Chromium硬件加速渲染机制基础知识简要介绍和学习计划
Chromium支持硬件加速渲染网页,即使用GPU渲染网页。在多进程架构下,Browser、Render和Plugin进程的GPU命令不是在本进程中执行的,而是转发给GPU进程执行。这是因为GPU命令是硬件相关操作,不同平台的实现不一样,从而导致不稳定,而将不稳定操作放在独立进程中执行可以保护主进程的稳定性。本文对Chromium硬件加速渲染机制的基础知识进行简要介绍和制定学习计划。
GPU进程将所有的GPU命令都放在一个GPU线程中执行。如果说GPU线程是一个Server端,那么它的Client端就是Render进程、Browser进程和Plugin进程。GPU线程需要区分每一个Client端所转发过来的GPU命令,避免它们之间产生相互影响。为此,GPU线程需要为每一个Client端创建一个OpenGL上下文,如图1所示:
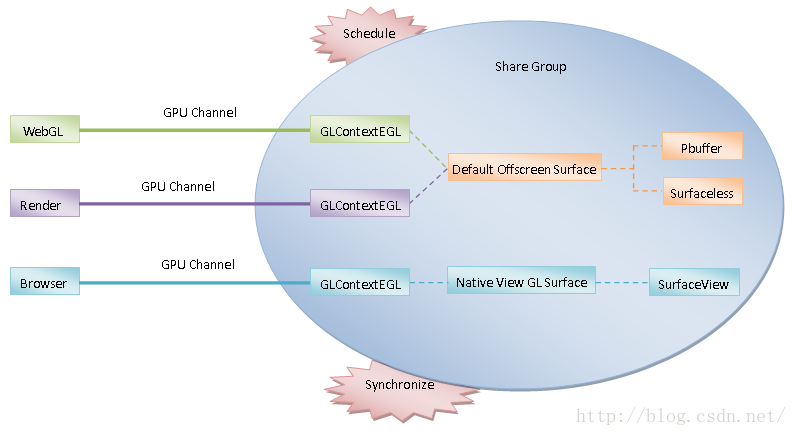
图1 GPU线程中的OpenGL上下文
在GPU线程中,每一个OpenGL上下文都用一个GLContextEGL对象描述。在图1中,我们列出了GPU线程的三种Client端,分别是WebGL、Render和Browser。其中,WebGL是HTML5支持的3D渲染接口,Render是用来渲染网页的,而Browser是用来渲染整个浏览器窗口UI的。 WebGL和Render这两种GPU线程Client端运行在Render进程中,而Browser这种GPU线程Client端运行在Browser进程中,它们均是通过GPU Channel与GPU线程进行通信,也就是它们在OpenGL线程都有一个对应的OpenGL上下文。关于GPU线程以及GPU Channel,可以参考前面Chromium的GPU进程启动过程分析一文。为了方便描述,我们将上述的三种GPU线程Client端称为WebGL端、Render端和Browser端。
每一个OpenGL上下文都需要设置一个绘图表面。其中,WebGL端和Render端的OpenGL上下文设置的是同一个绘图表面,并且该绘图表面是一个离屏绘图表面,该离屏绘图表面是GPU线程的默认离屏绘图表面。在某些平台上,OpenGL上下文不需要设置一个真的绘图表面,这时候GPU线程的默认绘图表面通过Surfaceless对象来描述。在需要给OpenGL上下文设置一个真的绘图表面的平台中,GPU线程的默认离屏绘图表面使用Pbuffer对象来描述。
与WebGL端和Render端相比,Browser端的OpenGL上下文设置的绘图表面是一个屏幕绘图表面,也就是一个可以显示在屏幕上的用户可见的绘图表面,这意味着这个绘图表面是与平台相关的,例如在Android平台上,这个绘图表面通过SurfaceView来描述。
Chromium之所以将WebGL端和Render端的OpenGL上下文的绘图表面设置为离屏绘图表面,而将Browser端的OpenGL上下文的绘图表面设置为屏幕绘图表面,是因为前两者渲染出来的UI最终是合成在后者的绘图表面上并且显示在屏幕中的。这一点我们后面再分析。
每一个GPU命令都必须在一个OpenGL上下文中执行。这意味着,从WebGL端、Render端和Browser端发送过来的GPU命令要分别在它们对应的OpenGL上下文中执行。又由于所有的GPU命令都是在同一个GPU线程中执行的,并且同一时刻GPU线程只能有一个OpenGL上下文,因此GPU线程必须在接收到一个GPU命令时,切换至合适的OpenGL上下文中去。切换OpenGL上下文的操作在Chromium中称为OpenGL上下文调度(Schedule)。
此外,由于WebGL端和Render端渲染出来的UI最终要交给Browser端合成和显示在屏幕中,因此这涉及到不同OpenGL上下文之间的同步(Synchronize)。也就是说,Browser端在合成WebGL端和Render端的UI时,要确保不会出现资源竞争。
