每年 150 亿美元花哪了?Netflix 的大规模 Kafka 实践
Netflix 在 2019 年花费了大约 150 亿美元来制作世界一流的原创内容。在如此高的投入之下,我们必须获得许多关键的业务见解,从而为所有 Netflix 内容的策划、预算和效益分析工作提供帮助。这些见解可以是以下内容:
- 明年我们应该花费多少钱采购国外电影和电视剧?
- 我们是否快要超出制作预算了,是否需要有人介入把事情扳回正轨?
- 我们如何利用数据、直觉和分析能力来提前规划全年的采播方案,尽可能做到完美的计划?
- 我们如何为来自全球的内容生成财务数据并向华尔街报告?
就像风险投资人精挑细选优秀的投资机会一样,Netflix 的内容财务工程团队旨在帮助 Netflix 投资、追踪并从我们的行动中学习经验,以便在未来不断做出更好的投资。
拥抱事件
从工程的角度来看,每个财务应用程序都是一个微服务。Netflix 拥护分布式治理的理念,并鼓励工程师在应用程序中使用微服务驱动的方法,从而在公司扩张时实现数据抽象和速度之间的适当平衡。在一个简单的环境中,服务之间可以通过 HTTP 进行良好的交互,但是随着我们的扩张,它们演变成了由同步交互请求组成的复杂网络。这有可能导致脑裂,并破坏可用性。
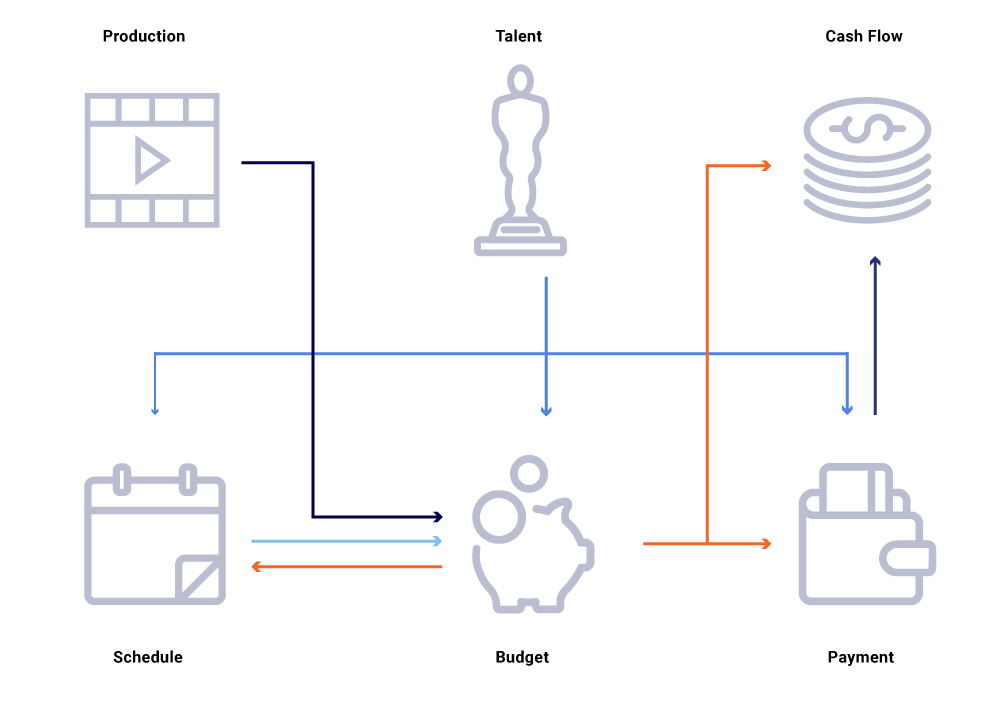
上图中的这些实体是相互关联的。假设某个节目的制作日期发生了变化,就会影响我们的节目播出计划,进而影响现金流项目、薪水支付和年度预算等。在微服务架构中,某种程度的失败通常是可以接受的。但是,对内容财务工程的任何微服务调用失败都会打乱一大堆计算结果,并可能导致数百万美元的损失。调用关系变得更为复杂时还会导致可用性问题,并在试图有效地跟踪和回答业务问题时产生盲点,例如:为什么现金流预测与我们的发布时间表不一致?为什么对本年度的预测未考虑正在制作中的节目?我们何时可以看到成本报告能够准确反映上游的变化?
