谈谈node架构中的线程进程的应用场景、事件循环及任务队列
Node.js是一个基于Chrome V8引擎的JavaScript运行时环境,nodejs是单线程执行的,它基于事件驱动和非阻塞I/O模型进行多任务的执行。在理解Node.js的工作原理时,我们需要了解进程、线程、事件循环[1]以及消息队列[2]的概念,本篇文章就基于这几点去详细介绍,帮你慢慢理解node的工作原理。
进程
进程是操作系统中正在运行的一个程序的实例。在Node.js中,每个应用程序都运行在一个单独的进程中。 node app.js 就是开启一个服务进程,多进程就是进程的复制(child_process.fork),child_process.fork 出来的每个进程都拥有自己的独立空间地址、数据栈,一个进程无法访问另外一个进程里定义的变量、数据结构,只有建立了 IPC 通信,进程之间才可数据共 多进程的好处是可以充分利用多核处理器的优势,通过将工作负载分配到多个进程中来提高应用程序的性能。
process 模块
Node.js 中的进程 Process 是一个全局对象,无需 require 直接使用,给我们提供了当前进程中的相关信息。
- process.env:环境变量,例如通过 process.env.NODE_ENV 获取不同环境项目配置信息
- process.nextTick:这个在谈及 Event Loop 时经常为会提到
- process.pid:获取当前进程id
- process.ppid:当前进程对应的父进程
- process.cwd():获取当前进程工作目录,
- process.platform:获取当前进程运行的操作系统平台
- process.uptime():当前进程已运行时间,例如:pm2 守护进程的 uptime 值
- 进程事件:process.on(‘uncaughtException’, cb) 捕获异常信息、process.on(‘exit’, cb)进程推出监听
- 三个标准流:process.stdout 标准输出、process.stdin 标准输入、process.stderr 标准错误输出
- process.title 指定进程名称,有的时候需要给进程指定一个名称
创建多进程child_process、cluster的应用
Node.js提供了child_process模块,用于创建和管理子进程。通过child_process模块,我们可以在Node.js中创建新的进程,与其进行通信,并监视其状态。以下是一个简单的示例,演示了如何在Node.js中创建一个子进程并与主进程通信: 开启一个http服务,并通过 require('child_process').fork创建一个子进程:
// child_process.js
const http = require('http');
const fork = require('child_process').fork;
const path = require('path');
const server = http.createServer((req, res) => {
if(req.url == '/compute'){
const compute = fork(path.resolve(__dirname, './compute.js'));
compute.send('开启一个新的子进程');
// 当一个子进程使用 process.send() 发送消息时会触发 'message' 事件
compute.on('message', sum => {
res.end(`Sum is ${sum}`);
compute.kill();
});
// 子进程监听到一些错误消息退出
compute.on('close', (code, signal) => {