在Chromium中,GPU线程只存在一个Browser端,但是有可能存在若干个Render端和WebGL端。例如,当我们打开多个网页时,就会存在多个Render端,而每一个网页又可能包含有若干个使用WebGL接口渲染的canvas标签,也就是存在若干个WebGL端。如果我们为每一个WebGL端和每一个Render端都创建一个OpenGL上下文,那么就会导致GPU线程同时创建很多OpenGL上下文。在有些平台上,可以同时创建的OpenGL上下文的个数是有限制的。为了解决这个问题,GPU线程为WebGL端、Render端和Browser端创建的是虚拟OpenGL上下文,如图2所示:

图2 GPU线程中的虚拟OpenGL上下文
虚拟OpenGL上下文使用GLContextVirtual对象描述,它们的个数不受平台限制,因此可以创建无数个。不过,每一个虚拟OpenGL上下文还是需要关联一个真实OpenGL上下文的。
WebGL端、Render端和Browser端的虚拟OpenGL上下文关联的真实OpenGL上下文是相同的。这个真实OpenGL上下文设置的绘图表面就是前面描述的GPU线程的默认离屏绘图表面。不过,Browser端的虚拟OpenGL上下文还关联有一个屏幕绘图表面,在Android平台上,这个屏幕绘图表面就是一个SurfaceView。
当GPU线程从一个虚拟OpenGL上下文切换至另一个虚拟OpenGL上下文时,需要执行以下两个步骤:
1. 找到另一个虚拟OpenGL上下文关联的真实OpenGL上下文,并且将找到的真实OpenGL上下文作为GPU线程的当前OpenGL上下文;
2. 将前面找到的真实OpenGL上下文的绘图表面设置为另一个虚拟OpenGL上下文关联的绘图表面。
从上面两个步骤可以看出,虽然WebGL端、Render端和Browser端的虚拟OpenGL上下文关联的真实OpenGL上下文是相同的,但是当该真实OpenGL上下文在不同时刻设置的绘图表面却是不一样的。其中,当该真实OpenGL上下文是切换给WebGL端和Render端使用时,设置的绘图表面是GPU线程的默认离屏绘图表面,而当该真实OpenGL上下文是切换给Browser端使用时,设置的绘图表面是一个屏幕绘图表面,也就是一个SurfaceView。
不管WebGL端、Render端和Browser端使用的是真实OpenGL上下文,还是虚拟OpenGL上下文,它们都是在同一个OpenGL上下文共享组(Share Group)中的。正是因为这些OpenGL上下文都在同一个共享组中,Browser端的OpenGL上下文才可以访问WebGL端和Render端的OpenGL上下文中的资源,从而可以将它们合成并且显示在屏幕上。在合成过程中涉及到的资源同步过程如图3所示:
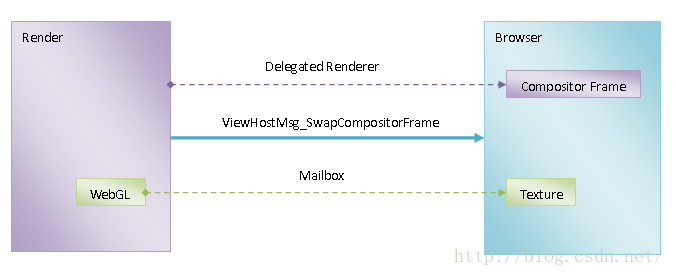
图3 不同OpenGL上下文之间的资源同步过程
我们假设网页中包含了一个canvas元素,并且这个canvas元素是通过WebGL接口来渲染的。在Chromium中,一个网页被组织为一棵Layer树,其中网页包含的canvas元素就作为一个单独的Layer存在。这个Layer通过WebGL接口渲染在一个OpenGL纹理(Texture)中,这个Texture最终通过一种称为Mailbox的机制从Render端传递给Browser端合成。
当网页内容发生变化时,Render端使用一种称为委托渲染器(Delegated Renderer)的机制来渲染网页的UI。Delegated Renderer并没有直接在Render端中渲染网页UI,它仅仅是收集和整理渲染网页UI所需要的信息和资源。Delegated Renderer最后会将收集和整理好的信息和资源封装在一个Compositor Frame中。一个Compositor Frame描述的就是一个网页渲染帧。注意,如果网页包含了使用WebGL接口渲染的canvas元素,那么上述Compositor Frame还会包含有这些canvas元素所对应的Texture的信息。
