dubbo的SPI 机制与运用实现
前言
SPI(Service Provider Interface),是 JDK 内置的一种服务发现机制,可以用来启用框架扩展和替换组件,主要被开发人员使用。比如 java.sql.Driver 接口,不同厂商可以针对同一接口提供不同实现,MySQL 和 PostgreSQL 都有各自不同实现提供给用户。Java SPI 机制可以为某个接口寻找服务实现。Java 中 SPI 机制主要思想是将装配控制权移到程序之外,模块化设计中这个机制尤其重要,其核心思想就是 解耦。
其流程可以参考下图
Dubbo 并未使用 Java 原生 SPI 机制,而是对其进行增强,能够更好满足需求。
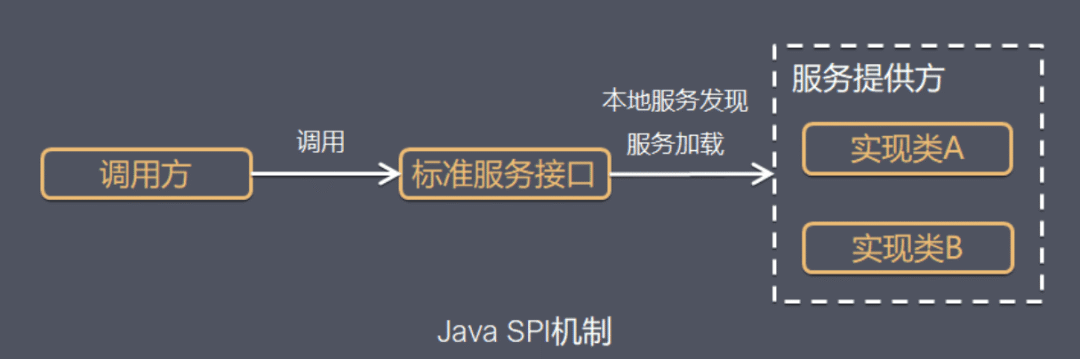
在学习 Dubbo SPI 之前,需要先了解 Java SPI 运行原理。
Java SPI
SPI 简单示例
- 这是一个搜索接口(行为)
public interface Search {
List<String> searchData(String query);
}- 文件搜索实现
public class FileSearch implements Search {
@Override
public List<String> searchData(String query) {
return Lists.newArrayList("这里是文件搜索");
}
}
- DB 搜索实现
public class DbSearch implements Search {
@Override
public List<String> searchData(String query) {
return Lists.newArrayList("这里 db 搜索");
}
}- ES 搜索实现
public class ElasticSearchSearch implements Search {
@Override
public List<String> searchData(String query) {
return Lists.newArrayList("这里是 es 搜索");
}
}- 在resources下新建
META-INF/services/目录,新建接口全限定名的文件:cn.zcy.spi.Search,文件内加上需要用到的实现类
cn.zcy.spi.DbSearch
cn.zcy.spi.FileSearch
cn.zcy.spi.ElasticSearchSearch- 测试
public class start {
public static void main(String[] args) {
ServiceLoader<Search> s = ServiceLoader.load(Search.class);
Iterator<Search> iterator = s.iterator();
while (iterator.hasNext()) {
Search next = iterator.next();
System.out.println(next.searchData());
}
}
}结果:Main 方法会将文件内部定义的所有实现类实例化,并调用其 SearchData 方法。
[这里是 db 搜索]
[这里是文件搜索]
[这里是 es 搜索]这就是 SPI 思想,接口实现由 Provider 提供,Provider 只用在提供的 Jar 包 META-INF/services 下根据平台定义的接口新建文件,并添加进相应的实现类内容就好。
SPI 实现
通过上述例子,可以简单猜想一下 ServiceLoader.Load 的实现方式:
- 在
META-INF/services目录下创建的文件名,是需要Load方法加载的接口的全限定名, 即系统可以通过Load方法入参, 找到定义的文件。 - 通过读取文件内容找到对应实现类的全限定名。
- 知道全限定名后, 很容易通过反射的方式来拿到对应的实现, 然后执行对应的方法。
根据以上猜想看 ServiceLoader.Load 具体实现
省略部分代码, 只关注关键处理逻辑
//ServiceLoader实现了Iterable接口,可以遍历所有的服务实现者
public final class ServiceLoader<S> implements Iterable<S>{
//查找配置文件的目录
private static final String PREFIX = "META-INF/services/";
//解析服务提供者配置文件中的一行
//首先去掉注释校验,然后保存
//返回下一行行号
//重复的配置项和已经被实例化的配置项不会被保存
private int parseLine(Class<?> service, URL u, BufferedReader r, int lc, List<String> names) throws IOException, ServiceConfigurationError {
//读取一行
String ln = r.readLine();
if (ln == null) {
return -1;
}
//#号代表注释行
int ci = ln.indexOf('#');
if (ci >= 0) ln = ln.substring(0, ci);
ln = ln.trim();
int n = ln.length();
if (n != 0) {
if ((ln.indexOf(' ') >= 0) || (ln.indexOf('\t') >= 0))
fail(service, u, lc, "Illegal configuration-file syntax");
int cp = ln.codePointAt(0);
if (!Character.isJavaIdentifierStart(cp))
fail(service, u, lc, "Illegal provider-class name: " + ln);
for (int i = Character.charCount(cp); i < n; i += Character.charCount(cp)) {
