Android 画面显示流程分析 (3)
5 . BufferQueue
BufferQueue 要解决的是生产者和消费者的同步问题,应用程序生产画面,SurfaceFlinger 消费画面;SurfaceFlinger 生产画面而 HWC Service 消费画面。用来存储这些画面的存储区我们称其为帧缓冲区 buffer, 下面我们以应用程序作为生产者,SurfaceFlinger 作为消费者为例来了解一下 BufferQueue 的内部设计。
5.1. Buffer State 的切换
在 BufferQueue 的设计中,一个 buffer 的状态有以下几种:
FREE :表示该 buffer 可以给到应用程序,由应用程序来绘画DEQUEUED: 表示该 buffer 的控制权已经给到应用程序侧,这个状态下应用程序可以在上面绘画了QUEUED: 表示该 buffer 已经由应用程序绘画完成,buffer 的控制权已经回到 SurfaceFlinger 手上了ACQUIRED: 表示该 buffer 已经交由 HWC Service 去合成了,这时控制权已给到 HWC Service 了
Buffer 的初始状态为 FREE, 当生产者通过 dequeueBuffer 来申请 buffer 成功时,buffer 状态变为了 DEQUEUED 状态, 应用画图完成后通过 queueBuffer 把 buffer 状态改到 QUEUED 状态, 当 SurfaceFlinger 通过 acquireBuffer 操作把 buffer 拿去给 HWC Service 合成, 这时 buffer 状态变为 ACQUIRED 状态,合成完成后通过 releaseBuffer 把 buffer 状态重新改为 FREE 状态。状态切换如下图所示:
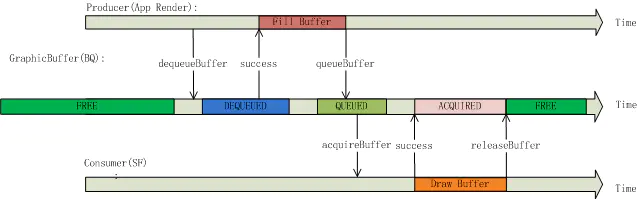
从时间轴上来看一个 buffer 的状态总是这样循环变化:
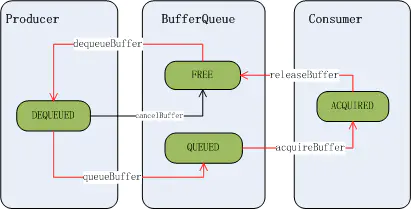
FREE->DEQUEUED->QUEUED->ACQUIRED->FREE
应用程序在 DEQUEUED 状态下绘画,而 HWC Service 在状态为 ACQUIRED 状态下做合成:
5.2. BufferSlot
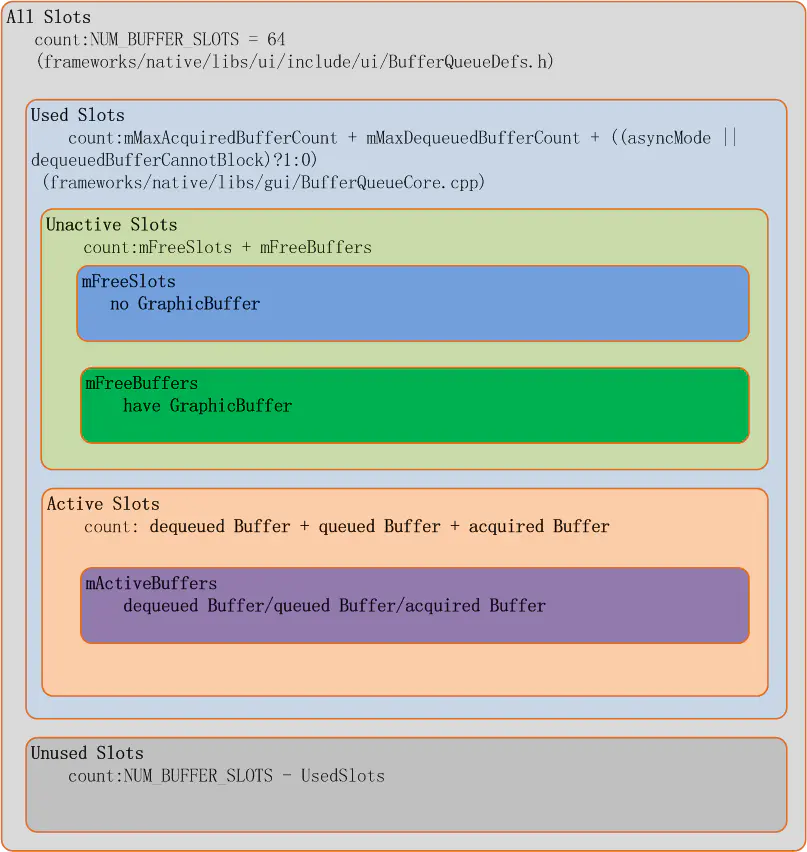
每一个应用程序的图层在 SurfaceFlinger 里称为一个 Layer, 而每个 Layer 都拥有一个独立的 BufferQueue, 每个 BufferQueue 都有多个 Buffer,Android 系统上目前支持每个 Layer 最多 64 个 buffer, 这个最大值被定义在 frameworks/native/gui/BufferQueueDefs.h, 每个 buffer 用一个结构体 BufferSlot 来代表。
每个 BufferSlot 里主要有如下重要成员:
struct BufferSlot{
......
BufferState mBufferState;//代表当前Buffer的状态 FREE/DEQUEUED/QUEUED/ACQUIRED
....
sp<GraphicBuffer> mGraphicBuffer;//代表了真正的buffer的存储空间
......
uint64_t mFrameNumber;//表示这个slot被queued的编号,在应用调dequeueBuffer申请slot时会参考该值
......
sp<Fence> mFence;//在Fence一章再来看它的作用
.....
}64 个 BufferSlot 可以分成两个部分,used Slots 和 Unused Slots, 这个比较好理解,就是使用中的和未被使用的,而 Used Slots 又可以分为 Active Slots 和 UnActive Slots, 处在 DEQUEUED, QUEUED, ACQUIRED 状态的被称为 Active Slots, 剩下 FREE 状态的称为 UnActive Slots, 所以所有 Active Slots 都是正在有人使用中的 slot, 使用者可能是生产者也可能是消费者。而 FREE 状态的 Slot 根据是否已经为其分配过内存来分成两个部分, 一是已经分配过内存的,在 Android 源码中称为 mFreeBuffers, 没有分配过内存的称为 mFreeSlots, 所以如果我们在代码中看到是从 mFreeSlots 里拿出一个 BufferSlot 那说明这个 BufferSlot 是还没有配置 GraphicBuffer 的, 这个 slot 可能是第一次被使用到。其分类如下图所示:
我们来看一下,应用上帧时 SurfaceFlinger 是如何管理分配这些 Slot 的。
应用侧对图层 buffer 的操作接口是如下文件:
frameworks/native/libs/gui/Surface.cpp
应用第一次 dequeueBuffer 前会通过 connect 接口和 SurfaceFlinger 建立 “连接”:
int Surface::connect(int api, const sp<IProducerListener>&listener, bool reportBufferRemoval){
ATRACE_CALL();//应用第一次上帧前可以在trace 中看到这个
......
int err = mGraphicBufferProducer->connect(listener, api, mProducerControlledByApp, &output);//这里通过binder调用和SurfaceFlinger建立联系
......