console.log(`收到close事件,子进程收到信号 ${signal} 而终止,退出码 ${code}`);
compute.kill();
})
}else{
res.end(`ok`);
}
});
server.listen(3000, () => {
console.log(`server started at http://127.0.0.1:3000`);
});- 创建一个含有大量计算任务的处理逻辑
// compute.js
const computation = () => {
let sum = 0;
console.info('计算开始');
console.time('计算耗时');
for (let i = 0; i < 1e10; i++) {
sum += i
};
console.info('计算结束');
console.timeEnd('计算耗时');
return sum;
};
process.on('message', msg => {
console.log(msg, 'process.pid', process.pid); // 子进程id
const sum = computation();
// 如果Node.js进程是通过进程间通信产生的,那么,process.send()方法可以用来给父进程发送消息
process.send(sum);
})
在上面的示例中,我们创建了一个http服务,并在接口http://127.0.0.1:3000/compute接口中使用require('child_process').fork()创建了一个子进程,将大量的计算逻辑放在了子进程中,这样一来,当我们频繁请求http://127.0.0.1:3000/compute接口时,我们的node服务就会并发处理这些计算逻辑密集型的逻辑,从而让接口有更快的响应。 试想如果此时没有开启子进程,而是将大量计算逻辑放到主进程,当有大量请求时会发生什么? 答案:会变成每次请求都是同步的,前一个请求处理完毕,才会处理下一个,时间就会拉长,后面的请求响应就会变慢。 再比如我们上传图片的功能就可以利用开启多个进程:
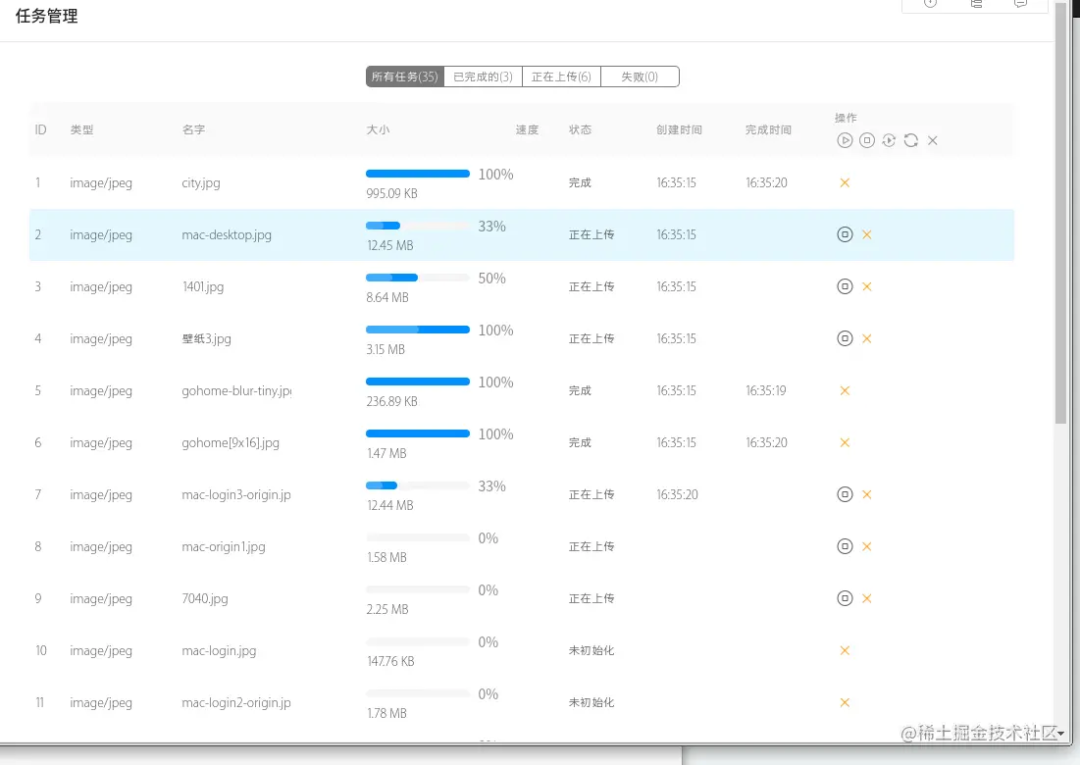
使用cluster创建多进程
const http = require('http');
const numCPUs = require('os').cpus().length;
const cluster = require('cluster');
if(cluster.isMaster){
console.log('Master proces id is',process.pid);
// fork workers
for(let i= 0;i<numCPUs;i++){
cluster.fork();
}
cluster.on('exit',function(worker,code,signal){
console.log('worker process died,id',worker.process.pid)
})
}else{
// 这里是一个http服务器
http.createServer(function(req,res){
res.writeHead(200);
res.end('hello word');
}).listen(8000);