cp = ln.codePointAt(i);
if (!Character.isJavaIdentifierPart(cp) && (cp != '.'))
fail(service, u, lc, "Illegal provider-class name: " + ln);
}
if (!providers.containsKey(ln) && !names.contains(ln))
names.add(ln);
}
return lc + 1;
}
//解析配置文件,解析指定的url配置文件
//使用parseLine方法进行解析,未被实例化的服务提供者会被保存到缓存中去
private Iterator<String> parse(Class<?> service, URL u) throws ServiceConfigurationError {
InputStream in = null;
BufferedReader r = null;
ArrayList<String> names = new ArrayList<>();
try {
in = u.openStream();
r = new BufferedReader(new InputStreamReader(in, "utf-8"));
int lc = 1;
while ((lc = parseLine(service, u, r, lc, names)) >= 0);
}
return names.iterator();
}
//服务提供者查找的迭代器
private class LazyIterator implements Iterator<S>{
Class<S> service;//服务提供者接口
ClassLoader loader;//类加载器
Enumeration<URL> configs = null;//保存实现类的url
Iterator<String> pending = null;//保存实现类的全名
String nextName = null;//迭代器中下一个实现类的全名
private LazyIterator(Class<S> service, ClassLoader loader) {
this.service = service;
this.loader = loader;
}
private boolean hasNextService() {
if (nextName != null) {
return true;
}
if (configs == null) {
try {
String fullName = PREFIX + service.getName();
if (loader == null)
configs = ClassLoader.getSystemResources(fullName);
else
configs = loader.getResources(fullName);
}
}
while ((pending == null) || !pending.hasNext()) {
if (!configs.hasMoreElements()) {
return false;
}
pending = parse(service, configs.nextElement());
}
nextName = pending.next();
return true;
}
private S nextService() {
if (!hasNextService())
throw new NoSuchElementException();
String cn = nextName;
nextName = null;
Class<?> c = null;
try {
c = Class.forName(cn, false, loader);
}
if (!service.isAssignableFrom(c)) {
fail(service, "Provider " + cn + " not a subtype");
}
try {
S p = service.cast(c.newInstance());
providers.put(cn, p);
return p;
}
}
public boolean hasNext() {
if (acc == null) {
return hasNextService();
} else {
PrivilegedAction<Boolean> action = new PrivilegedAction<Boolean>() {
public Boolean run() { return hasNextService(); }
};
return AccessController.doPrivileged(action, acc);
}
}
public S next() {
if (acc == null) {
return nextService();
} else {
PrivilegedAction<S> action = new PrivilegedAction<S>() {
public S run() { return nextService(); }
};
return AccessController.doPrivileged(action, acc);
}
}
public void remove() {
throw new UnsupportedOperationException();
}
}
//获取迭代器
//返回遍历服务提供者的迭代器
//以懒加载的方式加载可用的服务提供者
//懒加载的实现是:解析配置文件和实例化服务提供者的工作由迭代器本身完成
public Iterator<S> iterator() {
return new Iterator<S>() {
//按照实例化顺序返回已经缓存的服务提供者实例
Iterator<Map.Entry<String,S>> knownProviders = providers.entrySet().iterator();
public boolean hasNext() {