当我们重新审视服务间的交互,并将它们视为事件交换流(而非一系列同步请求)后,我们就构建出了异步的基础架构。这种架构促进了解耦,并为分布式事务网络提供了可追溯性。事件不仅仅是触发器和更新,它们成为了不可变的流,我们可以基于事件流重构整个系统的状态。
我们转向发布订阅模型后,每个服务都可以将变更作为事件发布到消息总线中,然后这些事件被需要调整自身状态的服务消费。借助这种模型,我们能够跟踪各种服务的状态是否同步,如果还没有,它们还需要多长时间才能回到同步状态。当我们面对的是一大堆互相依赖的服务时,这些见解是非常有用的。基于事件的通信和去中心化的事件处理帮助我们解决了许多问题,这些问题在大型同步调用图中是很常见的(如上所述)。
Netflix 选择了 Apache Kafka 作为处理事件、消息传递和流处理的事实标准。Kafka 充当所有点对点和 Netflix Studio 范围内通信的桥梁。它为我们提供了 Netflix 操作系统所需的高持久性和线性可扩展的多租户架构。我们内部的 Kafka 即服务产品提供了容错能力、可观察性、多区域部署和自助服务。这使我们的整个微服务生态系统更容易地生产和消费有意义的事件,并释放出了异步通信的强大能量。
Netflix Studio 生态系统中的一次典型消息交换过程如下所示:
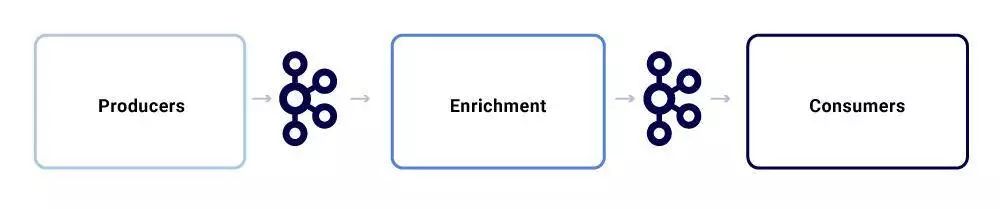
我们可以将它们分解为三大子组件。
生产者
生产者可以是任何系统,当这个系统想要发布其完整状态,或要表明其内部状态的某个关键部分已针对特定实体做出了更改,它就成是生产者。一个事件除了内容负载外,还需要遵循规范化的格式,以便于跟踪和理解。这种格式包括:
- UUID:通用唯一标识符