}应用在第一次 dequeueBuffer 时会先调用 requestBuffer:
int Surface::dequeueBuffer(android_native_buffer_t** buffer, int* fenceFd) {
ATRACE_CALL();//这里可以在systrace中看到
......
//这里尝试去dequeueBuffer,因为这时SurfaceFlinger对应Layer的slot还没有分配buffer,这时SurfaceFlinger会回复的flag会有BUFFER_NEEDS_REALLOCATION
status_t result = mGraphicBufferProducer->dequeueBuffer(&buf, &fence, reqWidth, reqHeight,
reqFormat, reqUsage, &mBufferAge,
enableFrameTimestamps?&frameTimestamps:nullptr);
......
if((result & IGraphicBufferProducer::BUFFER_NEEDS_REALLOCATION) || gbuf == nullptr) {
......
//这里检查到dequeueBuffer返回的结果里带有BUFFER_NEEDS_REALLOCATION标志就会发出一次requestBuffer
result = mGraphicBufferProducer->requestBuffer(buf, &gbuf);
......
}
......
}在 SurfaceFlinger 这端,第一次收到 dequeueBuffer 时发现分配出来的 slot 没有 GraphicBuffer, 这时会去申请对应的 buffer:
status_t BufferQueueProducer::dequeueBuffer(int* outSlot, sp<android::Fence>* outFence,
uint32_t width, uint32_t height, PixelFormat format,
uint64_t usage, uint64_t* outBufferAge,
FrameEventHistoryDelta* outTimestamps) {
if ((buffer == NULL) ||
buffer->needsReallocation(width, height, format, BQ_LAYER_COUNT, usage))//检查是否已分配了GraphicBuffer
{
......
returnFlags |= BUFFER_NEEDS_REALLOCATION;//发现需要分配buffer,置个标记
}
......
if (returnFlags & BUFFER_NEEDS_REALLOCATION) {
......
//新创建一个新的GraphicBuffer给到对应的slot
sp<GraphicBuffer> graphicBuffer = new GraphicBuffer(
width, height, format, BQ_LAYER_COUNT, usage,
{mConsumerName.string(), mConsumerName.size()});
......
mSlots[*outSlot].mGraphicBuffer = graphicBuffer;//把GraphicBuffer给到对应的slot
......
}
......
return returnFlags;//注意在应用第一次请求buffer, dequeueBuffer返回时对应的GraphicBuffer已经创建完成并给到了对应的slot上,但返回给应用的flags里还是带有BUFFER_NEEDS_REALLOCATION标记的
}应用侧收到带有 BUFFER_NEEDS_REALLOCATION 标记的返回结果后就会调 requestBuffer 来获取对应 buffer 的信息:
status_t BufferQueueProducer::requestBuffer(int slot, sp<GraphicBuffer>* buf) {
ATRACE_CALL();
......
mSlots[slot].mRequestBufferCalled = true;
*buf = mSlots[slot].mGraphicBuffer;
return NO_ERROR;
}从上面可以看出 requestBuffer 的主要作用就是把 GraphicBuffer 传递到应用侧,这里思考一个问题,既然 SurfaceFlinger 在响应 dequeueBuffer 时就已经为 slot 新创建了 GraphicBuffer, 为什么还需要应用侧再次调用 requestBuffer 时再把 GraphicBuffer 传给应用呢?为什么 dequeueBuffer 不直接返回呢?这不是多花费一次跨进程通信的时间吗?为什么设计成了这个样子呢?
我们再来看一下应用侧接口 dequeueBuffer 的函数设计:
frameworks/native/libs/gui/IGraphicBufferProducer.h
virtual status_t dequeueBuffer(int* buf, sp<Fence>* fence, uint32_t width, uint32_t height,
PixelFormat format, uint64_t usage, uint64_t* outBufferAge,
FrameEventHistoryDelta* outTimestamps);注意第一个参数只是返回一个 int 值,它表示的是 64 个 slot 里的哪一个 slot, 其他参数里也不会返回这个 slot 所对应的 GraphicBuffer 的信息,但这个 slot 拿到应用侧后,应用是要拿到确确实实的 GraphicBuffer 才能把共享内存 mmap 到自已进程空间,才能在上面绘画。而显然这个接口的设计并不会带来 GraphicBuffer 的信息,那设计之初为什么不把这个信息放进来呢?因为这个接口调用太频繁了,比如在 90FPS 的设备上,一秒钟该接口要执行 90 次,太频繁了,而且这个信息只需要传递一次就可以了,如果每次这个接口都要带上 GraphicBuffer 的信息,传输了很多冗余数据,所以不如加入一个新的 api(requestBuffer)来完成 GraphicBuffer 传递的事情.
应用侧在 requestBuffer 后会拿到 GraphicBuffer 的信息,然后会通过 importBuffer 在本进程内通过 binder 传过来的 parcel 包把 GraphicBuffer 重建出来:
frameworks/native/libs/ui/GraphicBuffer.cpp
status_t GraphicBuffer::unflatten(
void const*& buffer, size_t& size, int const*& fds, size_t& count) {
......
if (handle != 0) {
buffer_handle_t importedHandle;
//获取从SurfaceFlinger传过来的buffer
status_t err = mBufferMapper.importBuffer(handle, uint32_t(width), uint32_t(height),
uint32_t(layerCount), format, usage, uint32_t(stride), &importedHandle);
......
}
......