if (knownProviders.hasNext())
return true;
return lookupIterator.hasNext();
}
public S next() {
if (knownProviders.hasNext())
return knownProviders.next().getValue();
return lookupIterator.next();
}
public void remove() {
throw new UnsupportedOperationException();
}
};
}
//使用扩展类加载器为指定的服务创建ServiceLoader
//只能找到并加载已经安装到当前Java虚拟机中的服务提供者,应用程序类路径中的服务提供者将被忽略
public static <S> ServiceLoader<S> loadInstalled(Class<S> service) {
ClassLoader cl = ClassLoader.getSystemClassLoader();
ClassLoader prev = null;
while (cl != null) {
prev = cl;
cl = cl.getParent();
}
return ServiceLoader.load(service, prev);
}
}- 首先 ,
ServiceLoader实现Iterable接口,所以具有迭代器属性,主要实现了迭代器的HasNext和Next方法,调用LookupIterator的HasNext和Next方法,LookupIterator是懒加载迭代器。 - 其次 ,
LazyIterator的HasNext方法,静态变量 Prefix 就是META-INF/services/目录,这就是为什么需要在Classpath下META-INF/services/目录创建以服务接口命名的文件。 - 最后 ,通过反射方法
Class.ForName()加载类对象,并用NewInstance方法将类实例化,并把实例化后的类缓存到Providers对象中,(LinkedHashMap<String,S>类型)然后返回实例对象。
所以可以看到 ServiceLoader 不是实例化后就读取配置文件中具体实现并进行实例化,而是等到使用迭代器去遍历的时候,才会加载对应配置文件去解析,调用 HasNext 方法的时候会去加载配置文件进行解析,调用 Next 方法的时候进行实例化并缓存。
所有配置文件只会加载一次,服务提供者也只会被实例化一次,重新加载配置文件可使用 Reload 方法。
SPI 机制缺陷
通过阅读 ServiceLoader 源码,可以反向推断出基础 SPI 在使用上存在部分缺陷:
- 无法按需来获取。遍历所有实现,并实例化,然后在循环中才能找到需要的实现。如果不想用某些实现类,或者某些类实例化很耗时,也会被载入并实例化了,造成了浪费。
- 获取某个实现类的方式不够灵活,只能通过 Iterator 形式获取,不能根据某个参数来获取对应的实现类。
- 多个并发线程使用 ServiceLoader 类的实例不安全。
Dubbo SPI 机制
Dubbo SPI 并非原创一种新的加载机制,它是在 Java 原生 SPI 基础上加以改进,解决原生 SPI 一些缺陷。
Dubbo SPI 机制简单示例
- 同样 Search 接口
@SPI
public interface Search {
List<String> searchData();
}- 文件搜索实现
public class FileSearch implements Search {
@Override
public List<String> searchData() {
return Lists.newArrayList("这里是文件搜索");
}
}- DB 搜索实现
public class DbSearch implements Search {
@Override
public List<String> searchData() {
return Lists.newArrayList("这里是 db 搜索");
}
}- ES 搜索实现
public class ElasticSearchSearch implements Search {
@Override
public List<String> searchData() {
return Lists.newArrayList("这里是 es 搜索");
}
}- 接下来同样是在
META-INF/services/目录下,新建接口全限定名的文件:cn.zcy.spi.Search,里面加上我们需要用到的实现类
db=cn.lzy.playwright.spi.dubbo.DbSearch
file=cn.lzy.playwright.spi.dubbo.FileSearch
es=cn.lzy.playwright.spi.dubbo.ElasticSearchSearch- 测试
@Slf4j
public class start {
public static void main(String[] args) {
ExtensionLoader<Search> extensionLoader = ExtensionLoader.getExtensionLoader(Search.class);
Search dbSearch = extensionLoader.getExtension("db");
log.info("dbSearch.method : {}", dbSearch.searchData());
Search fileSearch = extensionLoader.getExtension("file");
log.info("fileSearch.method : {}", fileSearch.searchData());
Search esSearch = extensionLoader.getExtension("es");
log.info("esSearch.method : {}", esSearch.searchData());
}
}结果