}cluster模块调用cluster.fork()来创建子进程,该方法与child_process中的fork是同一个方法。 cluster模块采用的是经典的主从模型,Cluster会创建一个master,然后根据你指定的数量复制出多个子进程,可以使用cluster.isMaster属性判断当前进程是master还是worker(工作进程)。由master进程来管理所有的子进程,主进程不负责具体的任务处理,主要工作是负责调度和管理。 cluster 模块同时实现了负载均衡调度算法,在类 unix 系统中,cluster 使用轮转调度(round-robin),node 中维护一个可用 worker 节点的队列 free,和一个任务队列 handles。当一个新的任务到来时,节点队列队首节点出队,处理该任务,并返回确认处理标识,依次调度执行。而在 win 系统中,Node 通过 Shared Handle 来处理负载,通过将文件描述符、端口等信息传递给子进程,子进程通过信息创建相应的 SocketHandle / ServerHandle,然后进行相应的端口绑定和监听,处理请求。
开启多进程时候端口疑问讲解:如果多个Node进程监听同一个端口时会出现 Error:listen EADDRIUNS的错误,而cluster模块为什么可以让多个子进程监听同一个端口呢?原因是master进程内部启动了一个TCP服务器,而真正监听端口的只有这个服务器,当来自前端的请求触发服务器的connection事件后,master会将对应的socket具柄发送给子进程。而child_process操作子进程时,创建多个TCP服务器, 无论是 child_process 模块还是 cluster 模块,为了解决 Node.js 实例单线程运行,无法利用多核 CPU 的问题而出现的。核心就是通过fork()或者其他API,创建了子进程之后,父进程(即 master 进程)负责监听端口,接收到新的请求后将其分发给下面的 worker 进程,父子进程之间才能通过message和send()进行IPC通信(Inter-Process Communication)。
Node中实现IPC通道是依赖于libuv,
总结:
当有大量请求时,或者大量任务时,可以开启多个进程,同时并发处理这些请求,以缓解处理完一个才能处理下一个请求的阻塞状态。
线程
const http = require('http');
const server = http.createServer();
server.listen(3000,()=>{
process.title='测试进程线程数量';
console.log('进程id',process.pid)
})创建了http服务,开启了一个进程,都说了Node.js是单线程,所以大家可能认为 Node 启动后线程数应该为 1,让我们使用Mac自带的活动监视器搜索process.title(也就是测试进程线程数量)来查看一下具体是几个线程:

可以看到线程数量是8,但是为什么会开启8个线程呢?难道Javascript不是单线程不知道小伙伴们有没有这个疑问? 解释一下这个原因: Node 中最核心的是 v8 引擎,v8是一个执行 JS 的引擎. 也就是翻译 JS. 包括我们熟悉的编译优化, 垃圾回收等等.在 Node 启动后,会创建 v8 的实例,这个实例是多线程的。
- 主线程:编译、执行代码。
- 编译/优化线程:在主线程执行的时候,可以优化代码。
- 分析器线程:记录分析代码运行时间,为 Crankshaft 优化代码执行提供依据。
- 垃圾回收的几个线程。
所以大家常说的 Node 是单线程的指的是 JavaScript 的执行是单线程的(开发者编写的代码运行在单线程环境中),但 Javascript 的宿主环境,无论是 Node 还是浏览器都是多线程的,
还是刚才的例子,我们加入一个读取文件的IO操作:
const http = require('http');
const fs = require('fs')
const server = http.createServer();
server.listen(3000,()=>{
process.title='测试进程线程数量';
console.log('进程id',process.pid)
})
fs.readFile('./read.js', () => {})再来看看这个时候的线程数量:

为什么?
