从Ops到NoOps,阿里文娱智能运维的关键:自动化应用容量管理

作者| 阿里文娱高级开发工程师 金呈
编辑 | 夕颜来源 | CSDN(ID:CSDNnews)
概述
- 背景
随着业务形态发展,更多的生产力集中到业务创新,这背后要求研发能力的不断升级。阿里文娱持续倾向用更加高效、稳定、低成本的方式支持快速软件交付,保障高可用。于是运维力从 “HaaS”(Handwork as a Service)到“PaaS”再到“SaaS”(System as a Service),运维生产力从 Ops 到 DevOps 再到 NoOps。
在传统应用容量管理模式下,应用、集群容量评估缺乏有效数据依据与支撑,往往牺牲效率或成本来平衡经验决策风险,另一方面,人肉决策和执行难以满足业务对稳定性和效能的追求。因此,阿里文娱急需一个能够把优酷所有应用的容量管理起来的能力。
- 目标
整体目标分成 2 个阶段,一是摸清各应用容量水平,二是为所有应用赋予弹性伸缩的能力, 最终直观看到各应用及总体资源使用率的明显提升。 
1. 单机性能
既然谈到容量问题,已知的压测方案有链路压测方案、模拟流量压测方案等。为什么还要 自研一套基于单机引流的压测方案来评估应用容量水平?
1)更接近日常真实水平; 2)无人工决策,纯机器决策单机性能瓶颈;3)全自动,比如配置成发布结束后进行单机性能压测。
2. 弹性
弹性指标选择:仅靠集群 CPU 水位弹性确实可以解决绝大多数类型应用,但若基于集群QPS 水位则可更精准的进行弹性伸缩。
1)多维度弹性指标,同时也需要支持自定义指标;2)多方位弹性方案,使用条件编排策略来达到多个弹性指标之间的协同。
技术方案
1. 全自动单机性能探索
与各接入层对接,自动配置权重完成单机引流,配合性能拐点算法支撑,完成自动识别性 能拐点并终止压测,最后一并记录单机能力值。并允许每天定时压测、发布结束压测来感知每 天、或每次发布给单机性能带来的变化,使用户更亲近自身应用的容量水平。
- 弹性伸缩
与底层交付系统联动,打造从规划,交付,计费,弹性水平扩展、回收、资源排布调度全 生命态面向业务需求的自驱动统筹调度资源管理系统。一方面,业务资源统一平台构建与维护, 挖掘空闲资源,共享弹性计算力,整体提高部署密度,降低业务单位成本;另一方面,面向不 同应用场景,自动化容量管理,按需分配,保证应用服务可用性,提高容量运维效能。
- 方案结合
全自动单机性能探索与弹性伸缩的结合框架,如下图: 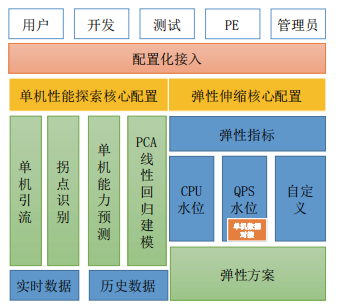
技术细节
1. 单机引流权重优化
