我用 70 行 Go 语言代码击败了 C 语言
今天,我们将会使用 Go 来打败 wc。作为一个具有出色同步原语的编译语言,要达到与 C 相当的性能应该是毫无困难的。
虽然 wc 同样可以从 stdin 中读取,处理非 ASCII 文字编码,解析命令行 flag(帮助页面),但是这里将不做描述。相反,我们将会尽力将实现简单化。
这篇文章的源代码可以在这里找到。
测试和对比
我们将使用 GNU 时间工具来对比运行时间和最大驻留集大小。
$ /usr/bin/time -f "%es %MKB" wc test.txt我们会使用和最初文章相同的 wc 版本,由 gcc 9.2.1 和 -O3 编译。对于我们自己的实现,我们会使用 go 1.13.4 版本(我也尝试过 gccgo,但是结果并不是非常理想)。我们的所有测试都是在以下配置上进行的:
- Intel Core i5-6200U @ 2.30 GHz (2 physical cores, 4 threads)
- 4+4 GB RAM @ 2133 MHz
- 240 GB M.2 SSD
- Fedora 31
为了公平对比,所有的实现都会使用一个 16 KB 的 buffer 读取两个 us-ascii 编码的文本文件(一个 100 MB,一个 1 GB)的输入。
一个朴素的方法
解析参数很简单,我们只需要文件路径:
if len(os.Args) < 2 {
panic("no file path specified")
}
filePath := os.Args[1]
file, err := os.Open(filePath)
if err != nil {
panic(err)
}
defer file.Close()我们会按字节顺序遍历文本来跟踪状态。幸运的是,我们目前只需要两种状态:
前一字节是空格
前一字节不是空格
当从空格字符遍历到非空格的字符时,我们会增加字数计数。这种方式允许我们能够直接读取字节流,从而保持较低的内存消耗。
const bufferSize = 16 * 1024
reader := bufio.NewReaderSize(file, bufferSize)
lineCount := 0
wordCount := 0
byteCount := 0
prevByteIsSpace := true
for {
b, err := reader.ReadByte()
if err != nil {
if err == io.EOF {
break
} else {
panic(err)
}
}
byteCount++
switch b {
case '\n':
lineCount++
prevByteIsSpace = true
case ' ', '\t', '\r', '\v', '\f':
prevByteIsSpace = true
default:
if prevByteIsSpace {
wordCount++
prevByteIsSpace = false
}
}
}我们会用本地的 println() 函数来显示结果。在我的测试中,导入 fmt 库就导致可执行文件大小增加了大约 400KB!
println(lineCount, wordCount, byteCount, file.Name())运行之后:
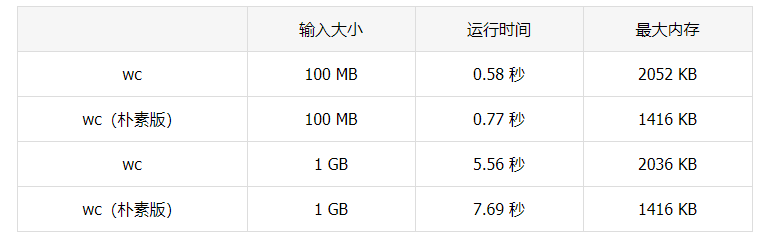
好消息是,我们的首次尝试已经让我们在性能上接近 C 了。而在内存使用方面,我们实际上做的比 C 还要好!
