然结构体JNIEnvExt和JNIEnv之间没有继承关系,但是它们的第一个成员变量的类型是一致的,也就是它们都是指向一个类型为JNINativeInterface的回调函数表,因此,Dalvik虚拟机可以将一个JNIEnvExt结构体强制转换成一个JNIEnv结构体返回给Zygote进程,这时候我们通过JNIEnv结构体来访问其成员变量functions所描述的回调函数表时,实际访问到的是对应的JNIEnvExt结构体的成员变量funcTable所描述的回调函数表。
为什么不直接让JNIEnvExt结构体从JNIEnv结构体继承下来呢?这样把一个JNIEnvExt结构体转换为一个JNIEnv结构体就是相当直观的。然而,Dalvik虚拟机的源代码并一定是要以C++语言的形式来编译的,它也可以以C语言的形式来编译的。由于C语言没有继承的概念,因此,为了使得Dalvik虚拟机的源代码能同时兼容C++和C,这里就使用了一个Trick:只要两个结构体的内存布局相同,它们就可以相互转换访问。当然,这并不要求两个结构体的内存布局完全相同,但是至少开始部分要求是相同的。在这种情况下,将一个结构体强制转换成另外一个结构体之外,只要不去访问内存布局不一致的地方,就没有问题。在Android系统的Native代码中,我们可以常常看到这种Trick。
接下来,我们需要搞清楚的是JNIEnvExt结构体的成员变量funcTable指向的回调函数表是什么。同样是从前面Dalvik虚拟机的启动过程分析一文可以知道,Dalvik虚拟机在创建一个JNIEnvExt结构体的时候,会将它的成员变量funcTable指向全局变量gNativeInterface所描述的一个回调函数表。
gNativeInterface定义在文件dalvik/vm/Jni.c中,如下所示:
static const struct JNINativeInterface gNativeInterface = {
......
CallStaticVoidMethodV,
......
};在这个回调函数表中,名称为CallStaticVoidMethodV的函数指针指向的是一个同名函数CallStaticVoidMethodV。
函数CallStaticVoidMethodV同样是定义在文件dalvik/vm/Jni.c中,不过它是通过宏CALL_STATIC来定义的,如下所示:
#define CALL_STATIC(_ctype, _jname, _retfail, _retok, _isref) \
...... \
static _ctype CallStatic##_jname##MethodV(JNIEnv* env, jclass jclazz, \
jmethodID methodID, va_list args) \
{ \
UNUSED_PARAMETER(jclazz); \
JNI_ENTER(); \
JValue result; \
dvmCallMethodV(_self, (Method*)methodID, NULL, true, &result, args);\
if (_isref && !dvmCheckException(_self)) \
result.l = addLocalReference(env, result.l); \
JNI_EXIT(); \
return _retok; \
}
...... \
CALL_STATIC(void, Void, , , false);通过上面的分析就可以知道,在JNIEnvExt结构体的成员变量funcTable所描述的回调函数表中,名称为CallStaticVoidMethodV的函数指针指向的是一个同名函数CallStaticVoidMethodV。这就是说,我们通过JNIEnv结构体的成员变量functions所访问到的名称为CallStaticVoidMethodV函数指针实际指向的是函数CallStaticVoidMethodV。
Step 3. CallStaticVoidMethodV
我们将上面的CALL_STATIC宏开之后,就可以得到函数CallStaticVoidMethodV的实现,如下所示:
static _ctype CallStaticVoidMethodV(JNIEnv* env, jclass jclazz,
jmethodID methodID, va_list args)
{
UNUSED_PARAMETER(jclazz);
JNI_ENTER();
JValue result;
dvmCallMethodV(_self, (Method*)methodID, NULL, true, &result, args);
if (_isref && !dvmCheckException(_self))
result.l = addLocalReference(env, result.l);
JNI_EXIT();
return _retok;
}函数CallStaticVoidMethodV的实现很简单,它通过调用另外一个函数dvmCallMethodV来执行由参数jclazz和methodID所描述的Java代码,因此,接下来我们就继续分析函数dvmCallMethodV的实现。
Step 4. dvmCallMethodV
void dvmCallMethodV(Thread* self, const Method* method, Object* obj,
bool fromJni, JValue* pResult, va_list args)
{
......
if (dvmIsNativeMethod(method)) {
TRACE_METHOD_ENTER(self, method);
/*
* Because we leave no space for local variables, "curFrame" points
* directly at the method arguments.