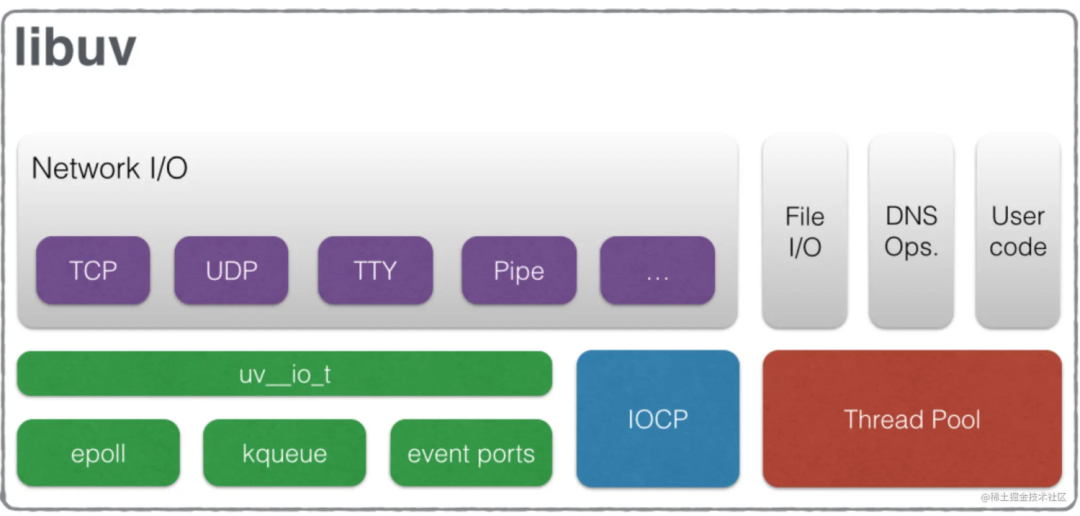
因为Nodejs是单线程的,作为服务器,他涉及到IO,而IO是会阻塞的,从而影响性能。所以Nodejs把IO操作交给libuv,保证主线程可以继续处理其他事情。如图libuv会负责一些 IO 操作(DNS因为dns.lookup方法会涉及到读取本地文件(例如nsswitch.conf,resolv.conf以及 /etc/hosts),FS读取本地文件)和一些 CPU 密集计算(Zlib,Crypto),libuv会启用线程池。当 js层传递给 libuv一个操作任务时,libuv会把这个任务加到队列中。而线程池默认大小为 4,可以通过UV_THREADPOOL_SIZE可以修改线程池的线程数,线程数最大值为128,最小值为1。
process.env.UV_THREADPOOL_SIZE = 64前面讲了node本身的一些IO操作和CPU密集计算是可以利用线程做事情的,那么我们项目开发中该如何利用线程? Node.js的事件循环模型[3]是单线程的,适用于I/O密集型任务。但对于计算密集型任务,单线程的性能可能有限。通过创建多个子线程,可以将计算密集型任务分配到这些线程中并发执行,从而提高性能。
线程的应用场景
下面我们就利用多线程来计算一个CPU密集型任务,生成斐波那契数列。
- 创建执行脚本worker.js
Node.js 中的 worker_threads[4] 模块是用于创建多线程应用程序的官方模块。它允许在 Node.js 程序中创建和管理真正的操作系统线程,以实现并行处理和利用多核 CPU 的能力。
// worker.js
const {parentPort, workerData} = require("worker_threads");
parentPort.postMessage(getFibonacciNumber(workerData.num))
function getFibonacciNumber(num) {
if (num === 0) {
return 0;
}
else if (num === 1) {
return 1;
}
else {
return getFibonacciNumber(num - 1) + getFibonacciNumber(num - 2);
}
}- 创建主线程脚本脚本index.js:
// index.js
const {Worker} = require("worker_threads");
const path = require("path");
let number = 30;
const worker = new Worker(path.resolve(__dirname, './worker.js'), {workerData: {num: number}});
worker.once("message", result => {
console.log(`${number}th Fibonacci Result: ${result}`);
});
worker.on("error", error => {
console.log(error);
});
worker.on("exit", exitCode => {
console.log(`It exited with code ${exitCode}`);
})
console.log("Execution in main thread");- 运行脚本,node index.js 查看结果:
看控制台打印结果是:
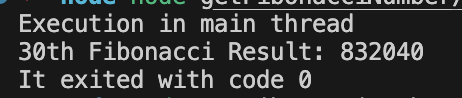
- Execution in main thread
- 30th Fibonacci Result: 832040
- It exited with code 0
可以看到,“Execution in main thread”是先执行的,并没有被前面worker中大量的CPU密集型计算所阻塞到,倘若没有新开线程去处理这个大量计算逻辑,后面的所有任务都会被阻塞到,所以在处理复杂的计算或耗时操作时,使用线程可以显著提高CPU利用率和系统吞吐量。
总结
当一个请求或者任务内部有很多逻辑,且有大量的CPU密集型计算逻辑时,可以开启新线程将部分密集型计算逻辑放到新线程中计算,从而不阻塞后面的其他同步逻辑。
node中的事件循环