分割输入
虽说缓存 I/O 的读取对于提高性能至关重要,但调用 ReadByte() 并在循环中查找错误会带来很多不必要的开销。为了避免这种情况的发生,我们可以手动缓存我们的读取调用,而不是依赖 bufio.Reader。
为了做到这点,我们将输入分割到可以分别处理的多个缓冲 chunk 中。幸运的是,我们只需要知道前一 chunk 中的最后一个字符是否是空格,就可以处理当前 chunk。
接下来是一些功能函数:
type Chunk struct {
PrevCharIsSpace bool
Buffer []byte
}
type Count struct {
LineCount int
WordCount int
}
func GetCount(chunk Chunk) Count {
count := Count{}
prevCharIsSpace := chunk.PrevCharIsSpace
for _, b := range chunk.Buffer {
switch b {
case '\n':
count.LineCount++
prevCharIsSpace = true
case ' ', '\t', '\r', '\v', '\f':
prevCharIsSpace = true
default:
if prevCharIsSpace {
prevCharIsSpace = false
count.WordCount++
}
}
}
return count
}
func IsSpace(b byte) bool {
return b == ' ' || b == '\t' || b == '\n' || b == '\r' || b == '\v' || b == '\f'
}现在就可以分割输入到 Chunks 中,并将其返回到 GetCount 函数:
totalCount := Count{}
lastCharIsSpace := true
const bufferSize = 16 * 1024
buffer := make([]byte, bufferSize)
for {
bytes, err := file.Read(buffer)
if err != nil {
if err == io.EOF {
break
} else {
panic(err)
}
}
count := GetCount(Chunk{lastCharIsSpace, buffer[:bytes]})
lastCharIsSpace = IsSpace(buffer[bytes-1])
totalCount.LineCount += count.LineCount
totalCount.WordCount += count.WordCount
}想要得到字节统计,我们可以用一个系统调用来检查文件大小:
fileStat, err := file.Stat()
if err != nil {
panic(err)
}
byteCount := fileStat.Size()完成之后,可以来看看他们的表现如何:
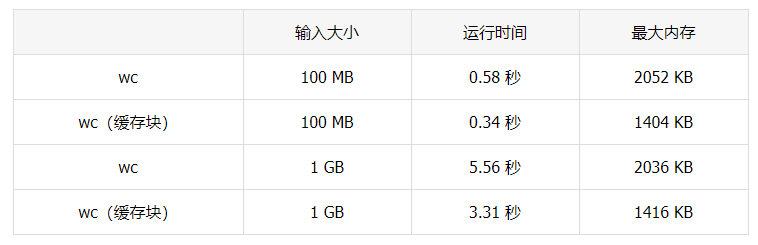
并行化
不得不说,并行化的 wc 是有点杀鸡用牛刀了,但是先让我们看看我们能走多远。原文章是并行读取输入的文件;尽管这改善了运行时间,作者同样承认由并行带来的这种性能提升很可能会仅限于某些类型的存储,在其他类型上甚至会带来负面影响。
我们实现的目标是代码可以在所有的设备上都表现良好,所以我们并不会采取原文章中方案。我们会创建两个通道,chunks 和 counts。每个 Worker 会读取并处理从 chunks 中读取到的数据,直到通道关闭,然后将结果写入 counts。
func ChunkCounter(chunks <-chan Chunk, counts chan<- Count) {
totalCount := Count{}
for {
chunk, ok := <-chunks
if !ok {
break
}
count := GetCount(chunk)
totalCount.LineCount += count.LineCount
totalCount.WordCount += count.WordCount
}
counts <- totalCount
}每个逻辑 CPU 内核都会被分配到一个 Worker:
numWorkers := runtime.NumCPU()
chunks := make(chan Chunk)
counts := make(chan Count)
for i := 0; i < numWorkers; i++ {
go ChunkCounter(chunks, counts)
}进入循环,从磁盘中读取并将任务分给每个 Worker:
const bufferSize = 16 * 1024
lastCharIsSpace := true
for {