- Type:创建、读取、更新或删除(CRUD)这四种类型之一
- Ts:事件的时间戳
变更数据捕获(CDC)工具是另一类事件生产者,它将数据库变更作为事件。当你要让数据库变更对多个消费者可见时,这个工具就很有用了。我们还使用这个模式来跨数据中心复制相同的数据(对于单个主数据库)。例如,当 MySQL 中的数据需要被索引到 Elasticsearch 或 Apache Solr 中时,就会用到这个工具。使用 CDC 的好处是它不会给源应用程序增加额外的负载。
对于 CDC 事件,可以根据事件格式的 TYPE 字段为相应的数据槽转换事件。
强化器(Enricher)
在数据进入 Kafka 后,便可以对其应用各种消费模式。事件有多种用法,包括作为系统计算的触发器、作为近实时通信的内容传输负载,以及作为增强和物化数据内存视图的线索。
当微服务需要数据集的完整视图,但部分数据是来自另一个服务的数据集时,数据增强方法的应用就会愈加普遍。联接的数据集可用于提升查询性能或提供聚合数据的近实时视图。为了丰富事件数据,消费者从 Kafka 中读取数据并调用其他服务(使用 gRPC 和 GraphQL 等方法)来构造联接的数据集,然后将其发送到其他 Kafka 主题。
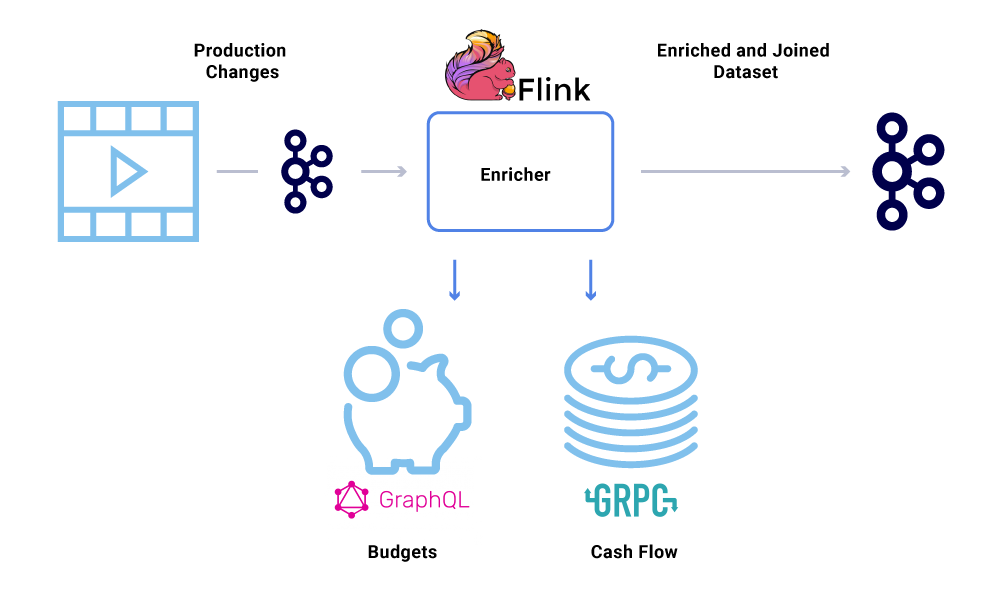
增强过程可以作为单独的微服务运行,该微服务负责执行扇出(fanout)和物化数据集。在某些情况下,我们希望进行更复杂的处理,例如基于时间窗口、会话的处理和状态管理等。对于这种情况,建议使用成熟的流处理引擎来构建业务逻辑。在 Netflix,我们使用 Apache Flink 和 RocksDB 来做流处理。我们也在考虑使用 ksqlDB( https://ksqldb.io/ )。