Delegated Renderer收集和整理渲染网页UI所需要的信息和资源完毕,就会向Browser端发送一个类型为ViewHostMsg_SwapCompositorFrame的IPC消息,以便可以将得到的Compositor Frame发送给Browser端进行合成。
在Android 5.0之前,Render端是将网页UI渲染在一个Texture中的,然后再通过Mailbox机制将该Texture从Render端传递给Browser端进行合成。但是从Android 5.0开始,Render端就不再采用这种方式,而是采用上述的Delegated Renderer方式。从上面的分析可以知道,Delegated Renderer直接将渲染网页UI所需要的信息和资源传递给Browser端进行合成,这样可以减少一个中间环节,就是将网页UI渲染在一个Texture中的环节,因而就可以提高渲染效率。
在上述的网页合成过程中,Render端将一个Compositor Frame发送给Browser端之后,不会等待Browser端处理完成这个Compositor Frame之后再去处理下一个Compositor Frame,因为这样效率就太低了,而是同时处理下一个Compositor Frame,但是这样做会有一个资源同步问题。Render端发送给Browser端的Compositor Frame所引用的资源是在Render端的OpenGL上下文中创建的,但是这些资源同时又会被Browser端使用,即同时会在Browser端的OpenGL上下文中使用。这样就必须要保证Render端的OpenGL上下文和Browser端的OpenGL上下文不会同时使用同一个资源。
为了解决Render端和Browser端的OpenGL上下文之间的资源同步问题,Render端在处理下一个Compositor Frame的时候,不能使用上一个Compositor Frame所引用的资源。Browser端执行完成合成操作之后,会将之前Render端发送过来的Compositor Frame所引用的资源返回给Render端。这时候Render端就可以继续使用返回来的资源了。这就是Render端和Browser端的OpenGL上下文之间的资源同步方式。
WebGL端和Browser端的OpenGL上下文之间的资源同步方式有所不同。WebGL端和Browser端的OpenGL上下文需要同步的资源就是它们之间通过Mailbox机制传递的Texture。为了提高渲染效率,Render端在WebGL端还没有渲染完成通过Mailbox传递的Texture之前,就已经将它封装在Compositor Frame中传递给Browser端了。为了保证这个Texture在Browser端执行合成操作的时候已经渲染完毕,WebGL端会在自己的OpenGL上下文中插入一个同步点(Sync Point)。这个插入的Sync Point同样会通过Mailbox机制传递给Browser端。Browser端在使用这些通过Mailbox机制传递过来的Texture之前,需要检查同时关联的Sync Point是否已经被调度过了。如果已经被调度过,那么就说明它所描述的Texture已经渲染完毕,这时候Browser端就可以使用它们了。这实际上是一个生产者-消费者问题。
前面提到,WebGL端、Render端和Browser端本身并不负责执行GPU命令,它们负责生成GPU命令,然后传递给GPU线程执行。WebGL端、Render端和Browser端生成的GPU命令是通过共享内存传递给GPU线程的,如图4所示:
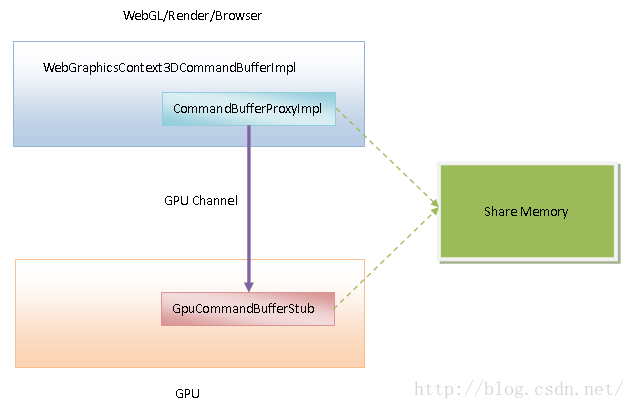
图4 WebGL/Render/Browser和GPU线程之间的GPU命令传递方式
Render端、WebGL端和Browser端在与GPU线程建立了一个GPU通道之后,会将该GPU通道封装在一个WebGraphicsContext3DCommandBufferImpl对象中。这个WebGraphicsContext3DCommandBufferImpl对象内部包含了一个CommandBufferProxyImpl对象。每一个CommandBufferProxyImpl对象在GPU线程中又会有一个对应的GpuCommandBufferStub对象。以后Render端、WebGL端和Browser端与GPU线程就是通过上述的CommandBufferProxyImpl对象和GpuCommandBufferStub对象来传递和执行GPU命令的。
其中,CommandBufferProxyImpl对象负责生成GPU命令,并且将生成的GPU命令保存在一块共享内存中。在合适的时候,CommandBufferProxyImpl对象会通知GpuCommandBufferStub对象到上述的共享内存中将还没有执行的GPU命令提取出来执行。
我们知道,有些GPU命令除了命令本身,还附带有数据,例如glBufferData命令。这些数据也是通过共享内存传递给GPU线程的。GPU命令附带的数据有可能非常大,并且大到超过系统允许创建的最大共享内存块。Chromium使用一种称为Bucket的机制来解决该问题。每一个Bucket都关联有一个ID,并且每一个Bucket一次只可以传递固定大小的的数据给GPU线程。当一个Bucket不能一次性传递完一个GPU命令附带的数据时,那么该Bucket就会分多次进行数据传递。当GPU命令附带的数据传递完毕,再传递GPU命令本身,不过这时候GPU命令关联有一个Bucket ID,表示它所附带的数据可以通过该关联的Bucket ID找到。
对于目前的GPU来说,由于多核特性,它的图形计算能力是极其强大的。不过有时候我们在使用GPU的时候,仍然会觉得图形渲染效率不高。出现这种现象的一个很重要的原因是相对GPU的计算能力来说,将数据从CPU传递到GPU的速度太慢了。例如,如果我们要将一个很大的Bitmap作为OpenGL纹理来渲染,那么首先要做的一件事情就是将Bitmap数据从CPU传递到GPU。如果这个纹理数据传递是发生在GPU线程中,那么就会影响到后面的GPU命令的执行,这样就会出现效率问题了。我们是无法改变纹理数据从CPU传递到GPU的速度的,但是我们可以不在GPU线程中将纹理数据从CPU传递给GPU,而是另外一个专门的线程进行传递,这样就可以很好地解决纹理上传的效率问题。
Chromium提供了两种方式将纹理数据从CPU传递到GPU。一种是同步方式,另一种是异步方式。在同步方式中,纹理数据是在GPU线程中进行传递的,它会影响到后面的GPU命令的执行。在异步方式中,纹理数据是在另外一条专门的线程中进行传递的,它不会影响到后面的GPU命令的执行,不过它需要解决在两个不同的线程中进行纹理共享的问题,Chromium使用了EGLImageKHR来解决该问题。
以上就是Chromium硬件加速渲染机制涉及到的基础知识,只有彻底理解这些基础知识,后面我们才可以更好地研究Chromium是如何硬件加速渲染网页UI的。为了彻底理解这些基础知识,接下来我们还会结合源码来进一步分析本文所涉及到的知识点,包括:
2. OpenGL上下文创建过程分析。
3. OpenGL命令执行过程分析。
5. OpenGL上下文调度过程分析。
敬请关注!更多的信息也可以关注老罗的新浪微博:http://weibo.com/shengyangluo。