今日头条 7 年,好的算法还可以做什么?

作者 | 唐小引
封图 | CSDN 付费下载自东方 IC
出品 | CSDN(ID:CSDNnews)
在《How Google Works》一书中,前 Google CEO 及 Alphabet 董事长 Eric Schmidt(埃里克·施密特)分享了一则对于 Google 而言非常尴尬的往事:「在 Google 搜索引擎的快速发展阶段,与成人话题相关的内容成为搜索热点……美国最高法院法官波特·斯图尔特曾这样对色情网站下过定义:‘只要用 Google 搜索一下,就知道色情网站是什么了。’」
对此,Google 特别安排了一组工程师,通过技术手段来解决这种影射的情况 —— 「他们找到了一种理解图像内容的方法,并可以通过用户使用图像的方法来界定图像所处的背景」。
这就是 Google 搜索的一大特性 —— 「SafeSearch(安全搜索)」过滤器的由来。
与算法无处不在的 Google 搜索遭遇过同样问题的还有 Facebook、微信以及今日头条。新闻大亨默克多曾直指「Facebook 和 Google 通过算法使低俗的新闻来源变得流行」,而在国内,一方面,是互联网巨头们的产品因低俗低质内容而让用户产生困扰、诟病的更是不止一二,另一方面,是针对互联网中层出不穷的低俗低质内容,微信、今日头条们用零容忍的态度及庞大的人工审核团队,譬如微信在今年仅两个月的时间便封禁及处理了近 4 万发送低俗内容的账号。
而诞生 7 年,已经成为一大国民级应用的今日头条,近期推出了一种用算法反低俗的解决方案 ——「灵犬反低俗助手 3.0」。
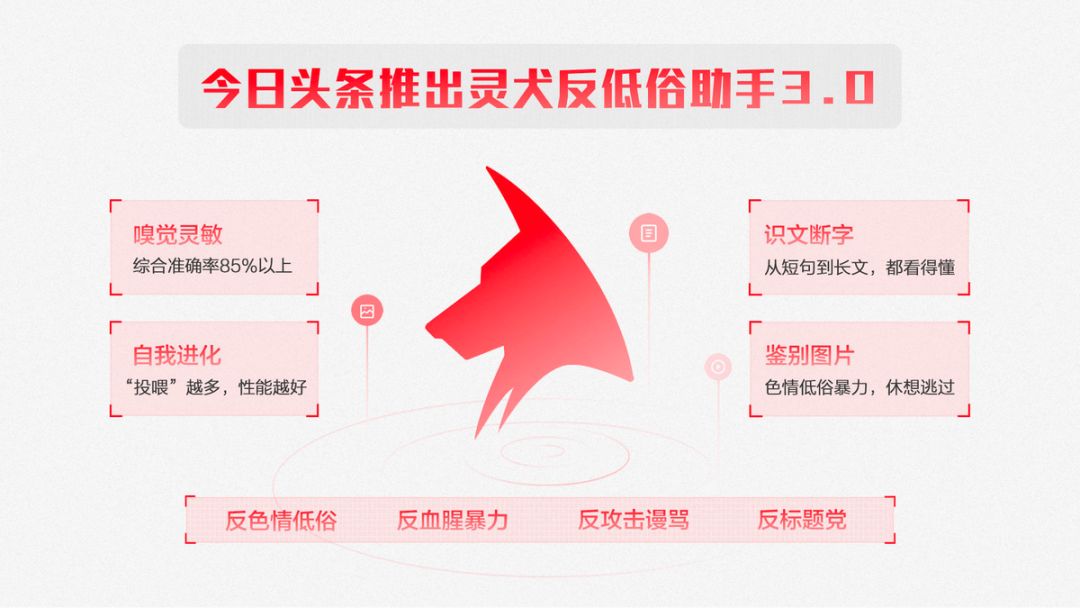

灵犬 —— 机器学习反低俗的产物