事件的顺序
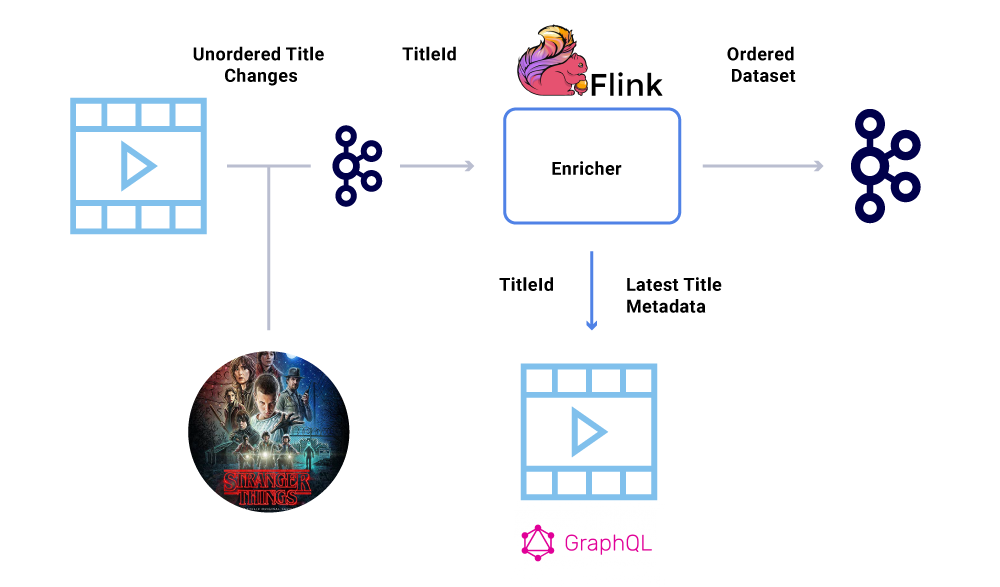
财务数据集的一项关键需求是事件的顺序。在 Kafka 中,我们可以通过发送带有键的消息来实现这一目的。使用相同键发送的事件或消息都能保证正确的顺序,因为它们被发送到了相同的分区。但是,生产者仍然可以弄乱事件的顺序。
例如,“Stranger Things”的发行日期先是从 7 月移至 6 月,然后又从 6 月移至 7 月。由于种种原因,这些事件可能会按照错误的顺序写入 Kafka(可能因为生产者到 Kafka 的网络超时、生产者代码中的并发错误等)。一个很小的顺序错误可能会严重影响许多财务计算结果。
为了避免这种情况,建议生产者只发送发生变更的实体的主要 ID,而不发送 Kafka 消息的完整内容。增强过程(如前所述)使用实体的 ID 查询源服务,以获取最新的状态或内容,从而提供了一种很好的方式来解决顺序错乱问题。我们将其称为延迟物化(delayed materialization),它可以保证数据集的顺序是正确的。
消费者
我们使用 Spring Boot 来实现微服务,这些服务从 Kafka 主题读取数据。Spring Boot 提供了很棒的内置 Kafka 消费者(称为 Spring Kafka Connector),可以无缝消费,并提供了简便的注解(annotation),用于消费和反序列化数据。
关于数据,还需要讨论的一个概念是合约。随着事件流用得越来越多,我们最终得到了一组互不相同的数据集,其中一些数据集被大量应用程序消费。在这些情况下,在输出上定义一种 schema 是理想的选择,并有助于确保向后兼容。为此,我们利用 Confluent Schema Registry 和 Apache Avro 来构建带有 schema 的流。