*/
(*method->nativeFunc)(self->curFrame, pResult, method, self);
TRACE_METHOD_EXIT(self, method);
} else {
dvmInterpret(self, method, pResult);
}
......
}这个函数定义在文件dalvik/vm/interp/Stack.c中。
函数dvmCallMethodV首先检查参数method描述的函数是否是一个JNI方法。如果是的话,那么它所指向的一个Method对象的成员变量nativeFunc就指向该JNI方法的地址,因此就可以直接对它进行调用。否则的话,就说明参数method描述的是一个Java函数,这时候就需要继续调用函数dvmInterpret来执行它的代码。
Step 5. dvmInterpret
void dvmInterpret(Thread* self, const Method* method, JValue* pResult)
{
InterpState interpState;
......
/*
* Initialize working state.
*
* No need to initialize "retval".
*/
interpState.method = method;
interpState.fp = (u4*) self->curFrame;
interpState.pc = method->insns;
......
typedef bool (*Interpreter)(Thread*, InterpState*);
Interpreter stdInterp;
if (gDvm.executionMode == kExecutionModeInterpFast)
stdInterp = dvmMterpStd;
#if defined(WITH_JIT)
else if (gDvm.executionMode == kExecutionModeJit)
/* If profiling overhead can be kept low enough, we can use a profiling
* mterp fast for both Jit and "fast" modes. If overhead is too high,
* create a specialized profiling interpreter.
*/
stdInterp = dvmMterpStd;
#endif
else
stdInterp = dvmInterpretStd;
change = true;
while (change) {
switch (interpState.nextMode) {
case INTERP_STD:
LOGVV("threadid=%d: interp STD\n", self->threadId);
change = (*stdInterp)(self, &interpState);
break;
case INTERP_DBG:
LOGVV("threadid=%d: interp DBG\n", self->threadId);
change = dvmInterpretDbg(self, &interpState);
break;
default:
dvmAbort();
}
}
*pResult = interpState.retval;
......
}这个函数定义在文件dalvik/vm/interp/Interp.c中。
在前面Dalvik虚拟机的启动过程分析一文中提到,Dalvik虚拟机支持三种执行模式:portable、fast和jit,它们分别使用kExecutionModeInterpPortable、kExecutionModeInterpFast和kExecutionModeJit三个常量来表示。Dalvik虚拟机在启动的时候,会通过解析命令行参数获得所要执行的模式,并且记录在全局变量gDvm所指向的一个DvmGlobals结构体的成员变量executionMode中。
kExecutionModeInterpPortable表示Dalvik虚拟机以可移植模式来解释Java代码,也就是这种执行模式可以应用在任何一个平台上,例如,可以同时在arm和x86各个平台上执行。这时候使用函数dvmInterpretStd来作为Java代码的执行函数。
kExecutionModeInterpFast表示Dalvik虚拟机以快速模式来解释Java代码。以这种模式执行的Dalvik虚拟机是针对某一个特定的目标平台进行过优化的,因此,它可以更快速地对Java代码进行解释以及执行。这时候使用函数dvmMterpStd来作为Java代码的执行函数。
kExecutionModeJit表示Dalvik虚拟机支持JIT模式来执行Java代码,也就是先将Java代码动态编译成Native代码再执行。这时候使用函数dvmMterpStd来作为Java代码的执行函数。
我们可以将函数dvmInterpretStd和dvmMterpStd理解为Dalvik虚拟机的解释器入口点。很显然,解释器是虚拟机的核心模块,它的性能关乎到整个虚拟机的性能。Dalvik虚拟机的解释器开始的时候都是以C语言来实现的,后来为了提到性能,就改成以汇编语言来实现。注意,无论Dalvik虚拟机的解释器是以C语言来实现,还是以汇编语言来实现,它们的源代码都是以一种模块化方法来自动生成的,并且能够根据某一个特定的平台进行优化。