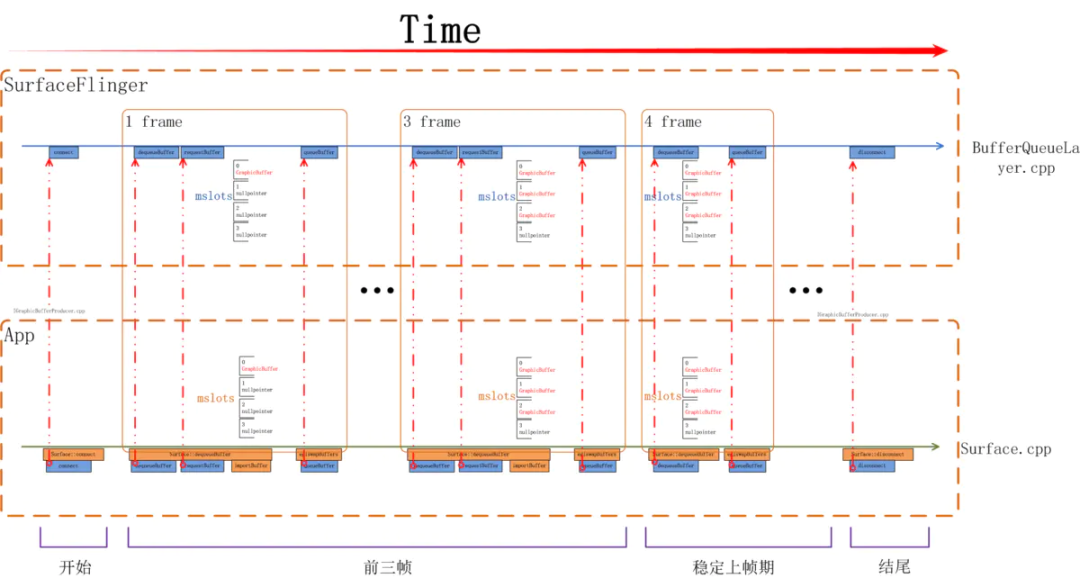
}如下图所示,从 App 侧看,前三帧都会有 requestBuffer, 都会有 importBuffer,在第 4 帧时就没有 requestBuffer/importBuffer 了,因为我们当前系统一共使用了三个 buffer, 从 systrace 上可以看到这个区别:
当一个 surface 被创建出来开始上帧时其流程如下图所示,应用所使用的画布是在前三帧被分配出来的,从第四帧开始进入稳定上帧期,这时会重复循环利用前三次分配的 buffer。

思考一个问题,在三个 buffer 的系统中一定是前三帧中触发分配 GraphicBuffer 吗?如果某个应用有一个 SurfaceView 自已决定上帧的帧率,而这个帧率非常低,如低到一秒一帧,那前三秒会把三个 Buffer 分配出来吗?我们需要了解一下多 buffer 下 SurfaceFlinger 的管理策略是什么。
5.3. Buffer 管理
前文提到了每个图层 Layer 都有最多 64 个 BufferSlot, 如下图所示,每个 BufferSlot 都会记录有自身的状态(BufferState), 以及自已的 GraphicBuffer 指针 mGraphicBuffer.
但不是每个 Layer 都能使用到那么多,每个 Layer 最多可使用多少个 Layer 是在这里设置的:

frameworks/native/services/surfaceflinger/BufferQueueLayer.cpp
frameworks/native/services/surfaceflinger/BufferQueueLayer.cpp
void BufferQueueLayer::onFirstRef() {
......
// BufferQueueCore::mMaxDequeuedBufferCount is default to 1
if (!mFlinger->isLayerTripleBufferingDisabled()) {
mProducer->setMaxDequeuedBufferCount(2);//3 buffer时这里设为2, 是因为在BufferQueueCore那里会+1
}
......
}我们重新回忆下 BufferSlot 的几个状态,FREE ,代表该 buffer 可以给到应用程序,由应用程序来绘画, 这样的 Slot SurfaceFlinger 会根据是否有给它分配有 GraphicBuffer 分到两个队列里, 有 GraphicBuffer 的分配到 mFreeBuffers 里, 没有 GraphicBuffer 的分配到 mFreeSlots 里;当应用申请走一个 Slot 时,该 Slot 状态会切换到 DEQUEUED 状态,该 Slot 会被放入 mActiveBuffers 队列里;当应用绘画完成后 Slot 状态会切到 QUEUED 状态,所有 QUEUED 状态的 Slot 会被放入 mQueue 队列里;当一个 Slot 被 HWC Service 拿去合成后状态会变为 ACQUIRED, 这个 Slot 会被从 mQueue 队列中取出放入 mActiveBuffers 队列里;
我们先来看一个 BufferSlot 管理的场景:
Time1: 在上图中,初始状态下,有 0, 1, 2 这三个 BufferSlot, 由于它们都没有分配过 GraphicBuffer, 所以它们都位于 mFreeSlots 队列里,当应用来 dequeueBuffer 时,SurfaceFlinger 会先检查在 mFreeBuffers 队列中是否有 Slot, 如果有则直接分配该 Slot 给应用。显然此时 mFreeBuffers 里是空的,这时 Surfaceflinger 会去 mFreeSlots 里去找出第一个 Slot, 这时就找到了 0 号 Slot, dequeueBuffer 结束时应用就拿到了 0 号 Slot 的使用权,与此同时 SurfaceFlinger 也会为 0 号 Slot 分配 GraphicBuffer, 之后应用将通过 requestBuffer 和 importBuffer 来获取到该 Slot 的实际内存空间。