据今日头条官方介绍,「灵犬反低俗助手」脱胎于今日头条反低俗模型,是一款检测内容健康度的小程序,目前用户可以直接在今日头条内搜索使用(注:微信小程序正在审核中)。在经过 1.0 到 3.0 的持续迭代中,“灵犬”已经实现了文本、图片识别功能,不仅能够识文断字、鉴别图片,还可以自我进化,在「灵犬 3.0」中,文本识别的准确率已提升至 91%。
为什么会用技术来反低俗?在「灵犬反低俗助手 3.0」的发布现场,字节跳动人工智能实验室总监王长虎对此讲道:「在移动互联网时代,UGC 和自媒体的涌现,使内容创作和消费,实现了几何指数级的海量增长。仅以今日头条平台为例,每天发布的内容就超过 60 万条。」这就给审核低俗内容带来了极为严峻的挑战。尽管相比于人,机器计算快、存储大、稳定性较高,然而一直以来,机器始终需要人给它写程序、下指令做具体的事情,「机器扮演的角色是执行」。
但在过去的十年里,技术领域出现了最大的技术进步 —— 机器学习。「机器学习,顾名思义,机器能够通过自我学习,从而实现自我进化。机器的边界变得更大了,能做的事情更多了。在机器学习的状态下,人只需要提供充分、具体的样本,机器经过训练就能总结出一套判断准则。」
而灵犬,便是机器学习反低俗的产物。

字节跳动人工智能实验室总监王长虎
另一方面,灵犬以极其轻量用完即走的小程序形态呈现,对此,在接受 CSDN(ID:CSDNnews)采访时,字节跳动人工智能实验室总监王长虎表示:「小程序这个形态相对较轻,并且稳定,能够供用户比较长期地使用,同时,灵犬也是今日头条推出的第一批小程序之一。」
从去年 3 月首次上线,到今天 3.0 发布这一年半的时间里,灵犬一直在马不停蹄地迭代:
-
2018 年 3 月,灵犬首次上线,支持检测文字和文章链接;
-