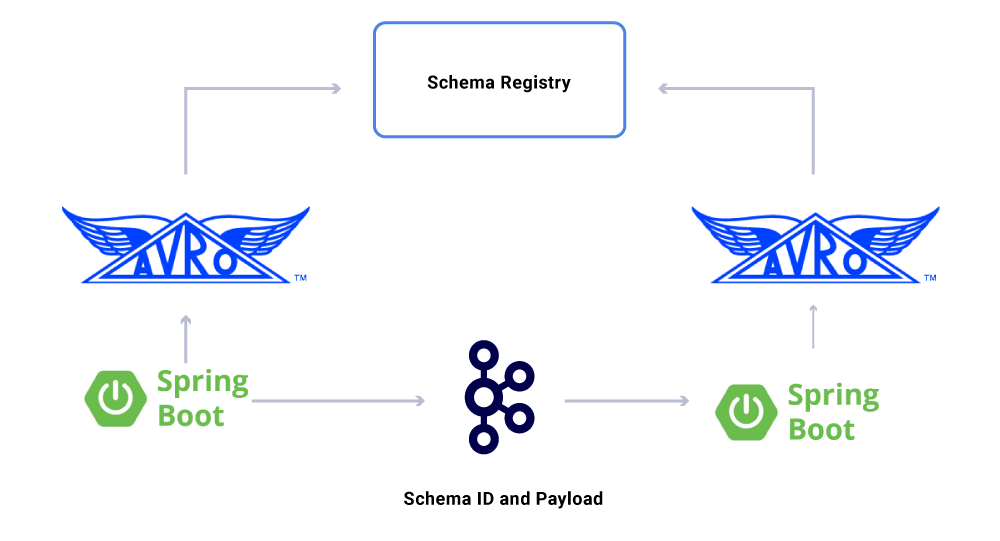
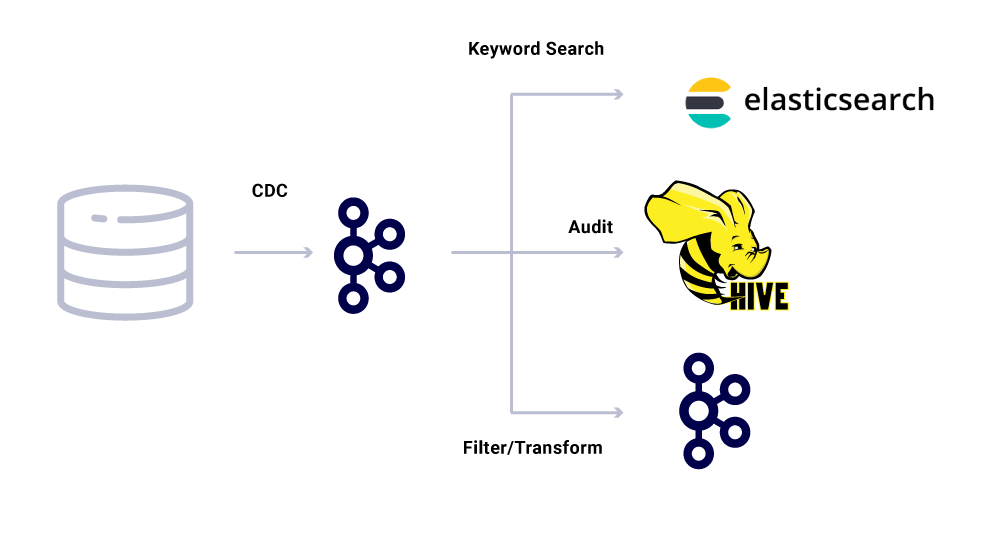
除了专有的微服务消费者外,我们还有 CDC 数据槽,将数据索引到多种存储中,以便进行进一步的分析。其中包括用于关键字搜索的 Elasticsearch、用于审记的 Apache Hive,以及用于进一步下游处理的 Kafka。这些数据的内容可以直接来自 Kafka 消息,并使用 ID 字段作为主键,根据 TYPE 字段进行 CRUD 操作。
消息传递保证
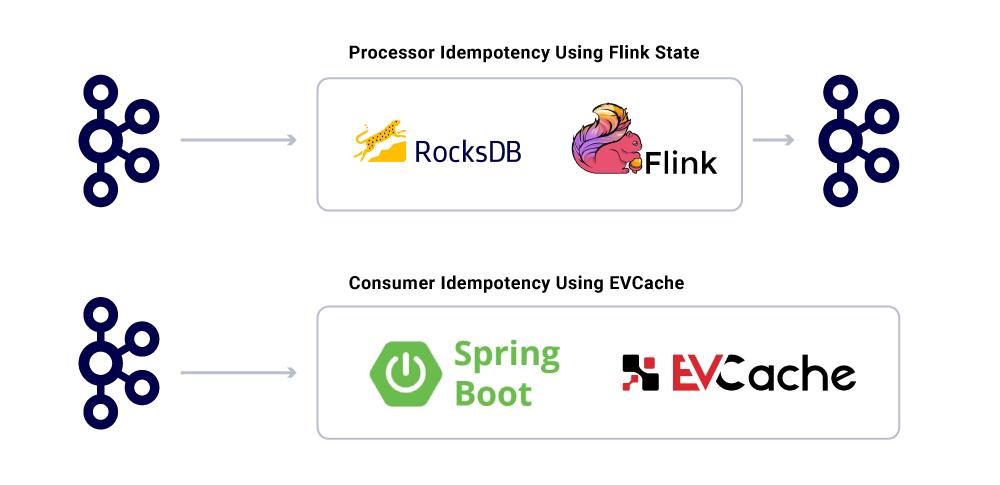
在分布式系统中,保证一次仅一次消息传递并不是一件容易的事情,因为涉及的组件太多,太过复杂。消费者行为应该具有幂等性,以应对任何潜在的基础设施和生产者故障。
但即使应用程序是幂等的,也不应该为已处理过的消息进行重复繁重的计算。为了做到这一点,一种流行方法是通过分布式缓存来跟踪消息的 UUID,只要在到期时间间隔内遇到相同的 UUID,就不进行重复处理。
Flink 在内部使用 RocksDB 实现状态管理,使用键作为消息的 UUID,以此来实现只处理一次。如果你只想使用 Kafka,Kafka Streams 也提供了一种方法。基于 Spring Boot 的应用程序可以使用 EVCache 。
监控基础架构服务水平
对于 Netflix 来说,实时查看其基础架构中的服务水平是至关重要的。Netflix 开发了 Atlas 来管理维度时间序列数据,我们用它可视化指标。我们使用生产者、处理器和消费者发布的各种指标来帮助我们构建整个基础架构的近实时视图。