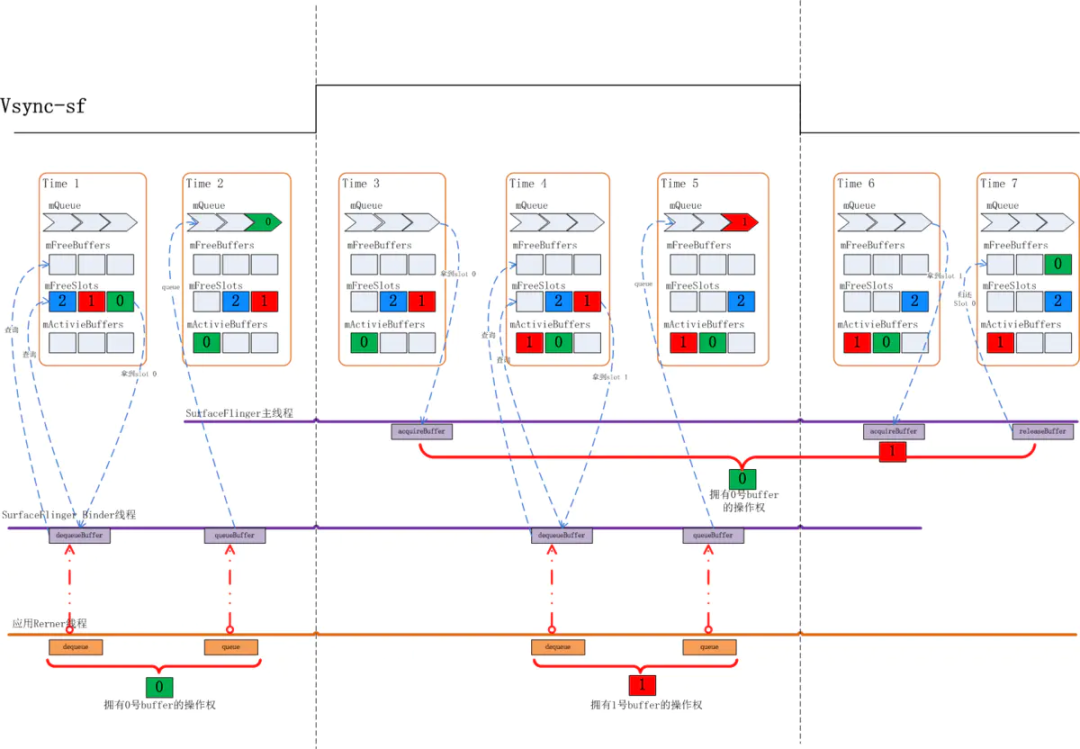
应用 dequeueBuffer 之后 0 号 Slot 切换到 DEQUEUED 状态,并被放入 mActiveBuffers 列表。
Time2: 应用完成绘制后通过 queueBuffer 来提交绘制好的画面,完成后 0 号 Slot 状态变为 QUEUED 状态,放入 mQueue 队列,此时 1,2 号 Slot 还停留在 mFreeSlots 队列中。
Time3: 上面这个状态会持续到下一个 Vsync-sf 信号到来,当 Vsync-sf 信号到来时,SurfaceFlinger 主线程会检查 mQueue 队列中是否有 Slot, 有就意味着有应用上帧,这时它会把该 Slot 从 mQueue 中取出放入 mActiveBuffers 队列,并将 Slot 的状态切换到 ACQUIRED, 代表这个 Slot 已被拿去做画面合成。那么这之后 0 号 Slot 被从 mQueue 队列拿出放入 mActivieBuffers 里。
Time4: 接下来应用继续调用 dequeueBuffer 申请 buffer, 此时 0 号 Slot 在 mActiveBuffers 里,1,2 号在 mFreeSlots 里,SurfaceFlinger 仍然是先检查 mFreeBuffers 里有没有 Slot, 发现还是没有,再检查 mFreeSlots 里是否有,于是取出了 1 号 Slot 给到应用侧,同时 1 号 Slot 状态切换到 DEQUEUED 状态, 放入 mActiveBuffers 里,
Time5:1 号 Slot 应用绘画完毕,通过 queueBuffer 提交上来,这时 1 号 Slot 状态由 DEQUEUED 状态切换到了 QUEUED 状态,进入 mQueue 队列,之后将维持该状态直到下一个 Vsync-sf 信号到来。
Time6: 此时 Vsync-sf 信号到来,发现 mQueue 中有个 Slot 1, 这时 SurfaceFlinger 主线程会把它取出,把状态切换到 ACQUIRED, 并放入 mActiveBuffers 里。
Time7: 这时 0 号 Slot HWC Service 使用完毕,通过 releaseBuffer 还了回来,0 号 Slot 的状态将从 ACQUIRED 切换回 FREE, Surfaceflinger 会把它从 mActivieBuffers 里拿出来放入 mFreeBuffers 里。注意这时放入的是 mFreeBuffers 里而不是 mFreeSlots 里,因为此时 0 号 Slot 是有 GraphicBuffer 的。
在上述过程中 SurfaceFlinger 收到应用 dequeueBuffer 请求时处在 FREE 状态的 Slot 都还没有分配过 GraphicBuffer, 由之前的讨论我们知道这通常发生在一个 Surface 的前几帧时间内。如 3 buffer 下的前三帧。
我们再来看一下申请 buffer 时 mFreeBuffers 里有 Slot 时的情况:
Time11: 当下的状态是 0,1 两个 Slot 都在 mFreeBuffers 里,2 号 Slot 在 mActiveBuffers 里,这时应用来 dequeueBuffer
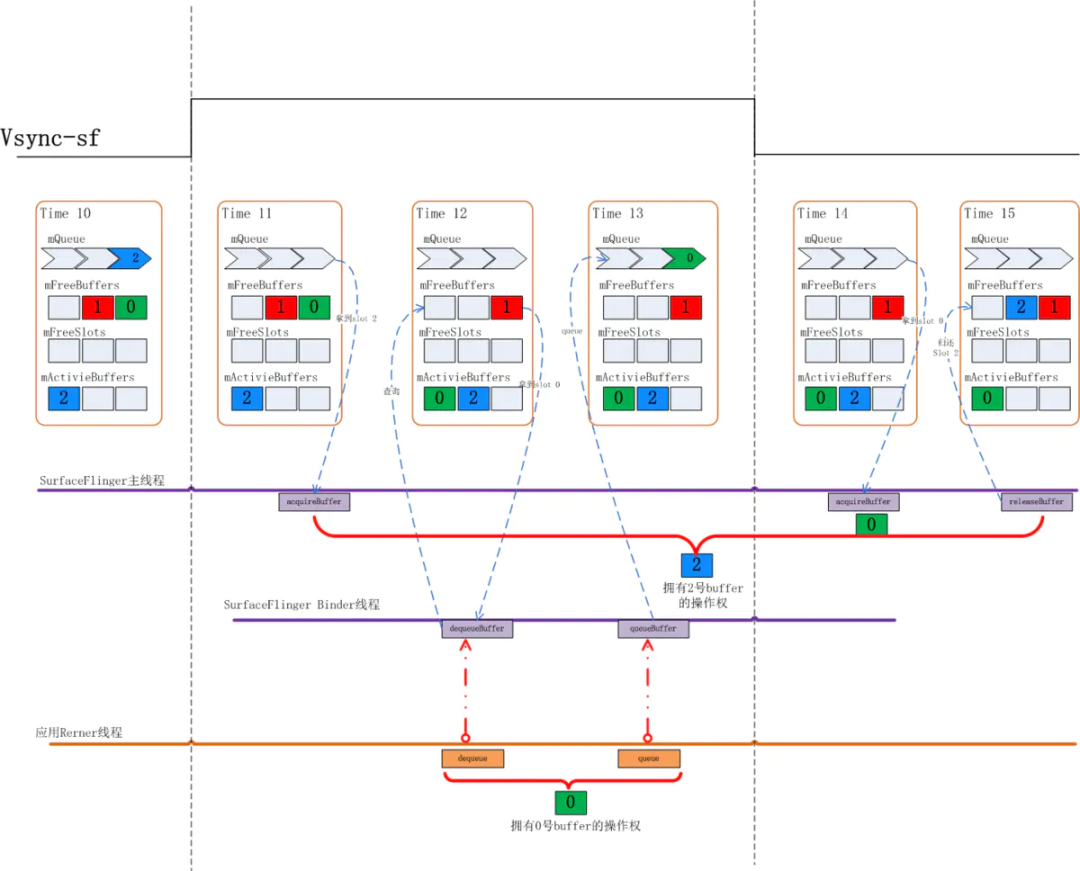
Time12: SurfaceFlinger 仍然会先查看 mFreeBuffers 列表看是否有可用的 Slot, 发现 0 号可用,于是 0 号 Slot 状态由 FREE 切换到 DEQUEUED 状态,并被放入 mActiveBuffers 里
Time13: 应用对 0 号 Slot 的绘图完成后提交上来,这时状态从 DEQUEUED 切换到 QUEUED 状态,0 号 Slot 被放入 mQueue 队列,之后会维持该状态直到下一下 Vsync-sf 信号到来
