今日头条技术架构到底有多牛?

今日头条创立于2012年3月,到目前仅4年时间。从十几个工程师开始研发,到上百人,再到200余人。产品线由内涵段子,到今日头条,今日特卖,今日电影等产品线。
一、产品背景
今日头条是为用户提供个性化资讯客户端。下面就和大家分享一下当前今日头条的数据(据内部与公开数据综合):
- 5亿注册用户- 2014年5月1.5亿,2015年5月3亿,2016年5月份为5亿。几乎为成倍增长。
- 日活4800万用户- 2014年为1000万日活,2015年为3000万日活。
- 日均5亿PV- 5亿文章浏览,视频为1亿。页面请求量超过30亿次。
- 用户停留时长超过65分钟以上
1、文章抓取与分析
我们日常产生原创新闻在1万篇左右,包括各大新闻网站和地方站,另外还有一些小说,博客等文章。这些对于工程师来讲,写个Crawler并非困难的事。
接下来,今日头条会用人工方式对敏感文章进行审核过滤。此外,今日头条头条号目前也有为数不少的原创文章加入到了内容遴选队列中。
接下来我们会对文章进行文本分析,比如分类,标签、主题抽取,按文章或新闻所在地区,热度,权重等计算。
2、用户建模
当用户开始使用今日头条后,对用户动作的日志进行实时分析。使用的工具如下:
- Scribe- Flume- Kafka
我们对用户的兴趣进行挖掘,会对用户的每个动作进行学习。主要使用:
- Hadoop- Storm
产生的用户模型数据和大部分架构一样,保存在MySQL/MongoDB(读写分离)以及Memcache/Redis中。
随着用户量的不断扩展大,用户模型处理的机器集群数量较大。2015年前为7000台左右。其中,用户推荐模型包括以下维度:
- 1 用户订阅
- 2 标签
- 3 部分文章打散推送
此时,需要每时每刻做推荐。
3、新用户的“冷启动”
今日头条会通过用户使用的手机,操作系统,版本等“识别”。另外,比如用户通过社交帐号登录,如新浪微博,头条会对其好友,粉丝,微博内容及转发、评论等维度进行对用户做初步“画像”。 分析用户的主要参数如下:
- 关注、粉丝关系- 关系- 用户标签
除了手机硬件,今日头条还会对用户安装的APP进行分析。例如机型和APP结合分析,用小米,用三星的和用苹果的不同,另外还有用户浏览器的书签。头条会实时捕捉用户对APP频道的动作。另外还包括用户订阅的频道,比如电影,段子,商品等。
4、推荐系统
推荐系统,也称推荐引擎。它是今日头条技术架构的核心部分。包括自动推荐与半自动推荐系统两种类型:1) 自动推荐系统
- 自动候选- 自动匹配用户,如用户地址定位,抽取用户信息- 自动生成推送任务
这时需要高效率,大并发的推送系统,上亿的用户都要收到。2)半自动推荐系统
- 自动选择候选文章- 根据用户站内外动作
头条的频道,在技术侧划分的包括分类频道、兴趣标签频道、关键词频道、文本分析等,这些都分成相对独立的开发团队。目前已经有300+个分类器,仍在不断增加新的用户模型,原来的用户模型不用撤消,仍然发挥作用。 在还没有推出头条号时,内容主要是抓取其它平台的文章,然后去重,一年几百万级,并不太大。主要是用户动作日志收集,兴趣收集,用户模型收集。 资讯App的技术指标,比如屏幕滑动,用户是不是对一篇都看完,停留时间等都需要我们特别关注

5、数据存储
今日头条使用MySQL或Mongo持久化存储+Memched(Redis),分了很多库(一个大内存库),亦尝试使用了SSD的产品。 今日头条的图片存储,直接放在数据库中,分布式保存文件,读取的时候采用CDN。
6、消息推送
消息推送,对于用户: 及时获取信息。对运营来讲,能够 提⾼⽤用户活跃度。比如在今日头条推送后能够提升20%左右的DAU,如果没有推送,会影响10%左右 DAU(2015年数据)。 推送后要关注的ROI:点击率,点击量。能够监测到App卸载和推送禁用数量。 今日头条推送的主要内容包括突发与热点咨讯,有人评论回复,站外好友注册加入。 在头条,推送也是个性化:
- 频率个性化- 内容个性化- 地域- 兴趣
比如:按照城市:辽宁朝阳发生的某个新闻事件,发给朝阳本地的用户。 按照兴趣:比如京东收购一号店,发给互联网兴趣的用户。 推送平台的工具和选择,需要具备如下的标准:
- 通道,首先速度要快,但是要可控,可靠,并且节省资源- 推送的速度要快,有不同维度的策略支持,可跟踪,开发接口要友好- 推送运营的后台,反馈也要快,包括时效性,热度,工具操作方便- 对于运营侧,清晰是否确定推荐,包括推送的文案处理
因此,推送后台应该提供日报,完整的数据后台,提供A/B Test方案支持。 推送系统一部分使用自有IDC,在发送量特别大,消耗带宽较严重。可以使用类似阿里云的服务,可有效节省成本。
二、今日头条系统架构
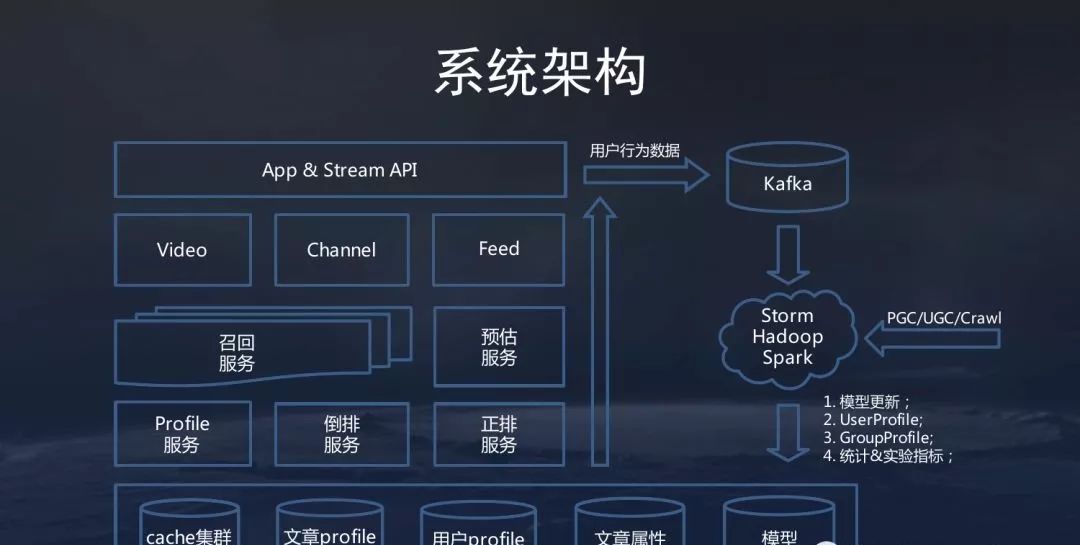
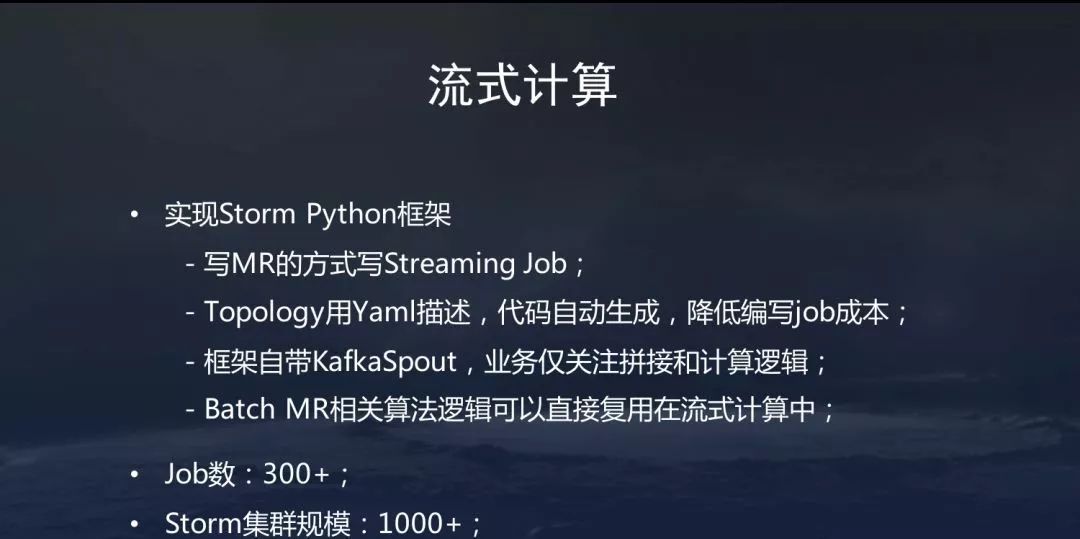


三、头条微服务架构
今日头条通过拆分子系统,大的应用拆成小应用,抽象通用层做代码复用。
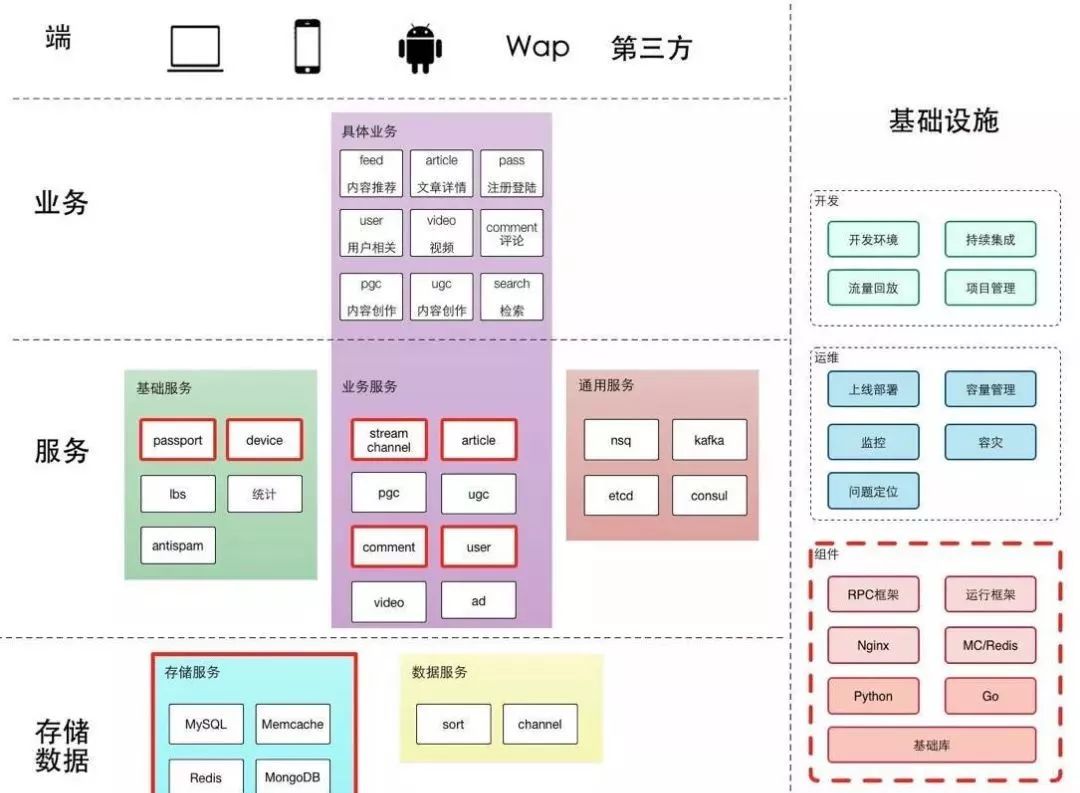
系统的分层比较典型。重点在基础设施,希望通过基础设施提高快速迭代、容灾和一系列的工作,希望各个业务团队能更快做业务上的迭代以及架构上的调整。
四、今日头条的虚拟化PaaS平台规划
通过三层实现,通过 PaaS 平台统一管理。提供通用 SaaS 服务,同时提供通用的 App 执行引擎。最底层是 IaaS 层。
IaaS 管理所有的机器,把公有云整合起来,头条有一些热点事件会全国推广推送,对网络带宽比较高,我们借助公有云,需要哪一种类型计算资源,统一抽象起来。基础设施结合服务化的思路,比如日志,监控等等功能,业务不需要关注细节就可以享受到基础设施提供的能力。
五、总结
今日头条重要的部分在于:数据生成与采集数据传输。Kafka做消息总线连接在线和离线系统。数据入库。数据仓库、ETL(抽取转换加载)数据计算。数据仓库中的数据表如何能被高效的查询很关键,因为这会直接关系到数据分析的效率。常见的查询引擎可以归到三个模式中,Batch 类、MPP 类、Cube 类,头条在 3 种模式上都有所应用。
可可| 开发者前线