所谓模块化代码生成方法,就是说将解释器的实现划分成若干个模块,每一个模块都对应有一系列的输入文件(本身也是源代码文件),最后通过工具(一个Python脚本)将这些输入文件组装起来形成一个C语言文件或者汇编语言文件。这个最终得到的C语言文件或者汇编语言文件就是Dalvik虚拟机的解释器的实现文件。有了这种模块化代码生成方法之后,为某一个特定的平台生成优化过的解释器就是相当容易的:我们只需要为该平台的Dalvik虚拟机解释器的相关模块提供一个特殊版本的输入文件即可。也就是说,我们需要为每一个支持的平台提供一个配置文件,该配置文件描述了该平台的Dalvik虚拟机解释器的各个模块所要使用的输入文件。这种模块化代码生成方法不仅能避免手动编写解释器容易出错的问题,还能方便快速地将Dalvik虚拟机从一个平台移植到另外一个平台。
采取了模块化方法来生成Dalvik虚拟机解释器的源代码之后,Dalvik虚拟机解释器的源代码整体上就划分成两部分:第一部分相当于一个Wrapper,定义在dalvik/vm/interp目录中;第二部分对应于具体的实现,定义在dalvik/vm/mterp目录中。
在dalvik/vm/mterp目录中,又定义了一系列的输入文件,以及各个平台所使用的配置文件。有了这些输入文件和配置文件之后,就可以通过一个Python脚本来为每一个平台生成一个Dalvik虚拟机解释器的输出文件,并且保存在dalvik/vm/mterp/out目录中。由于针对各个平台生成的输出文件是一个汇编语言文件,即一个 *.S文件,为了方便理解它的逻辑,每一个汇编语言文件都对应有一个C语言文件。
虽然Dalvik虚拟机解释器针对每一个平台都有一个优化的版本,但是同时也会提供一个通用的版本,也就是一个可移植版本。该可移植版本的解释器源文件只有C语言实现版本,定义在文件dalvik/vm/mterp/out/InterpC-portstd.c中。在本文中,我们只考虑可移植版本的Dalvik虚拟机解释器的实现,也就是只考虑执行模式为kExecutionModeInterpPortable的Dalvik虚拟机的运行机制。从前面的分析可以知道,该可移植版本的Dalvik虚拟机解释器的入口函数为dvmInterpretStd。
函数dvmInterpretStd在执行之前,需要知道解释器的当前状态,也就是它所要执行的Java函数及其指令入口,以及当前要执行的线程的堆栈。这些信息都用一个InterpState结构体来描述。其中,这个InterpState结构体的成员变量method描述的是要执行的Java函数,成员变量fp描述的是要执行的线程的当前堆栈帧,成员变量pc描述的是要执行的Java函数的入口点。
在函数dvmInterpret中,参数self描述的是当前用来执行Java代码的线程,而参数method描述的是要执行的Java函数。通过这两个参数我们就可以初始化上述的InterpState结构体。Dalvik虚拟机解释器除了可以在正常模式执行之外,还可以在调试模式执行,即决于上述初始化后得到的InterpState结构体的成员变量nextMode的值。
在本文中,我们只考虑正常模式执行的Dalvik虚拟机解释器的实现,也就是我们只分析函数dvmInterpretStd的实现。函数dvmInterpretStd解释完成指定的Java函数之后,获得的返回值就保存在上述InterpState结构体的成员变量retval中。
Step 6. dvmInterpretStd
#define INTERP_FUNC_NAME dvmInterpretStd
......
bool INTERP_FUNC_NAME(Thread* self, InterpState* interpState)
{
......
DvmDex* methodClassDex; // curMethod->clazz->pDvmDex
JValue retval;
/* core state */
const Method* curMethod; // method we're interpreting
const u2* pc; // program counter
u4* fp; // frame pointer
u2 inst; // current instruction
......
/* copy state in */
curMethod = interpState->method;
pc = interpState->pc;
fp = interpState->fp;
retval = interpState->retval; /* only need for kInterpEntryReturn? */
methodClassDex = curMethod->clazz->pDvmDex;
......
while (1) {
......
/* fetch the next 16 bits from the instruction stream */
inst = FETCH(0);
switch (INST_INST(inst)) {
......
HANDLE_OPCODE(OP_INVOKE_DIRECT /*vB, {vD, vE, vF, vG, vA}, meth@CCCC*/)
GOTO_invoke(invokeDirect, false);
OP_END
......
HANDLE_OPCODE(OP_RETURN /*vAA*/)
vsrc1 = INST_AA(inst);
......
retval.i = GET_REGISTER(vsrc1);
GOTO_returnFromMethod();
OP_END
......