Time14: 这时 Vsync-sf 信号到来,SurfaceFlinger 主线程中检查 mQueue 队列中是否有 Slot, 发现 0 号 Slot, 于是通过 aquireBuffer 操作把 0 号 Slot 状态切换到 ACQUIRED
这个过程中应用申请 buffer 时已经有处于 FREE 状态的 Slot 是分配过 GraphicBuffer 的,这种情况多发生在 Surface 的稳定上帧期。
再来关注一下 acquireBuffer 和 releaseBuffer 的过程:
Time 23: 当前状态 mQueue 里有两个 buffer
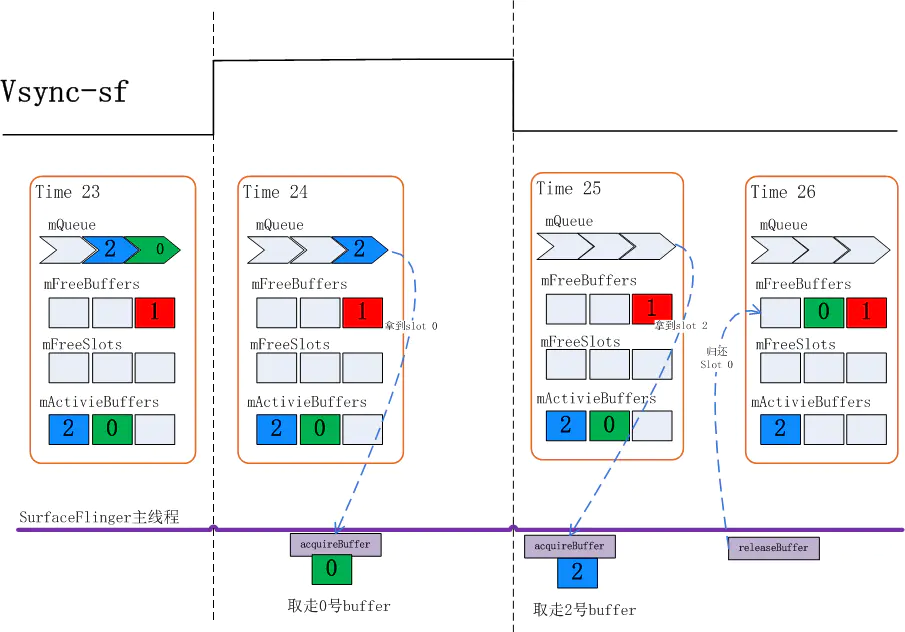
Time 24:Vsync-sf 信号到达,从 mQueue 队列里取走了 0 号 Slot,
Time 25: 再一次 Vsync-sf 到来,这时 SurfaceFlinger 会先查看 mQueue 队列是否有 buffer,发现有 2 号 Slot, 会先取走 2 号 Slot
Time 26: 此时 0 号 Slot 已经被 HWC Service 使用完毕,需要把 Slot 还回来,0 号 Slot 在此刻进入 mFreeBuffers 队列。
这里需要注意的是两个时序:
- 每次 Vsync-sf 信号到来时总是先查看 mQueue 队列看是否有 Layer 上帧,然后才会走到 releaseBuffer 把 HWC Service 使用的 Slot 回收回来
- 本次 Vsync-sf 被 aquireBuffer 取走的 Slot 总是会在下一个 Vsync-sf 时才会被 release 回来 由上述过程不难看出,如果应用上帧速度较慢,比如其上帧周期时长大于两倍屏幕刷新周期时,每次应用来 dequeueBuffer 时前一次 queueBuffer 的 BufferSlot 都已经被 release 回来了,这时总会在 mFreeBuffers 里找到可用的,那么就不需要三个 Slot 都分配出 GraphicBuffer.
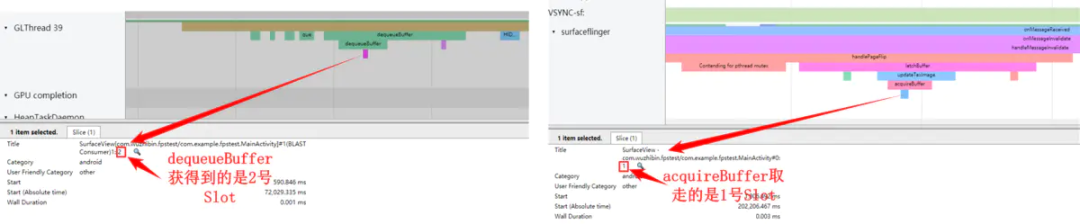
在应用上帧过程中所涉及到的 BufferSlot 我们可以通过 systrace 来观察:
image-20210917211102193.png 这两个图中显示可以从 systrace 中看到每次 dequeueBuffer 和 acquireBuffer 所操作到的 Slot 是哪个,当然 releaseBuffer 也可以在 systrace 上找到:
从 trace 里我们还应注意到,releaseBuffer 是在 postComposition 里调用到的,这段代码如下:
frameworks/native/services/surfaceflinger/surfaceflinger.cpp
void SurfaceFlinger::postComposition(){
ATRACE_CALL();
......
for(auto& layer:mLayersWithQueuedFrames){//这里只要主线程执行到这个postComposition函数就一定会让集合中的layer去执行releasePendingBuffer, 而这个releasePendingBuffer里就会调用到releaseBuffer
layer->releasePendingBuffer(dequeueReadyTime);
}
......
}mLayersWithQueuedFrames 里的 Layer 是在这里被加入进来的:
bool SurfaceFlinger::handlePageFlip(){
......
mDrawingState.traverse([&](Layer* layer){
.......
if(layer != nullptr && layer->hasReadyFrame()){//这里是判断这个Layer是否有buffer更新,也就是mLayersWithQueuedFrames里放的是有上帧的layer
......
mLayersWithQueuedFrames.push_back(layer);
......
}
.......
});
......