前面已经讲到,node是单线程模型,是一个基于事件驱动、非阻塞式 I/O 的模型,这离不开他的事件循环机制,总体来说事件循环机制就是基于回调通知的机制,原本同步模式等待的时间,则可以用来处理其它任务。 事件循环的6个阶段:
本阶段执行已经被 setTimeout() 和 setInterval() 的调度回调函数。
┌───────────────────────────┐
┌─>│ timers │
│ └─────────────┬─────────────┘
| 执行延迟到下一个循环迭代的 I/O 回调。
│ ┌─────────────┴─────────────┐
│ │ I/O callbacks |
│ └─────────────┬─────────────┘
| 仅系统内部使用。
│ ┌─────────────┴─────────────┐
│ │ idle, prepare │
│ └─────────────┬─────────────┘
| 检索新的I/O事件;执行与 I/O相关的回调 ┌───────────────┐
│ ┌─────────────┴─────────────┐ │ incoming: │
│ │ poll │<─────┤ connections, │
│ └─────────────┬─────────────┘ │ data, etc. │
│ setImmediate() 回调函数在这里执行。 └───────────────┘
│ ┌─────────────┴─────────────┐
│ │ check │
│ └─────────────┬─────────────┘
| 一些关闭的回调函数
│ ┌─────────────┴─────────────┐
└──┤ close callbacks │
└───────────────────────────┘
每个循环阶段内容详解
- timers阶段:
一个timer指定一个下限时间而不是准确时间,在达到这个下限时间后执行回调。在指定时间过后,timers会尽可能早地执行回调,但系统调度或者其它回调的执行可能会延迟它们。
- 注意:技术上来说,poll 阶段控制 timers 什么时候执行。
- 注意:这个下限时间有个范围:[1, 2147483647],如果设定的时间不在这个范围,将被设置为1。
- 此外, libuv为了防止某个阶段任务太多, 导致后续的 阶段 发生饥饿的现象, 所以消息循环的每一个迭代(iterate) 中, 每个阶段执行回调都有个最大数量. 如果超过数量的话也会强行结束当前阶段而进入下一个阶段. 这一条规则适用于消息循环中的每一个阶段.
- I/O callbacks阶段:
这个阶段执行一些系统操作的回调。比如TCP错误,如一个TCP socket在想要连接时收到ECONNREFUSED, 类unix系统会等待以报告错误,这就会放到 I/O callbacks 阶段的队列执行. 名字会让人误解为执行I/O回调处理程序, 实际上I/O回调会由poll阶段处理.
- idle, prepare
据说是内部使用, 所以我们也不在这里过多讨论.
- poll阶段
这是整个消息循环中最重要的一个阶段, 作用是等待异步请求和数据,获取I/O事件回调, 例如操作读取文件等等,适当的条件下node将阻塞在这里; 该阶段有两个情况:
- 如果 poll 队列不空,event loop会遍历队列并同步执行回调,直到队列清空或执行的回调数到达系统上限;
- 如果 poll 队列为空,则发生以下两件事之一:
- 如果代码已经被setImmediate()设定了回调, event loop将结束 poll 阶段进入 check 阶段来执行 check 队列(里面的回调 callback)。
-
如果代码没有被setImmediate()设定回调,event loop将阻塞在该阶段等待回调被加入 poll 队列,并立即执行。
- 但是,当event loop进入 poll 阶段,并且 有设定的timers,一旦 poll 队列为空(poll 阶段空闲状态): event loop将检查timers,如果有1个或多个timers的下限时间已经到达,event loop将绕回 timers 阶段,并执行 timer 队列。
- check阶段:
这个阶段允许在 poll 阶段结束后立即执行回调。如果 poll 阶段空闲,并且有被setImmediate()设定的回调,event loop会转到 check 阶段而不是继续等待。