dbSearch.method : [这里是 db 搜索]
fileSearch.method : [这里是文件搜索]
esSearch.method : [这里是 es 搜索]分析一下,Dubbo SPI 和 Java 原生 SPI 实现上,有三个明显不同:
- Interface 上加入了 Dubbo 内部 @SPI 。
- 全限定名文件的内容,不再仅仅只是对应实现的全限定名, 而是类似 K-V 格式一种编写方式。
- Main 方法内部,不是通过原生
ServiceLoader加载,而是通过 Dubbo 自定义的ExtensionLoader加载。
通过示例很明显发现:Dubbo SPI 机制,通过改变全限定名文件内容格式,解决了原生 SPI 在使用上无法按需实例化这个缺陷。
那么 Dubbo SPI 如何实现,接下来看一下对应源码。
Dubbo SPI 实现
从入口 ExtensionLoader 来查看 GetExtensinLoader 方法
public static <T> ExtensionLoader<T> getExtensionLoader(Class<T> type) {
if (type == null) { // 规避了入参 NPE 问题
throw new IllegalArgumentException("Extension type == null");
}
if (!type.isInterface()) { // 规避入参非接口的问题
throw new IllegalArgumentException("Extension type(" + type + ") is not interface!");
}
if (!withExtensionAnnotation(type)) { // 方法内部判读接口是否存在 @SPI 注解
throw new IllegalArgumentException("Extension type(" + type +
") is not extension, because WITHOUT @" + SPI.class.getSimpleName() + " Annotation!");
}
ExtensionLoader<T> loader = (ExtensionLoader<T>) EXTENSION_LOADERS.get(type);
if (loader == null) { // 懒加载的实现逻辑
EXTENSION_LOADERS.putIfAbsent(type, new ExtensionLoader<T>(type));
loader = (ExtensionLoader<T>) EXTENSION_LOADERS.get(type);
}
return loader;
}方法内容很简单,除去一些判断外, 真正有价值的逻辑处理只有一个懒加载的实现,而关于代码上中 EXTENSION_LOADERS 其实是一个 ConcurrentHashMap
private static final ConcurrentMap<Class<?>, ExtensionLoader<?>> EXTENSION_LOADERS = new ConcurrentHashMap<Class<?>, ExtensionLoader<?>>();这在一定程度上解决了重复读取和并发问题。关键读取处理逻辑是在 new ExtensionLoader<T>(type) 这个构造方法内部,这个构造方法十分简单,是一个三元表达式
private ExtensionLoader(Class<?> type) {
this.type = type;
objectFactory = (type == ExtensionFactory.class ? null : ExtensionLoader.getExtensionLoader(ExtensionFactory.class).getAdaptiveExtension());
}所以要关注的就是 GetAdaptiveExtension 这个方法实现
如下是具体实现逻辑
public T getAdaptiveExtension() {
Object instance = cachedAdaptiveInstance.get();
if (instance == null) {
if (createAdaptiveInstanceError == null) {
synchronized (cachedAdaptiveInstance) { // 懒加载的双重锁校验, 避免了并发问题
instance = cachedAdaptiveInstance.get();
if (instance == null) {
try {
instance = createAdaptiveExtension(); // 实例化的关键处理
cachedAdaptiveInstance.set(instance);
} catch (Throwable t) {
createAdaptiveInstanceError = t;
throw new IllegalStateException("fail to create adaptive instance: " + t.toString(), t);
}
}
}
} else {
throw new IllegalStateException("fail to create adaptive instance: " + createAdaptiveInstanceError.toString(), createAdaptiveInstanceError);
}
}
return (T) instance;
}CreateAdaptiveExtension 关键是调用 GetAdaptiveExtensionClass 方法
private T createAdaptiveExtension() {
try {
return injectExtension((T) getAdaptiveExtensionClass().newInstance());
} catch (Exception e) {