2018 年 5 月,灵犬完成服务升级,增加反色情短文本模型和反谩骂模型,将准确率从 73% 提升至 82%;
- 2019 年 2 月,「灵犬 2.0」正式上线,除了反色情低俗模型,加入反暴力谩骂和反标题党模型,覆盖了主要的低俗低质内容类型,整体识别准确率接近 85%。
同时,用户使用起来也是非常地简单,只需在「灵犬反低俗助手」小程序中选择「文本识别」、「图片识别」,前者输入一段文字、文章链接,后者上传图片或图片链接,即可快速获得鉴定结果,如果命中特定词表,会显示「须交由人工审核」。据今日头条官方统计,截止 2019 年 6 月,「灵犬反低俗助手」的使用人次已经超过了 300 万。
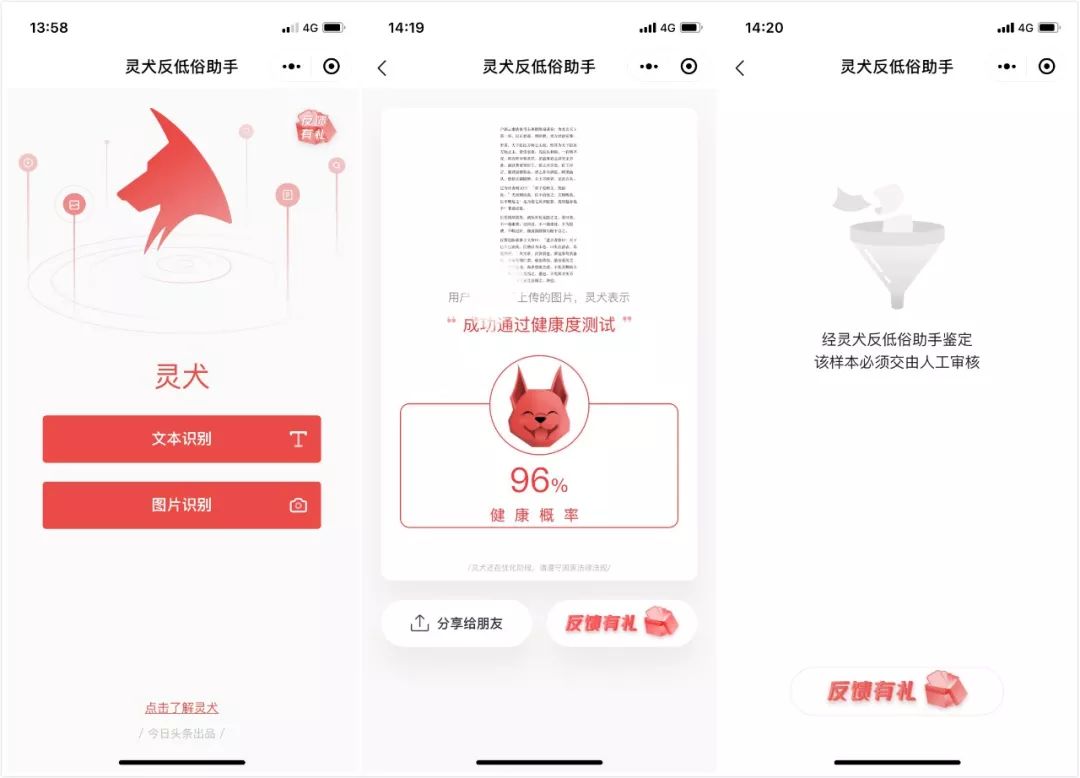
前台操作很简单,让用户毫无门槛地直接使用,但看不见的功夫都在后台,「灵犬」是如何实现「反低俗」的?王长虎在现场为我们全方位地剖析了灵犬背后的技术原理。

算法如何反低俗?剖析灵犬的技术原理
一、我们先看文本识别****
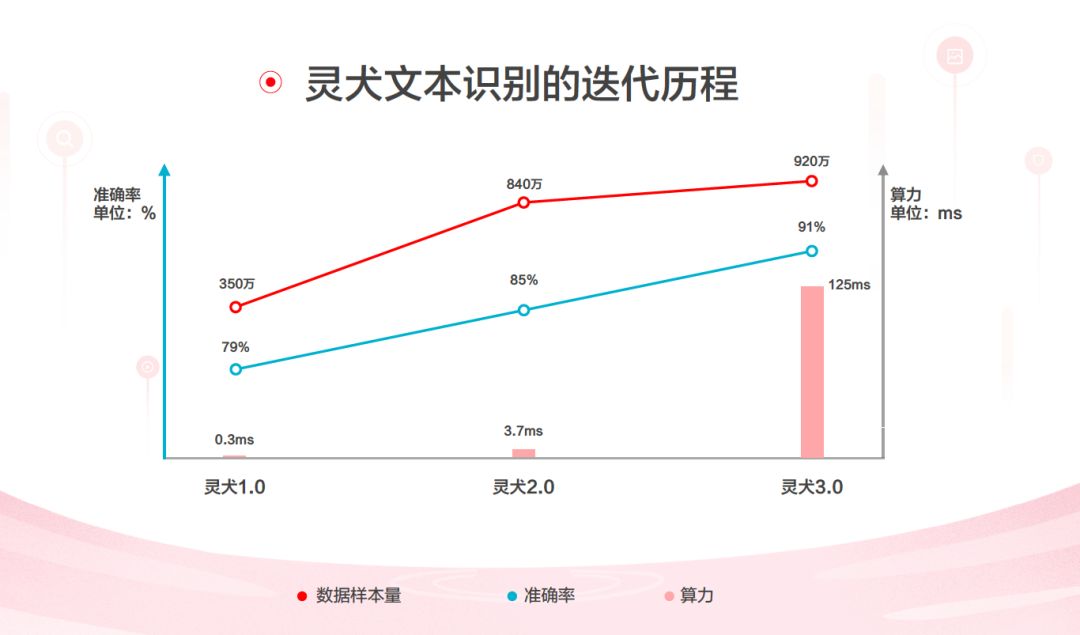
机器如何判断文本低俗?一个简易的方案就是分词,做词表,但这会导致机器只能看表象、词表容量有限容易被绕过、更新频率必须要高等问题。对此,灵犬采用了自然语言处理(NLP)技术,在其核心的文本分类模型上,进行了三次大版本迭代。

从 1.0 采用「词向量」和「CNN」,2.0 应用「LSTM」及「Attention」,到最新的第三代灵犬中,采用了当下炙手可热的 Google Bert 模型及半监督学习技术,每一次的更迭,准确率都在大幅提升。
在 3.0 中,更是使用了专用中文语料,训练数据集总量为 1.2 T,相当于 20 倍百度百科或 100 倍维基百科的数据总量,包含了 920 万个样本,文本识别准确率也从第一代的 75% 提升至 91%。