}在 Layer 的 releasePendingBuffer 里会把对应的 Slot 的状态切到 FREE 状态,切换到 FREE 状态后,是很可能被应用 dequeueBuffer 获取到的,那么怎么能确定 buffer 已经被 HWC Service 使用完了呢?如果 HWC Service 还没有使用完成,而应用申请到了这个 buffer,buffer 中的数据会出错,怎么解决这个问题呢,这就要靠我们下一章要讨论的 Fence 来解决。
我们再从帧数据更新的流程上来看下 bufferSlot 的管理,从 Systrace(屏幕刷新率为 90HZ)上可以观察到的应用上帧的全景图:
首先应用(这里是以一个 SurfaceView 上帧为例)通过 dequeueBuffer 拿到了 BufferSlot 0, 开始第 1 步绘图,绘图完成后通过 queueBuffer 将 Slot 0 提交到 SurfaceFlinger, 下一个 Vsync-sf 信号到达后,开始第 2 步图层处理,这时 SurfaceFlinger 通过 aquireBuffer 把 Slot 0 拿去给到 HWC Service,与此同时进入第 3 步 HWC Service 开始把多个图层做合成,合成完成后通过 libdrm 提供的接口通知 DRM 模块通过 DSI 传输给 DDIC, Panel 通过 Disp Scan Gram 把图像显示到屏幕。
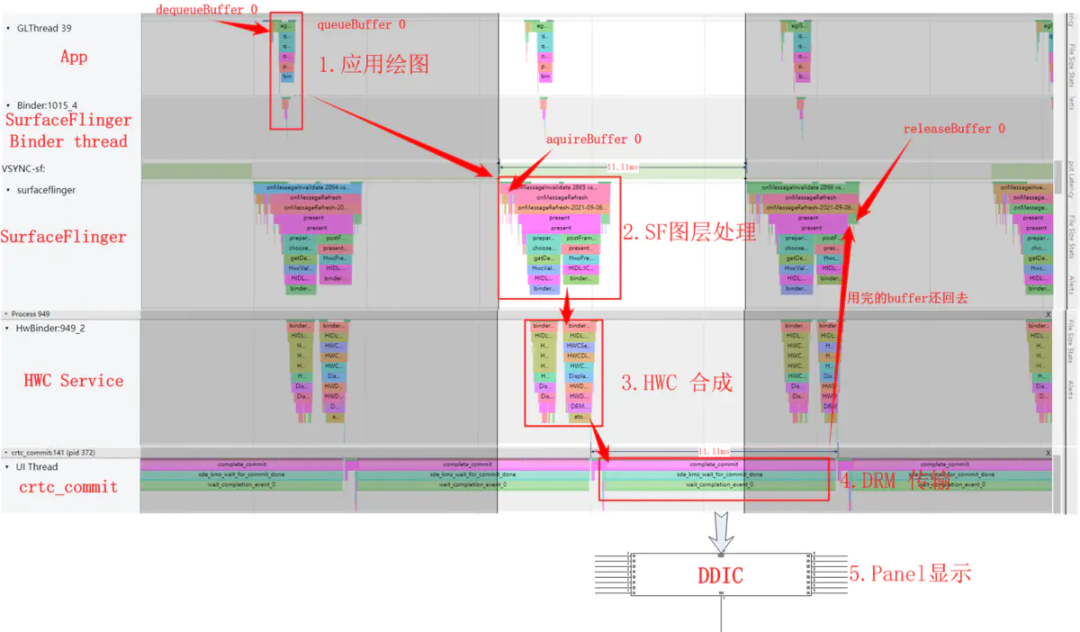
5.4. 代码接口
以应用为生产者 SurfaceFlinger 为消费者为例,BufferQueue 的 Slot 管理核心代码如 BufferQueueCore、BufferQueueProducer、BufferQueueConsumer 组成, 生产者这边还有一个 Surface 它是应用侧操作 BufferQueue 的接口:
相关代码路径如下:
Surface.cpp (frameworks\native\libs\gui)
BufferQueueCore.cpp (frameworks\native\libs\gui)
BufferQueueProducer.cpp (frameworks\native\libs\gui)
BufferQueueConsumer.cpp (frameworks\native\libs\gui)
IGraphicBufferProducer.cpp (frameworks\native\libs\gui)
IGraphicBufferConsumer.cpp (frameworks\native\libs\gui)
IConsumerListener.h (frameworks\native\libs\gui\include\gui)由于 Android 规定,BufferQueue 的 buffer 必须是在 Consumer 侧来分配,所以 BufferQueue 的核心 Slot 管理代码是在 SurfaceFlinger 进程空间内执行的,它们关系可以用如下图来表示:
相关代码路径:
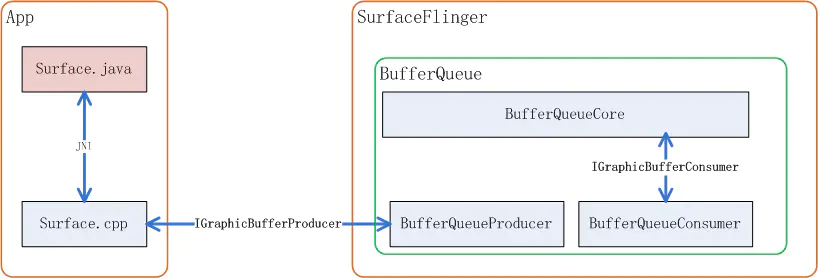
IGraphicBufferProducer 用来规定了 BufferQueue 向生产者提供的接口有哪些,比如请求 buffer 用到的 dequeueBuffer, 提交 buffer 用到的 queueBuffer 等等:
class IGraphicBufferProducer : public RefBase {
......
virtual status_t connect(const sp<IProducerListener>& listener,
int api, bool producerControlledByApp, QueueBufferOutput* output) = 0;
virtual status_t requestBuffer(int slot, sp<GraphicBuffer>* buf) = 0;
virtual status_t dequeueBuffer(int* slot, sp<Fence>* fence, uint32_t w, uint32_t h,
PixelFormat format, uint64_t usage, uint64_t* outBufferAge,
FrameEventHistoryDelta* outTimestamps) = 0;
virtual status_t queueBuffer(int slot, const QueueBufferInput& input,
QueueBufferOutput* output) = 0;
virtual status_t disconnect(int api, DisconnectMode mode = DisconnectMode::Api) = 0;
......
}connect 接口是在开始时上帧前调用一次,主要用来让生产者和消费者沟通一些参数,比如 api 版本,buffer 的尺寸,个数等;disconnect 用于在生产者不再生产断开连接,用以通知消费端清理一些资源。
IGraphicBufferConsumer 则规定了消费者和 BufferQueueCore 的接口有哪些,比如查询从 mQueue 队列中取出 buffer,和还 buffer 到 BufferQueue:
class IGraphicBufferConsumer : public RefBase {
......
virtual status_t acquireBuffer(BufferItem* buffer, nsecs_t presentWhen,
uint64_t maxFrameNumber = 0) = 0;
virtual status_t releaseBuffer(int buf, uint64_t frameNumber, EGLDisplay display,
EGLSyncKHR fence, const sp<Fence>& releaseFence) = 0;
......