}
}
......
/* export state changes */
interpState->method = curMethod;
interpState->pc = pc;
interpState->fp = fp;
/* debugTrackedRefStart doesn't change */
interpState->retval = retval; /* need for _entryPoint=ret */
interpState->nextMode =
(INTERP_TYPE == INTERP_STD) ? INTERP_DBG : INTERP_STD;
......
return true;
}这个函数定义在文件dalvik/vm/mterp/out/InterpC-portstd.c中。
函数dvmInterpretStd对应的是Dalvik虚拟机解释器的可移植版本实现,它大概可以划分三个逻辑块:
1. 初始化当前要解释的类(methodClassDex)及其成员变量函数(curMethod)、栈帧(fp)、程序计数器(pc)和返回值(retval),这些值都可以从参数interpState获得。
2. 在一个无限while循环中,通过FETCH宏依次获得当前程序计数器(pc)中的指令inst,并且通过宏INST_INST获得指令inst的类型,最后就switch到对应的分支去解释指令inst。
宏FETCH和INST_INST的定义在文件dalvik/vm/mterp/out/InterpC-portstd.c中,如下所示:
/*
* Get 16 bits from the specified offset of the program counter. We always
* want to load 16 bits at a time from the instruction stream -- it's more
* efficient than 8 and won't have the alignment problems that 32 might.
*
* Assumes existence of "const u2* pc".
*/
#define FETCH(_offset) (pc[(_offset)])
/*
* Extract instruction byte from 16-bit fetch (_inst is a u2).
*/
#define INST_INST(_inst) ((_inst) & 0xff)从这里我们就可以看出,pc实际上指向的就是当前要执行的Java函数的方法区,也就是一个指令流。这个指令流包含了很多指令,需要通过一个while循环来依次对它们进行解释,直到碰到一个return指令为止。这就是Dalvik虚拟机解释器的核心功能。例如,假设当前遇到的是一条OP_INVOKE_DIRECT指令,它表示要调用当前类的一个非静态非虚成员函数,这时候就会通过宏GOTO_invoke跳到invokeDirect这个分支去。
宏HANDLE_OPCODE和GOTO_invoke定义在文件dalvik/vm/mterp/out/InterpC-portstd.c中,如下所示:
# define HANDLE_OPCODE(_op) case _op:
#define GOTO_invoke(_target, _methodCallRange) \
do { \
methodCallRange = _methodCallRange; \
goto _target; \
} while(false)分支invokeDirect是通过另外一个宏GOTO_TARGET来定义的,在接下来的Step 7中我们再分析。
当遇到return指令时,例如,遇到OP_RETURN指令时,首先会通过宏INST_AA和GET_REGISTER来获得函数的返回值,接着再通过宏GOTO_returnFromMethod跳到returnFromMethod分支去结束整个while循环。
注意,当指令inst是return指令时,它的执行结果即为当要正在解释的Java函数返回值。通过宏INST_AA可以知道一条指令的执行结果保存在哪个寄存器中,而通过宏GET_REGISTER可以获得该寄存器的值。
宏INST_AA和GET_REGISTER定义在文件dalvik/vm/mterp/out/InterpC-portstd.c中,如下所示:
/*
* Get the 8-bit "vAA" 8-bit register index from the instruction word.
* (_inst is u2)
*/
#define INST_AA(_inst) ((_inst) >> 8)
# define GET_REGISTER(_idx) \
( (_idx) < curMethod->registersSize ? \
(fp[(_idx)]) : (assert(!"bad reg"),1969) )宏GOTO_returnFromMethod定义在文件dalvik/vm/mterp/out/InterpC-portstd.c中,如下所示:
#define GOTO_returnFromMethod() goto returnFromMethod;分支returnFromMethod和invokeDirect一样,都是通过宏GOTO_TARGET来定义的,在接下来的Step 9中我们再分析。
接下来,我们就以分支invokeDirect为例来说明Dalvik虚拟机解释一条指令的过程,接着再以分支returnFromMethod的实现来说明Dalvik虚拟机解释器从一个函数返回的过程。
Step 7. invokeDirect
GOTO_TARGET(invokeDirect, bool methodCallRange)
{
......
vsrc1 = INST_AA(inst); /* AA (count) or BA (count + arg 5) */
ref = FETCH(1); /* method ref */
vdst = FETCH(2); /* 4 regs -or- first reg */
EXPORT_PC();
......
methodToCall = dvmDexGetResolvedMethod(methodClassDex, ref);
......