Bert 自横空出世以来便备受瞩目,它为 NLP 指明了发展方向,那便是「通过预训练模式,充分使用大量的无标注语言数据,利用自监督模型,发挥 Transformer 特征吸收能力强的特点,来对语言知识进行特征编码。用这些知识来促进很多下游 NLP 任务的效果,以弥补有监督任务往往训练数据规模不够大,无法充分编码语言知识的困境。」
在谈到第三代灵犬的技术选型时,王长虎表示:「Bert 模型提出了一种大的模型结构(参数量是之前模型的 10 倍多,计算量也提高了 10 倍多),以及通过监督学习对天然超大规模语料建模,使得对语义的刻画更为准确。而半监督技术,能引入更多非标注语料,使得模型的鲁棒性更好。」
不过,当前在人工智能领域预训练语言模型的 PK 战可是分外地激烈,譬如 Google 新模型 XLNet 在各项基准测试中都优于 Bert,Facebook 又紧随其后开源了 RoBERTa 预训练模型,导致行业内 XLNet 和 Bert 到底选谁之风正盛。
对此,王长虎向 CSDN(ID:CSDNnews)分享了为什么灵犬 3.0 会选用 Bert:「这之中既有公开的实验对比,也有内部的应用验证。XLNet 我们其实也做了跟进,综合结论是和 Bert 效果相近,包括 Facebook 最新的 RoBERTa 模型和我们的实验结论很多都是一致的,对于在选型上我们还会继续借鉴。同时,灵犬后续将着力解决对更多类型语料的覆盖,使得适用性更广。」
二、图片识别
再看图片识别,王长虎表示,图片识别一般面临非均衡、类内方差大、不可穷举等问题,尤其是「图像识别的特征提取,无论是初级特征的形状、颜色、纹理,还是高级特征中的语义,其数量都是无限的」,由此导致,面对庞大的数据,对于图片反低俗来说,穷举法是不太可行的。