}5.5. 本章小结
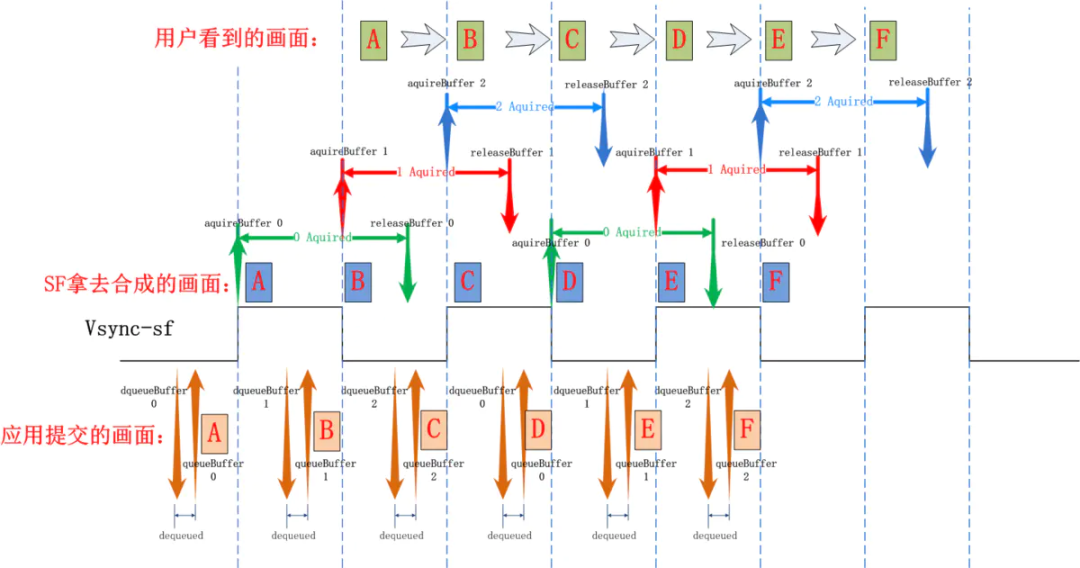
让我们用一张图来总结说明一下在 Triple Buffer 下应用连续上帧过程中三个 buffer 的使用情况,以及在此过程中应用, SurfaceFlinger 是如何配合的:
应用在每个 Vsync 信号到来后都会通过 dequeueBuffer/queueBuffer 来申请 buffer 和提交绘图数据,Surfaceflinger 都会在下一个 vsync 信号到来时取走 buffer 去做合成和显示, 并在下一下个 vsync 时将 buffer 还回来,再次循环。
6 . Fence
Fence 这个英文单词通常代表栅栏,篱笆,围墙,代表了此处是否可以通行。它是内核提供的不同硬件间同步机制,在 userspace 层我们可以将它视为是一把锁,它代表了某个硬件对共享资源的占用情况。
6.1. 为什么要有 Fence
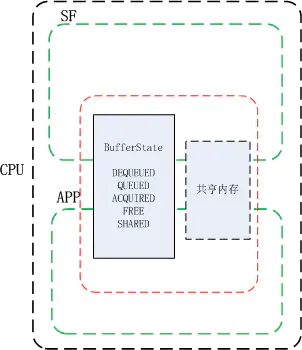
一般凡是共享的资源都要建立一个同步机制来管理,比如在多线程编程中对临界资源的通过加锁实现互斥访问,再比如 BufferQueue 中 Surfaceflinger 和应用对共享内存(帧缓冲)的访问中有 bufferstate 来标识共享内存控制权的方法来做同步。没有同步机制的无序访问极可能造成数据混乱。
上面图中的 BufferState 的方式只是解决了在 CPU 管理之下,当下共享内存的控制权归属问题,但当共享资源是在两个硬件之中时,情况就不同了,比如当一个帧缓冲区共享内存给到 GPU 时,GPU 并不清楚 CPU 还有没有在使用它,同样地,当 GPU 在使用共享内存时,CPU 也不清楚 GPU 是否已使用完毕,如下面这个例子:
CPU 调用 OpenGL 函数绘图过程的一个简化版流程如上图所示,首先 CPU 侧调用 glClear 清空画布,再调用 glXXX()来画各种各样的画面,对于 CPU 来讲在 glXXX () 执行完毕后,它的绘图工作已经完成了。但其实 glXXX()的具体工作是由 GPU 来完成的,CPU 侧的 glXXX () 只是在向 GPU 传达任务而已,任务传达完并不意味着任务已经完成了。真正任务做完是在 GPU 把 glXXX () 所对应的工作做完才是真正的任务完成了。从 CPU 下达完任务到 GPU 完成任务间存在时差,而且这个时差受 GPU 工作频率影响并不是一个定值。在 OpenGL 的语境中 CPU 可以通过 glFilish () 来等待 GPU 完成所有工作,但这显然浪费了 CPU 本可以并行工作的时间,这段时间 CPU 没有用来做别的事情。
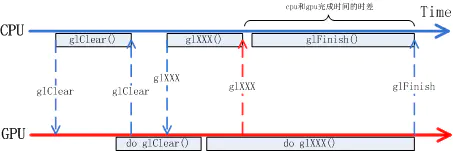
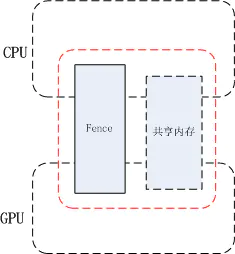
在上面的例子中 CPU 下达了要在画布上绘画的指令给 GPU, 而 GPU 什么时候画完时间是不确定的,这里的画布就是共享资源,CPU 和 GPU 的工作完全是异步的。Fence 提供了一种方式来处理不同硬件对共享资源的访问控制。
我们可以这样来理解 Fence 的工作原理: Fence 是一个内核 driver, 对一个 Fence 对象有两种操作, signal 和 wait, 当生产者(App)向 GPU 下达了很多绘图指令(drawCall)后 GPU 开始工作,这里 CPU 就认为绘图工作已经完成了,之后把创建的 Fence 对象通过 binder 通知给消费者(SurfaceFlinger),SurfaceFlinger 收到通知后,此时 SurfaceFlinger 并不知道 GPU 是否已经绘图完毕,即 GPU 是否已对共享资源访问完毕,消费者先通过 Fence 对象的 wait 方法等待,如果 GPU 绘图完成会调用 Fence 的 signal, 这时消费者就会从 Fence 对象的 wait 方法中跳出。即 wait 方法结束时就是 GPU 工作完成时。这个 signal 由 kernel driver 来完成。有了 Fence 的情况下,CPU 在完成自已的工作后就可以继续做别的事情,到了真正要使用共享资源时再通过 Fence wait 来和 GPU 同步,尽最大可能做到了让不同硬件并行工作。
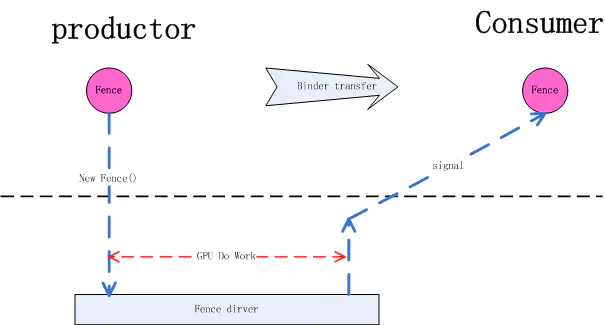
6.2. 与 BufferQueue 协作方式
我们以 App(productor)和 SurfaceFlinger (Consumer) 间的交互来看下 Fence 在其中的作用:
首先 App 通过 dequeueBuffer 获得某一 Slot 的使用权,这时 Slot 的状态切换到 DEQUEUED 状态,随着 dequeueBuffer 函数返回的还有一个 releaseFence 对象,这时因为 releaseFence 还没有 signaled, 这意味着虽然在 CPU 这边已经拿到了 buffer 的使用权,但别的硬件还在使用这个 buffer, 这时的 GPU 还不能直接在上面绘画,它要等 releaseFence signaled 后才能绘画。接下来我们先假设 GPU 的工作花费的时间较长,在它完成之前 CPU 侧 APP 已经完成了 queueBuffer 动作,这时 Slot 的状态已切换为 QUEUED 状态,或者 vsync 已经到来状态变为 ACQUIRED 状态, 这在 CPU 侧代表该 buffer 给 HWC 去合成了,但这时 HWC 的硬件 MDP 还不能去读里面的数据,它还需要等待 acauireFence 的 signaled 信号,只有等到了 acquireFence 的 signaled 信号才代表 GPU 的绘画工作真正做完了,GPU 已经完成了对帧缓冲区的访问,这时 HWC 的硬件才能去读帧缓冲区的数据,完成图层合成的工作。
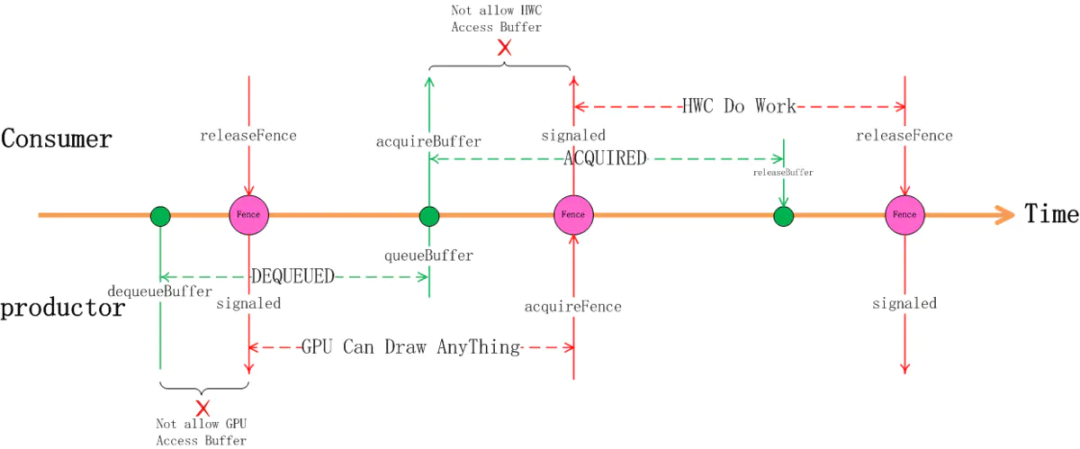
同样地,当 SurfaceFlinger 执行到 releaseBuffer 时,并不能代表 HWC 已经完全完成合成工作了,很有可能它还在读取缓冲区的内容做合成, 但不妨碍 releaseBuffer 的流程执行,虽然 HWC 还在使用缓冲区做合成,但帧缓冲区的 Slot 有可能被应用申请走变成 DEQUEUED 状态,虽然 Slot 是 DEQUEUED 状态这时 GPU 并不能直接存取它,它要等代表着 HWC 使用完毕的 releaseFence 的 signaled 信号。
应用侧申请 buffer 的同时会获取到一个 fence 对象(releaseFence):