throw new IllegalStateException("Can not create adaptive extension " + type + ", cause: " + e.getMessage(), e);
}
}继续看内部逻辑, 查到 GetExtensionClasses 方法
private Class<?> getAdaptiveExtensionClass() {
getExtensionClasses();
if (cachedAdaptiveClass != null) {
return cachedAdaptiveClass;
}
return cachedAdaptiveClass = createAdaptiveExtensionClass();
}最后看到读取 Interface 对应实现类的方法是 LoadExtensionClasses , 具体实现逻辑如下
private Map<String, Class<?>> getExtensionClasses() {
Map<String, Class<?>> classes = cachedClasses.get();
if (classes == null) {
synchronized (cachedClasses) {
classes = cachedClasses.get();
if (classes == null) {
classes = loadExtensionClasses(); // 懒加载双重判定解决并发问题
cachedClasses.set(classes);
}
}
}
return classes;
}
// synchronized in getExtensionClasses
private Map<String, Class<?>> loadExtensionClasses() {
final SPI defaultAnnotation = type.getAnnotation(SPI.class);
if (defaultAnnotation != null) {
String value = defaultAnnotation.value();
if ((value = value.trim()).length() > 0) {
String[] names = NAME_SEPARATOR.split(value);
if (names.length > 1) {
throw new IllegalStateException("more than 1 default extension name on extension " + type.getName() + ": " + Arrays.toString(names));
}
if (names.length == 1) {
cachedDefaultName = names[0];
}
}
}
Map<String, Class<?>> extensionClasses = new HashMap<String, Class<?>>();
// 指定地址读取文件内容, 兼容原生的 SPI 地址和默认的 duboo 文件地址
loadDirectory(extensionClasses, DUBBO_INTERNAL_DIRECTORY, type.getName());
loadDirectory(extensionClasses, DUBBO_INTERNAL_DIRECTORY, type.getName().replace("org.apache", "com.alibaba"));
loadDirectory(extensionClasses, DUBBO_DIRECTORY, type.getName());
loadDirectory(extensionClasses, DUBBO_DIRECTORY, type.getName().replace("org.apache", "com.alibaba"));
loadDirectory(extensionClasses, SERVICES_DIRECTORY, type.getName());
loadDirectory(extensionClasses, SERVICES_DIRECTORY, type.getName().replace("org.apache", "com.alibaba"));
return extensionClasses;
}
private void loadDirectory(Map<String, Class<?>> extensionClasses, String dir, String type) {
String fileName = dir + type;
try {
Enumeration<java.net.URL> urls;
ClassLoader classLoader = findClassLoader();
if (classLoader != null) {
urls = classLoader.getResources(fileName);
} else {
urls = ClassLoader.getSystemResources(fileName);
}
if (urls != null) {
while (urls.hasMoreElements()) {
java.net.URL resourceURL = urls.nextElement();
loadResource(extensionClasses, classLoader, resourceURL); // 读取指定地址文件资源
}
}
} catch (Throwable t) {
logger.error("Exception when load extension class(interface: " +type + ", description file: " + fileName + ").", t);
}
}
private void loadResource(Map<String, Class<?>> extensionClasses, ClassLoader classLoader, java.net.URL resourceURL) {