GOTO_invokeMethod(methodCallRange, methodToCall, vsrc1, vdst);
}
GOTO_TARGET_END根据Step 6的分析,invokeDirect是一个分支,它通过宏GOTO_TARGET定义在文件dalvik/vm/mterp/out/InterpC-portstd.c中。
分支invokeDirect用来调用当前类(methodClassDex)的非静态非虚成员函数。这个被调用的成员函数的引用可以通过宏FETCH(1)来获取。知道了被调用的成员函数的引用之后,就可以通过调用函数dvmDexGetResolvedMethod来获得对应的成员函数(methodToCall)。
此外,宏FETCH(2)用来获得要传递给成员函数(methodToCall)的参数列表,而宏EXPORT_PC是用来记录当前程序计数器pc的位置的,用来帮助实现精确GC。关于精确GC(Extra/Precise GC),可以参考前面Dalvik虚拟机的启动过程分析一文的介绍。
宏GOTO_invokeMethod定义在文件dalvik/vm/mterp/out/InterpC-portstd.c中,如下所示:
#define GOTO_invokeMethod(_methodCallRange, _methodToCall, _vsrc1, _vdst) goto invokeMethod;它表示要跳到分支invokeMethod去解释当前类的成员函数_methodToCall,接下来我们就继续分析它的实现。
Step 8. invokeMethod
GOTO_TARGET(invokeMethod, bool methodCallRange, const Method* _methodToCall,
u2 count, u2 regs)
{
STUB_HACK(vsrc1 = count; vdst = regs; methodToCall = _methodToCall;);
StackSaveArea* newSaveArea;
u4* newFp;
......
newFp = (u4*) SAVEAREA_FROM_FP(fp) - methodToCall->registersSize;
newSaveArea = SAVEAREA_FROM_FP(newFp);
......
newSaveArea->prevFrame = fp;
newSaveArea->savedPc = pc;
......
if (!dvmIsNativeMethod(methodToCall)) {
/*
* "Call" interpreted code. Reposition the PC, update the
* frame pointer and other local state, and continue.
*/
curMethod = methodToCall;
methodClassDex = curMethod->clazz->pDvmDex;
pc = methodToCall->insns;
fp = self->curFrame = newFp;
......
FINISH(0); // jump to method start
} else {
/* set this up for JNI locals, even if not a JNI native */
......
self->curFrame = newFp;
......
/*
* Jump through native call bridge. Because we leave no
* space for locals on native calls, "newFp" points directly
* to the method arguments.
*/
(*methodToCall->nativeFunc)(newFp, &retval, methodToCall, self);
......
if (true /*invokeInstr >= OP_INVOKE_VIRTUAL &&
invokeInstr <= OP_INVOKE_INTERFACE*/)
{
FINISH(3);
}
......
}
......