因此,灵犬 3.0 使用深度学习解决方案,对深度学习非常依赖的数据量、算力、模型三方面要素进行了针对性的优化:
- 数据层面:积累了上千万级别的训练数据。
深度学习在当下非常地炙手可热,但其也很依赖于数据,其性能也与可用来训练的数据量密切相关。对此,王长虎如此说道:「深度学习能够取得成功的主要原因在于互联网时代的大数据以及硬件发展带来的计算力的提升,在大量的数据中,深度学习的模型可以学习到更具泛化性和判别性的特征表示。然而,深度学习的可解释性较差,推理的能力还有待研究,在一些数据收集比较困难的任务上,深度学习也会遇到瓶颈。我们也在持续地研究相关问题,持续地改进灵犬反低俗的能力。」
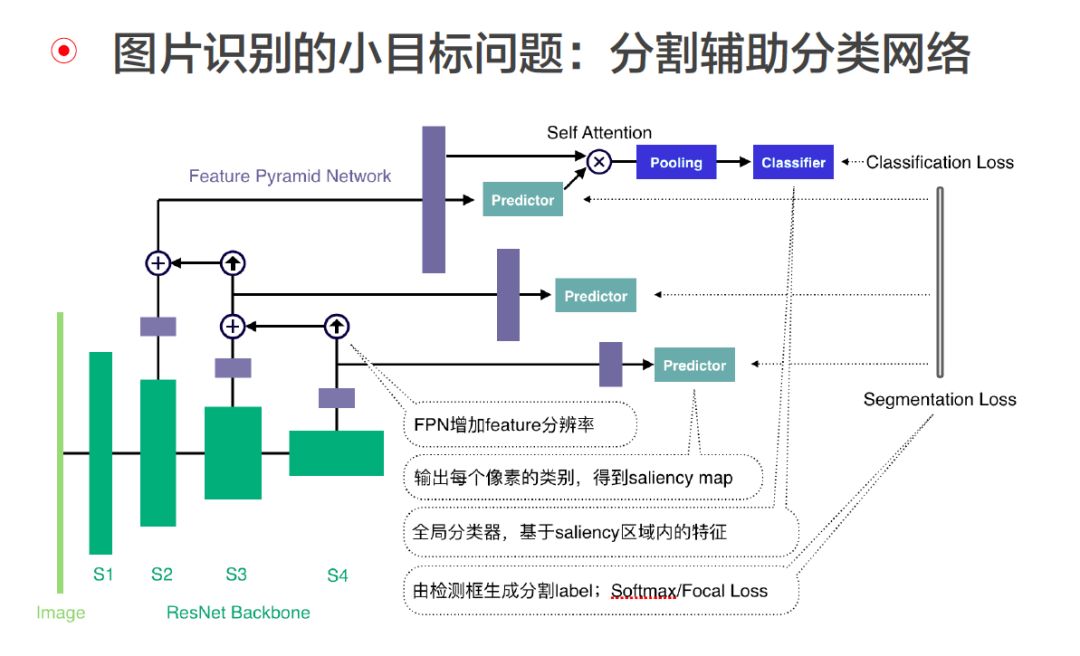
- 模型层面:针对许多困难样本进行模型结构调优,包括多尺寸、多尺度、小目标等。
为了使得各个比例的图片都能很好地被识别,灵犬采用了多桶模型,在不增加预测时间的情况下,提升模型的准确率;为了应对人在图片中的面基占比变化较大问题,引入特征金字塔结构,对不同尺度的物体,提高模型提取一致特征的能力;为解决在图片背景中出现小范围问题区域,设计了分割辅助分类网络,使得模型能够更专注于问题区域。
- 计算力层面:利用分布式训练算法以及强大的 GPU 训练集群,加速模型的训练和调试,利用模型压缩技术,提升模型的预测速度。
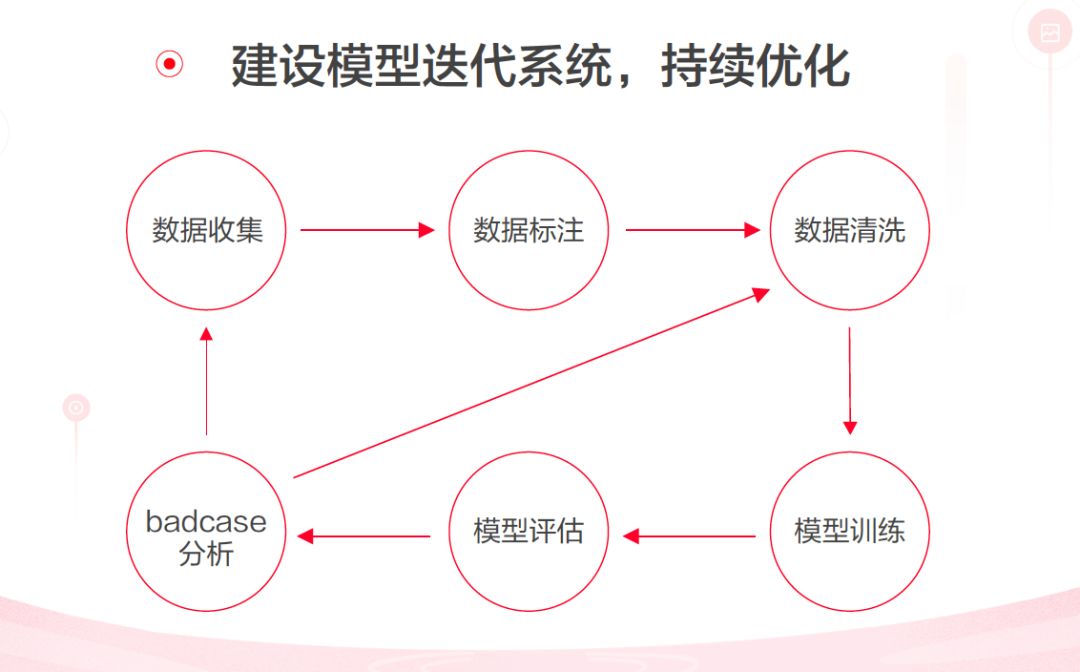
除了上述之外,灵犬还建设了比较完善的模型迭代系统。通过“数据收集—数据标注—数据清洗—模型训练—模型评估—badcase分析”这一套完整的流程,实现持续优化。

反低俗的复杂性 —— 我们仍然面临哪些技术难点?