try {
BufferedReader reader = new BufferedReader(new InputStreamReader(resourceURL.openStream(), "utf-8"));
try {
String line;
// 按行读取配置
while ((line = reader.readLine()) != null) {
final int ci = line.indexOf('#');
if (ci >= 0) {
// 忽略 # 后的注释内容
line = line.substring(0, ci);
}
line = line.trim();
if (line.length() > 0) {
try {
String name = null;
// 根据 = 分割内容, 拆解成 K-V 格式数据
int i = line.indexOf('=');
if (i > 0) {
name = line.substring(0, i).trim();
line = line.substring(i + 1).trim();
}
if (line.length() > 0) {
// 加载 Class
loadClass(extensionClasses, resourceURL, Class.forName(line, true, classLoader), name);
}
} catch (Throwable t) {
IllegalStateException e = new IllegalStateException("Failed to load extension class(interface: " + type + ", class line: " + line + ") in " + resourceURL + ", cause: " + t.getMessage(), t);
exceptions.put(line, e);
}
}
}
} finally {
reader.close();
}
} catch (Throwable t) {
logger.error("Exception when load extension class(interface: " +type + ", class file: " + resourceURL + ") in " + resourceURL, t);
}
}由上述代码逻辑可以了解,Dubbo SPI 加载 Class 信息过程主要分成以下几步:
- 首先:通过名称获取拓展类之前,需要根据配置文件解析出拓展项名称到拓展类的映射关系表(Map<名称, 拓展类>),之后再根据拓展项名称从映射关系表中取出相应的拓展类
- 其次:
GetExtensionClasses内部先检查缓存,若缓存未命中,则通过synchronized加锁。加锁后再次检查缓存,并判空,此时如果 Classes 仍为 Null,则通过LoadExtensionClasses加载拓展类 - 然后:
LoadExtensionClasses中的逻辑比较简单, 总共就两件事情:一是对 SPI 注解进行解析,二是调用LoadDirectory方法加载指定文件夹配置文件 - 接着
LoadDirectory方法先通过ClassLoader获取所有资源链接,然后再通过LoadResource方法加载资源 - 最后
LoadResource方法用于读取和解析配置文件,并通过反射加载类,最后调用LoadClass方法进行其他操作。LoadClass方法用于主要用于操作缓存
加载完 Interface 对应实现 Class 之后就需要对其进行实例化,看一下源码实现
public T getExtension(String name) {
if (name == null || name.length() == 0) {
throw new IllegalArgumentException("Extension name == null");
}
if ("true".equals(name)) {
return getDefaultExtension();
}
// 缓存 Holder
Holder<Object> holder = cachedInstances.get(name);
if (holder == null) {
cachedInstances.putIfAbsent(name, new Holder<Object>());
holder = cachedInstances.get(name);
}
Object instance = holder.get();
if (instance == null) { // 懒加载的双重判定, 避免并发情况
synchronized (holder) {
instance = holder.get();
if (instance == null) {
instance = createExtension(name);
holder.set(instance);
}
}
}
return (T) instance;
}该方法内部是一个普通缓存读取内容,创建内容在方法 CreateExtension 内部
private T createExtension(String name) {
// 从配置文件中加载所有的拓展类,可得到“配置项名称”到“配置类”的映射关系表
Class<?> clazz = getExtensionClasses().get(name);
if (clazz == null) {
throw findException(name);
}
try {
T instance = (T) EXTENSION_INSTANCES.get(clazz);
if (instance == null) {
// 通过反射创建实例
EXTENSION_INSTANCES.putIfAbsent(clazz, clazz.newInstance());
instance = (T) EXTENSION_INSTANCES.get(clazz);
}
// 向实例中注入依赖