frameworks/native/libs/gui/Surface.cpp
int Surface::dequeueBuffer(android_native_buffer_t** buffer, int* fenceFd) {
ATRACE_CALL();
.....
sp<Fence> fence;
status_t result = mGraphicBufferProducer->dequeueBuffer(&buf, &fence, reqWidth, reqHeight,
reqFormat, reqUsage, &mBufferAge,
enableFrameTimestamps ? &frameTimestamps
: nullptr);
.....
}对应 SurfaceFlinger 侧:
frameworks/native/libs/gui/BufferQueueProducer.cpp
status_t BufferQueueProducer::dequeueBuffer(int* outSlot, sp<android::Fence>* outFence,
uint32_t width, uint32_t height, PixelFormat format,
uint64_t usage, uint64_t* outBufferAge,
FrameEventHistoryDelta* outTimestamps) {
ATRACE_CALL();
.......
*outFence = (mCore->mSharedBufferMode &&
mCore->mSharedBufferSlot == found) ?
Fence::NO_FENCE : mSlots[found].mFence;//把Slot里记录的mFence对象返回出去,就是应用侧拿到的releaseFence
mSlots[found].mEglFence = EGL_NO_SYNC_KHR;
mSlots[found].mFence = Fence::NO_FENCE;//不妨思考下这里为什么可以清成NO_FENCE?
.......
}应用侧上帧时要创建一个 fence 来代表 GPU 的功能还在进行中,提交 buffer 的同时把 fence 对象传给 SurfaceFlinger:
frameworks/native/libs/gui/Surface.cpp
int Surface::queueBuffer(android_native_buffer_t* buffer, int fenceFd) {
ATRACE_CALL();
......
sp<Fence> fence(fenceFd >= 0 ? new Fence(fenceFd) : Fence::NO_FENCE);//创建一个fence, 这个就是SurfaceFlinger侧的acquireFence
......
IGraphicBufferProducer::QueueBufferInput input(timestamp, isAutoTimestamp,//将fence放入input参数
static_cast<android_dataspace>(mDataSpace), crop, mScalingMode,
mTransform ^ mStickyTransform, fence, mStickyTransform,
mEnableFrameTimestamps);
......
status_t err = mGraphicBufferProducer->queueBuffer(i, input, &output);//把这个fence传给surfaceflinger
......
}对应的 SurfaceFlinger 侧从 binder 里获取到应用侧传来的 fence 对象(这个称为 acquireFence):
frameworks/native/libs/gui/BufferQueueProducer.cpp
status_t BufferQueueProducer::queueBuffer(int slot,
const QueueBufferInput &input, QueueBufferOutput *output) {
ATRACE_CALL();
......
sp<Fence> acquireFence;
......
input.deflate(&requestedPresentTimestamp, &isAutoTimestamp, &dataSpace,
&crop, &scalingMode, &transform, &acquireFence, &stickyTransform,
&getFrameTimestamps);
......
mSlots[slot].mFence = acquireFence;//queueBuffer完成时Slot的mFence放的是acquireFence
......
}我们来通过 systrace 观察一个因 GPU 工作时间太长,从而让 DRM 工作线程卡在等 Fence 的情况:
如上图所示,complete_commit 函数(从上面 4.3 章我们了解过这个函数是执行 SOC 准备传输数据到 DDIC 的过程)执行时前面有一段时间是陷于等待状态了,那么它在等谁呢,从图中所示我们可以看出它在等下 73026 号 fence 的 signal 信号。这种情况说明 drm 内部的 dma 要去读 miHoYo.yuanshen 这个应用的 buffer 时发现应用的 GPU 还没有把画面画完,它不得不等待它画完才能开始读取,但既然都已经送到 crtc_commit 了,至少在 CPU 这侧,该 Slot 的 BufferState 已经是 ACQUIRED 状态。

6.3 本章小结
在本章节中我们了解了不同硬件间同步工作的一种方法,了解了 Fence 在 App 画面更新过程中的使用情况。
参考资料
[1]Android 画面显示流程分析 (1): https://www.jianshu.com/p/df46e4b39428
[2]Android 画面显示流程分析 (2): https://www.jianshu.com/p/f96ab6646ae3
[3]Android 画面显示流程分析 (3): https://www.jianshu.com/p/3c61375cc15b
[4]Android 画面显示流程分析 (4): https://www.jianshu.com/p/7a18666a43ce
[5]Android 画面显示流程分析 (5): https://www.jianshu.com/p/dcaf1eeddeb1