1)调整权重就是调整单机流量,且权重越高,单机流量越高;2)增加自动化调整权重策略方法。权重优化:用于已经识别出拐点,保证下一次压测接近 MAX 权重保持平缓;权重递增:用于未触发拐点,保证下一次压测能引更多的流量。
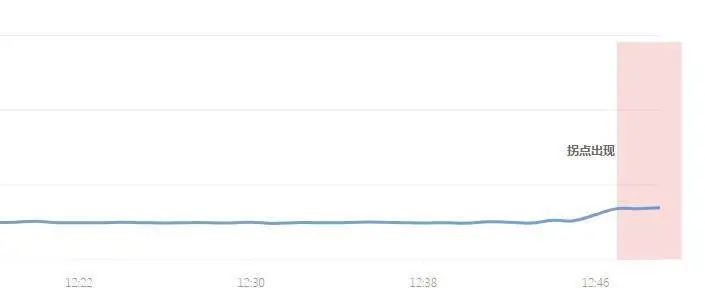
2. 响应时间拐点识别
3. 成功率拐点识别
0 错误代表 100%成功率 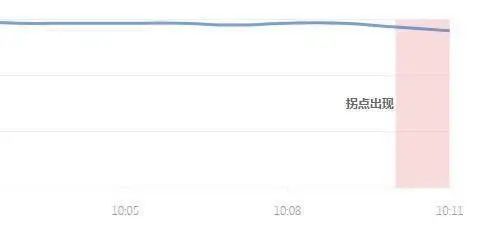
4. 拐点提取参考了“时间序列数据趋势转折点提取算法”文章
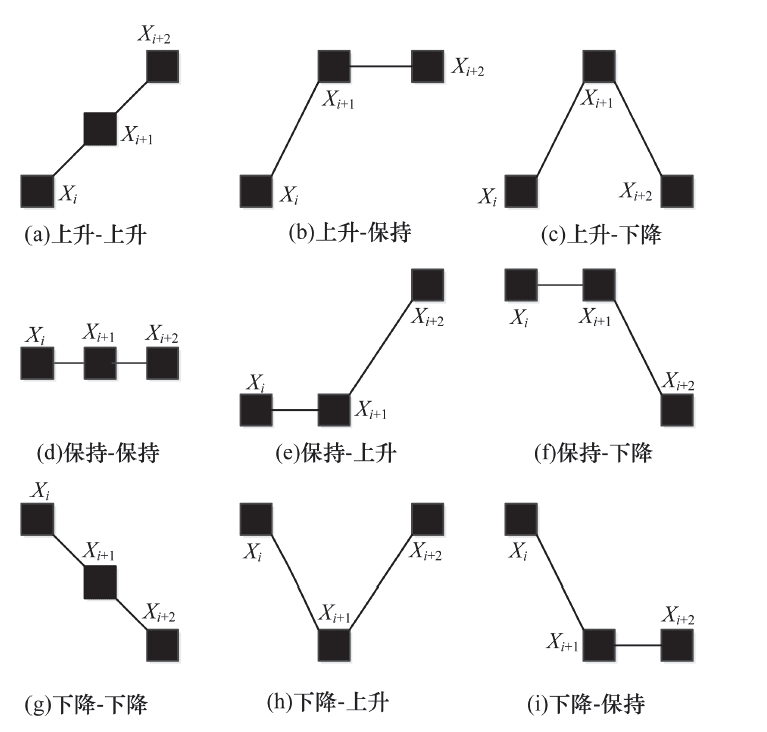
而我们通过“基于 IQR 定制多组 k 的箱线图”可以识别出上升和下降 2 种拐点,分别对应 不同的场景,如响应时间拐点识别(上升拐点识别),成功率拐点识别(下降拐点识别),而 k 的定义方式也参考近期数据。
比如某个应用日常响应时间稳定在 100-200ms 和某个应用日常响应时间稳定在 2-3ms 的 k值是不一样的,不合适的 k 用在 2-3ms 的这种数据上会导致异常识别较为频繁及不准确。
5. 单机性能预测方案
单机性能与什么有关,系统指标?如果是 JAVA 应用还和 JVM 相关指标有关?而应用本身 有会有各种池的限制,如 JVM 相关池、TOMCAT 相关池、DB 相关池、Redis 相关池、队列相 关池等,这些都可以作为预测单机性能的特征。先基于 PCA 抽象出 N 个特征,也称降维,可 将两两线性相关的因素进行整合或排出,降维后建立线性回归模型,而拟合度较高的模型将予 以采纳并进行预测。同时预测参数也需要实事求是,比如日常 CPU 区间为 2-60%,那预测参数 可以为 80%,此时若超过 100%那将毫无意义。
6. 流量驱动弹性方案
基于 CPU 指标的弹性伸缩:比如 CPU 超过 60%则执行弹性扩容,CPU 低于 20%则执行弹 性缩容。扩容与缩容允许按机器数比例进行伸缩:如按 5%的机器数进行弹性扩容。定义弹性区 间:如 10-20,机器数会在 10-20 区间变动。
一般低峰期会处在最低机器数区域,高峰则会处在最高机器数区域,基于外挂单机能力模 型。允许基于 QPS 水位指标进行弹性,可随 QPS 增加而增加机器数,反之则减少机器数。
总结
自动化容量管理与弹性伸缩的深度结合解决了当前容量预估的问题,使得资源能够被合理使用。一方面,用户专注业务层,做基于业务需求的容量规划、交付和维护,革命性改变生产关系,提高研发迭代效率;另一方面,更加细粒度的弹性伸缩,比如小时、分钟的资源的快速流转,资源粒度分解到具体硬件计算垂直伸缩,也是一种更优的解决方案,使得弹性更加迅速能做到秒级能力,进一步压缩集群密度,降低单位成本。