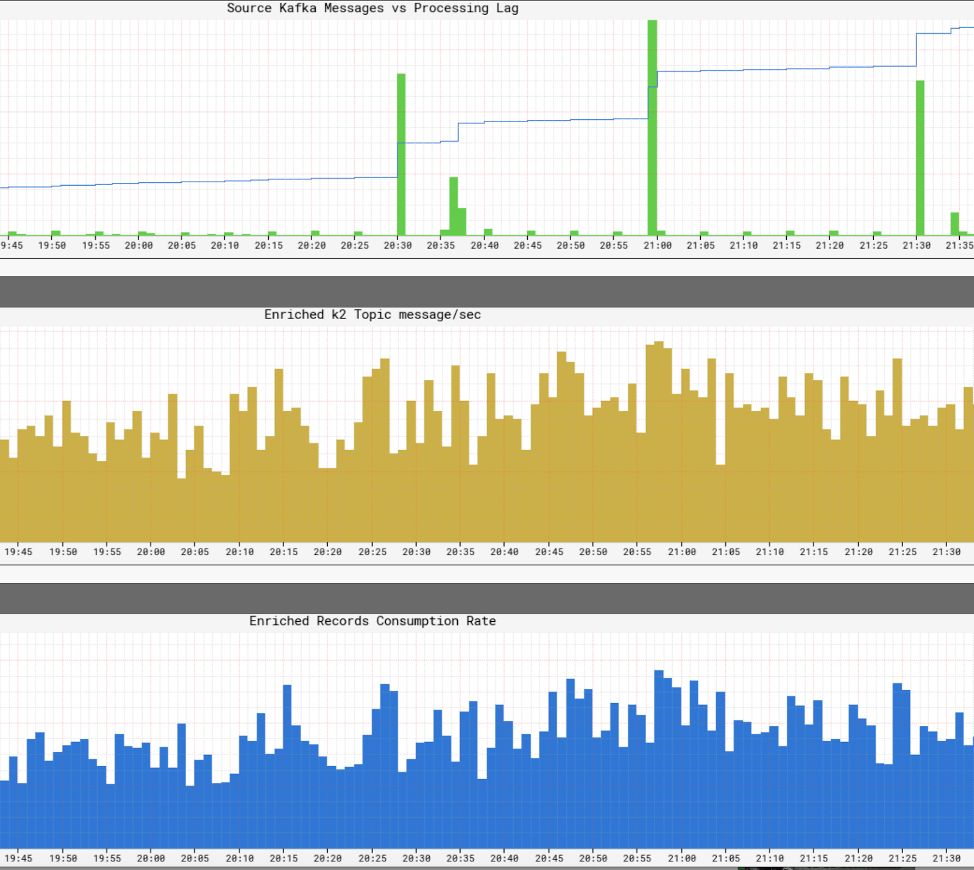
我们监控的一些关键指标有:
新鲜度 SLA
- 从事件的产生到事件到达所有数据槽的时间是多少?
- 每个消费者的处理延迟是多少?
最大传输速率
- 我们能够发送多大载荷?
- 我们应该压缩数据吗?
分区和并行化
- 我们是否有效地利用了我们的资源?
- 我们可以更快地消费吗?
故障转移和恢复
- 我们是否可以为状态创建检查点并在发生故障时恢复?
背压
- 如果我们无法跟上事件流的速度,是否可以在不使应用程序崩溃的前提下对相应的源应用背压?
负载分配
- 我们如何处理事件爆发?
- 我们是否有足够的资源来满足 SLA?
总结
Netflix Studio 制作和财务团队选择了分布式治理作为系统的架构方式。我们使用 Kafka 作为处理事件的首选平台,帮助我们在基础架构中实现了更高的可见性和更好的解耦,同时帮助我们有机地扩展了运营工作。它是 Netflix Studio 基础设施变革以及随之而来的电影工业变革浪潮中的核心角色。
如果你想了解更多信息,可以查看我在 Kafka 旧金山峰会演讲:Eventing Things – A Netflix Original 的录像和幻灯片!
作者介绍:
Nitin Sharma 是 Netflix 内容财务基础架构团队的一名分布式系统工程师,他在构建和运营大型分布式基础架构方面已有十多年的经验。他曾从事数据存储、搜索平台、事件驱动的架构,流处理、消息传递和机器学习基础架构方面的工作。他是一名狂热的技术演讲者,并在诸多国际会议上发表过演讲。
作者丨Nitin Sharma
译者 | 王强
策划 | 蔡芳芳