在我们文章开篇所讲的 Google SafeSearch 也不是一蹴而就的,Google 用了几年的时间进行了持续研发,施密特在书中如此讲道:「在 SafeSearch 的研发过程中,我们基于图像内容得出了数百万种用户使用模式,利用这些模式,我们判断图像与搜索请求相关性的能力得到了提升。」后来,在不断的更迭中,Google 不仅用 SafeSearch 解决了屏蔽色情网站内容的问题,还将这一技术应用在了更广泛的范围。
「灵犬反低俗助手」同样如此。
王长虎表示,机器学习是一个“学无止境”的过程,同时,低俗判断不是一个机器能够轻易完成的事情,「即使对人来说,低俗的定义也是相对笼统的,没有办法精确地定义什么是低俗。而如果没有一个精确的区分准则,就没有办法给计算机写出执行步骤让它去判断。」
对于技术模型来说,清晰、无歧义、不带感情色彩的文字,高清、无码、不具有太多延伸意义的图片,自然是比较好识别的,但是现实中会有很多复杂情况,导致需要人工判断,譬如,汉语的多义和歧义、语言之外的情感表达等,以及在图片方面,机器通过识别肌肤裸露面积来判定是否违规,会从一定程度上让一些具有历史意义和艺术性的照片受到波及。
「机器只是把文字当成符号,从表面去理解它。就像盖房子的砖块一样,机器只能把这些砖块罗列和堆积起来,不完全知道某些砖块可能比另一些砖块更为重要,有些砖块需要转换一下角度来看,或者跟别的砖块搭配在一起看才合理。而在图片角度,技术一刀切的局限在许多美术作品中体现得淋漓尽致,像许多知名的艺术作品,如果完全交给机器来判断,机器通过识别画中人物的皮肤裸露面积,便会认为这幅画是色情低俗的。这个时候,就需要人工来审核判断。」王长虎如是说道。
面对在实际操作中,低俗判断问题的复杂性和不同判断方式的局限性,当技术暂时还难以制定标准,并且标准也会因环境不同而变动时,灵犬采取了不断进化技术模型,并结合技术和人工判断两种方式的解决方案。

技术反低俗的下一城
在已经实现了文本、图片识别的基础上,灵犬还将上线语音、视频识别功能。不过,王长虎表示:「灵犬其实只是今日头条技术反低俗的一个简化版本,受限于小程序体裁和模型应用条件,它还不够完美,也不能完全反映出今日头条反低俗系统的真实情况和全部面貌。」
当前,在今日头条内部,以灵犬为代表的反低俗系统已经在广泛地应用,同时在内容审核方面,众所周知的,今日头条有着近万人的专业审核团队。并且,今日头条内部还搭建了包含色情、低俗、标题党、虚假信息、低质等在内的数百个技术模型,结合人工、技术手段,有效提升了内容审核的效率和准确度。
灵犬可以说是今日头条反低俗系统由内部向行业开放的一大信号,无需下载所有用户便可以直接使用。同时,王长虎向 CSDN 表示:「我们已经在规划做进一步的开放,将灵犬和头条创作者后台打通,提示创作者,更方便创作者使用。我们也欢迎第三方跟我们合作,一起来帮助行业提升标准。」

【END】

热 文 推 荐
☞ 最早的算法可追溯到三千年前,“所谓的 AI 并非源自先进的技术”!
☞GitHub 断供危机来了!权威解读程序员应对指南 | CSDN 独家
☞ 90 后程序员薪资大揭秘:有人刚毕业年薪 200 万,有人月薪不足 1 万
☞ 学阿里中台,80%的人只学到了皮毛!揭秘阿里中台的12个架构思维和原则
☞ 真正适合小白的教程:Python有什么用?数据化运营怎么做?
☞ 效果惊人!中科院、百度研究院等联合提出UGAN,生成图片难以溯源