}
GOTO_TARGET_END分支invokeMethod通过宏GOTO_TARGET定义在文件dalvik/vm/mterp/out/InterpC-portstd.c中。
分支invokeMethod首先是为当前要解释的成员函数methodToCall创建一个新的栈帧newFp,接着再通过调用函数dvmIsNativeMethod来判断成员函数methodToCall是否是一个JNI方法。
在新创建的栈帧newFp中,分别在其成员变量prevFrame和savedPc中保存了当前栈帧fp和当前程序计数器pc的值,这样使得在调用完成员函数methodToCall之后,可以返回到当前正在执行的成员函数的下一条指令中去,以及恢复当前线程的栈帧。
如果成员函数methodToCall不是一个JNI方法,那么就说明接下来仍然是要通过Dalvik虚拟机解释器来执行它。不过这时候需要将当前线程激活的栈帧fp设置为newFp,以及将程序计数器pc指向成员函数methodToCall的方法区。最后通过宏FINISH(0)来跳出当前分支,实际上就是跳出前面Step 6的switch语句,然后重复执行while循环语句。此时传递给宏FINISH的参数为0,表示不需要调整程序计数器pc的值,因为前面已经调整过了。
如果成员函数methodToCall是一个JNI方法,那么该JNI方法的地址就保存在methodToCall->nativeFunc中,这时候只需要直接对它进行调用即可。调用JNI方法结束之后,需要通过宏FINISH(3)调整程序计数器pc的值,以及跳出当前分支,以及可以回到前面Step 6的while循环去执行下一条指令。此时传递给宏FINISH的参数为3,表示要将程序计数器pc的值增加3,正好是跳过当前执行的指令。
宏FINISH定义在文件dalvik/vm/mterp/out/InterpC-portstd.c中,如下所示:
# define ADJUST_PC(_offset) do { \
pc += _offset; \
EXPORT_EXTRA_PC(); \
} while (false)
#endif
# define FINISH(_offset) { ADJUST_PC(_offset); break; }注意,在宏ADJUST_PC中,又会通过宏EXPORT_EXTRA_PC来记录当前程序计数器pc的值,也是用来帮助实现精确GC的。
这一步执行完成之后,就回到前面的Step 6的while循环中,继续执行下一条指令,直到遇到reutrn指令为止。接下来我们就以OP_RETURN指令为例,来说明Java函数的返回操作,也就分析分支returnFromMethod的实现。
Step 9. returnFromMethod
GOTO_TARGET(returnFromMethod)
{
StackSaveArea* saveArea;
......
saveArea = SAVEAREA_FROM_FP(fp);
......
fp = saveArea->prevFrame;
......
/* update thread FP, and reset local variables */
self->curFrame = fp;
curMethod = SAVEAREA_FROM_FP(fp)->method;
//methodClass = curMethod->clazz;
methodClassDex = curMethod->clazz->pDvmDex;
pc = saveArea->savedPc;
......
if (true /*invokeInstr >= OP_INVOKE_VIRTUAL &&
invokeInstr <= OP_INVOKE_INTERFACE*/)
{
FINISH(3);
}
......
}
GOTO_TARGET_END分支returnFromMethod通过宏GOTO_TARGET定义在文件dalvik/vm/mterp/out/InterpC-portstd.c中。
分支returnFromMethod的实现比较简单,它主要就是恢复上一个执行的成员函数的栈帧,以及该成员函数下一条要执行的指令。由于在前面的Step 8中,我们在当前栈帧中保存了上一个执行的成员函数的下一条要执行的指令及其栈帧,因此,这里对它们进行恢复是很直觉的。
不过有一点需要注意的是,前面的Step 8保存的是当前正在执行的成员函数的程序计算器,现在由于该程序计算器所指向的指令已经执行完成了,因此,我们需要继续调整从当前栈帧中恢复回来的指令值,使得它指向的是上一个执行的成员函数的下一条要执行的指令的值,这是通过宏FINISH(3)来完成的。
至此,我们就分析完成Dalvik虚拟机解释器的执行过程了,这个过程也就相当于是Dalvik虚拟机的运行过程,也就是说,Step 7到Step 9实际上是会不断地重复执行,直至进程退出为止的。以Zygote进程为例,Dalvik虚拟机解释器就是以com.android.internal.os.ZygoteInit类的静态成员函数main为入口点执行,然后在一个Socket上进行循环,用来等待和处理ActivityManagerService服务向它发送创建新应用程序进程的请求,直至系统退出为止。又以Android应用程序进程为例,Dalvik虚拟机解释器就是以android.app.ActivityThread类的静态成员函数main为入口点执行,然后在一消息队列上进行循环,用来等待和处理主线程的消息,直到应用程序退出为止。
当然,Dalvik虚拟机在运行的过程中,除了解释执行之外,还可能会进行JIT。JIT的目的就是将Java代码即时编译成Native代码之后再直接执行,这样对于经常运行的代码来说,可以提高性能。由于在将Java代码即时编译成Native代码的过程中,可以进一步利用运行时信息来进行激进优化,因此,JIT获得的Native代码比AOT获得的Native可能会更优化。关于JIT的实现,可以参考Hello, JIT World: The Joy of Simple JITs一文。
此外,从Step 4和Step 8可以知道,Dalvik虚拟机在运行的过程中,除了需要执行Java函数之外,还可能需要执行Native函数,这些Native函数也就是我们平时所说的JNI方法。在接下来的一篇文章中,我们就将分析这些JNI方法注册到Dalvik虚拟机里面去的,敬请关注!