buffer := make([]byte, bufferSize)
bytes, err := file.Read(buffer)
if err != nil {
if err == io.EOF {
break
} else {
panic(err)
}
}
chunks <- Chunk{lastCharIsSpace, buffer[:bytes]}
lastCharIsSpace = IsSpace(buffer[bytes-1])
}
close(chunks)完成这一步之后,就可以简单的汇总每个 Worker 的计数:
totalCount := Count{}
for i := 0; i < numWorkers; i++ {
count := <-counts
totalCount.LineCount += count.LineCount
totalCount.WordCount += count.WordCount
}
close(counts)运行之后,和之前的结果进行比较:
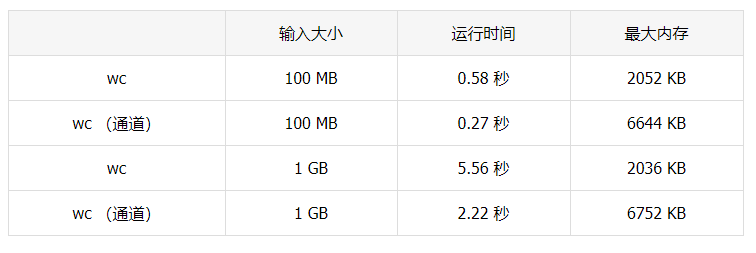
wc 的速度现在要快得多,但是内存使用率则被大大地降低了。这是因为输入循环在每次的迭代中都要分配内存。通道是一个共享内存的一个绝佳抽象,但是对于部分用例,只要不使用通道就可以极大幅度地提高性能。
优化后的并行
这部分中我们允许每个 Worker 读取文件,并使用 sync.Mutex 来保证读取行为不会同时发生。我们可以创建一个新的 struct 来处理这一部分:
type FileReader struct {
File *os.File
LastCharIsSpace bool
mutex sync.Mutex
}
func (fileReader *FileReader) ReadChunk(buffer []byte) (Chunk, error) {
fileReader.mutex.Lock()
defer fileReader.mutex.Unlock()
bytes, err := fileReader.File.Read(buffer)
if err != nil {
return Chunk{}, err
}
chunk := Chunk{fileReader.LastCharIsSpace, buffer[:bytes]}
fileReader.LastCharIsSpace = IsSpace(buffer[bytes-1])
return chunk, nil
}重写 Worker 函数使其直接读取文件:
func FileReaderCounter(fileReader *FileReader, counts chan Count) {
const bufferSize = 16 * 1024
buffer := make([]byte, bufferSize)
totalCount := Count{}
for {
chunk, err := fileReader.ReadChunk(buffer)
if err != nil {
if err == io.EOF {
break
} else {
panic(err)
}
}
count := GetCount(chunk)
totalCount.LineCount += count.LineCount
totalCount.WordCount += count.WordCount
}
counts <- totalCount
}和之前一样,将这些 Worker 分配给 CPU 内核:
fileReader := &FileReader{
File: file,
LastCharIsSpace: true,
}
counts := make(chan Count)
for i := 0; i < numWorkers; i++ {
go FileReaderCounter(fileReader, counts)
}
totalCount := Count{}
for i := 0; i < numWorkers; i++ {
count := <-counts
totalCount.LineCount += count.LineCount
totalCount.WordCount += count.WordCount
}
close(counts)现在来看看性能如何:
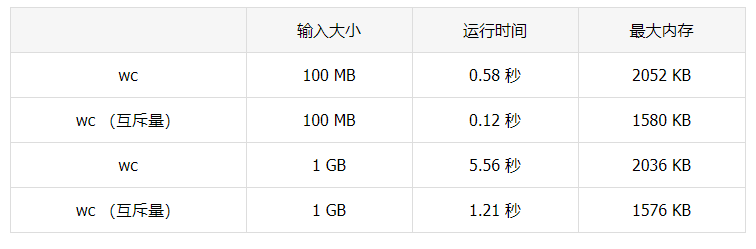
并行实现的速度是 wc 的 4.5 倍以上,并且也降低了内存的消耗。这很重要,特别在考虑到 Go 是一种垃圾收集语言的时候。
结论
本文并没有在暗示 Go 要比 C 好,但作者希望能它能证明 Go 可以代替 C 作为系统编程语言。
原文链接:https://ajeetdsouza.github.io/blog/posts/beating-c-with-70-lines-of-go/
作者丨Ajeet DSouza
译者丨马可薇
策划丨田晓旭