injectExtension(instance);
Set<Class<?>> wrapperClasses = cachedWrapperClasses;
if (wrapperClasses != null && !wrapperClasses.isEmpty()) {
// 循环创建 Wrapper 实例
for (Class<?> wrapperClass : wrapperClasses) {
// 将当前 instance 作为参数传给 Wrapper 的构造方法,并通过反射创建 Wrapper 实例。
// 然后向 Wrapper 实例中注入依赖,最后将 Wrapper 实例再次赋值给 instance 变量
instance = injectExtension((T) wrapperClass.getConstructor(type).newInstance(instance));
}
}
return instance;
} catch (Throwable t) {
throw new IllegalStateException("Extension instance(name: " + name + ", class: " +
type + ") could not be instantiated: " + t.getMessage(), t);
}
}CreateExtension 方法逻辑稍复杂一下,包含了如下步骤:
- 通过
GetExtensionClasses获取所有的拓展类 - 通过反射创建拓展对象
- 向拓展对象中注入依赖
- 将拓展对象包裹在相应的
Wrapper对象中
以上步骤中,第一个步骤是加载拓展类的关键,第三和第四个步骤是 Dubbo IOC 与 AOP 的具体实现
private T injectExtension(T instance) {
try {
if (objectFactory != null) {
// 遍历目标类的所有方法
for (Method method : instance.getClass().getMethods()) {
// 检测方法是否以 set 开头,且方法仅有一个参数,且方法访问级别为 public
if (method.getName().startsWith("set") && method.getParameterTypes().length == 1
&& Modifier.isPublic(method.getModifiers())) {
/**
* Check {@link DisableInject} to see if we need auto injection for this property
*/
if (method.getAnnotation(DisableInject.class) != null) {
continue;
}
// 获取 setter 方法参数类型
Class<?> pt = method.getParameterTypes()[0];
if (ReflectUtils.isPrimitives(pt)) {
continue;
}
try {
// 获取属性名,比如 setName 方法对应属性名 name
String property = method.getName().length() > 3 ? method.getName().substring(3, 4).toLowerCase() + method.getName().substring(4) : "";
// 从 ObjectFactory 中获取依赖对象
Object object = objectFactory.getExtension(pt, property);
if (object != null) {
// 通过反射调用 setter 方法设置依赖
method.invoke(instance, object);
}
} catch (Exception e) {
logger.error("fail to inject via method " + method.getName()
+ " of interface " + type.getName() + ": " + e.getMessage(), e);
}
}
}
}
} catch (Exception e) {
logger.error(e.getMessage(), e);
}
return instance;
}在上面代码中,ObjectFactory 变量类型为 AdaptiveExtensionFactory,AdaptiveExtensionFactory 内部维护了一个 ExtensionFactory 列表,用于存储其他类型的 ExtensionFactory。Dubbo 目前提供两种 ExtensionFactory,分别是 SpiExtensionFactory 和 SpringExtensionFactory。前者用于创建自适应的拓展,后者用于从 Spring IOC 容器中获取所需拓展。这两个类代码不是很复杂,这里就不一一分析了。
可以看出,Dubbo SPI 在原生 SPI 基础上,通过对配置文件格式改造,生成了一个映射关系表(Map<名称, 拓展类>),这样能够按需去实例化需要的实现类。解决原生 SPI 必须全部遍历然后遍历查询实现实例的问题.
同时无论是读取配置 Class 亦或是实例化对应的实现实例,都采用了懒加载的双重锁校验,解决了原生 SPI 在多线程情况下,可能存在的并发问题。
总结
自 JDK 1.6 以后,Java 提出了 SPI,一种服务提供发现机制,可以用来启用框架扩展和替换组件。其主要目的是将装配控制权移到程序之外,模块化设计中这个机制尤其重要。其核心思想是 解耦。
这种原生 SPI 机制并不完美,其实现存在若干问题
- 无法按需进行实例化,只能全部实例化之后,遍历去获取需要的实现,造成内存浪费以及无谓的实例化资源消耗。
- 并没有解决多线程下的并发问题。
Duboo 在原生 SPI 基础上进行改良,通过改变配置文件内容格式,针对每个实现类划分出 K-V ,能够满足在业务上按需实例化的要求。同时采用懒加载的双重锁校验,解决多线程情况下可能存在的并发问题。