- setImmediate() 实际上是一个特殊的timer,跑在event loop中一个独立的阶段。它使用libuv的API 来设定在 poll 阶段结束后立即执行回调。
- 通常上来讲,随着代码执行,event loop终将进入 poll 阶段,在这个阶段等待 incoming connection, request 等等。但是,只要有被setImmediate()设定了回调,一旦 poll 阶段空闲,那么程序将结束 poll 阶段并进入 check 阶段,而不是继续等待 poll 事件们 (poll events)。
- close callbacks 阶段:
如果一个 socket 或 handle 被突然关掉(比如 socket.destroy()),close事件将在这个阶段被触发,否则将通过process.nextTick()触发小测试:
console.log('同步');
process.nextTick(()=>{
console.log('nextTick');
});
Promise.resolve().then(()=>{
console.log('微任务');
});
// 到达可执行条件才会执行,与
setTimeout(() => {
console.log('setTimeout');
}, 0);
// poll之后会立即检查是否有setImmediate,如果存在就立即执行
setImmediate(()=>{
console.log('setImmediate');
})打印结果为:同步 - nextTick - 微任务 - setTimeout - setImmediate
setImmediate() 对比 setTimeout()
setImmediate() 和 setTimeout() 很类似,但是基于被调用的时机,他们也有不同表现。
- setImmediate() 设计为一旦在当前 轮询 阶段完成, 就执行脚本。
- setTimeout() 在最小阈值(ms 单位)过后运行脚本。
执行计时器的顺序将根据调用它们的上下文而异。如果二者都从主模块内调用,则时序将受进程性能的约束(这可能会受到计算机上其他正在运行应用程序的影响)
bull.js任务队列
当一大批客户端同时产生大量的网络请求(消息)时候,服务器的承受能力肯定是有一个限制的。对服务器的访问已经超过服务所能处理的最大峰值,甚至导致服务器超时负载崩溃。 这时候要是有个容器,先让这些消息排队就好了,还好有个叫队列的数据结构,通过有队列属性的容器排队(先进先出),把消息再传到我们的服务器,压力减小了好多,这个很棒的容器就是消息队列。
消息队列优势
- 应用解耦消息队列可以使消费者和生产者直接互不干涉,互不影响,只需要把消息发送到队列即可,而且可独立的扩展或修改两边的处理过程,只要能确保它们遵守同样的接口约定,可以生产者用Node.js实现,消费者用phython实现。
- 灵活性和峰值处理能力当客户端访问量突然剧增,对服务器的访问已经超过服务所能处理的最大峰值,甚至导致服务器超时负载崩溃,使用消息队列可以解决这个问题,可以通过控制消费者的处理速度和生产者可进入消息队列的数量等来避免峰值问题
- 排序保证消息队列可以控制数据处理的顺序,因为消息队列本身使用的是队列这个数据结构,FIFO(先进选出),在一些场景数据处理的顺序很重要,比如商品下单顺序等。
- 异步通信消息队列中的有些消息,并不需要立即处理,消息队列提供了异步处理机制,可以报消息放在队列中并不立即处理,需要的时候处理,或者异步慢慢处理,一些不重要的发送短信和邮箱功能可以使用。
- 可扩展性前面提到了消息队列可以做到解耦,如果我们想增强消息入队和出队的处理频率,很简单,并不需要改变代码中任何内容,可以直接对消息队列修改一些配置即可,比如我们想限制每次发送给消费者的消息条数等。
node消息队列框架
介绍几款目前市场上主流的消息队列(课外知识,可忽略)
- Kafka:是由 Apache 软件基金会开发的一个开源流处理平台,由 Scala 和 Java 编写,是一种高吞吐量的分布式发布订阅消息系统,支持单机每秒百万并发。另外,Kafka 的定位主要在日志等方面, 因为Kafka 设计的初衷就是处理日志的,可以看做是一个日志(消息)系统一个重要组件,针对性很强。0.8 版本开始支持复制,不支持事物,因此对消息的重复、丢失、错误没有严格的要求。
- RocketMQ:阿里开源的消息中间件,是一款低延迟、高可靠、可伸缩、易于使用的消息中间件,思路起源于 Kafka。最大的问题商业版收费,有些功能不开放。
- RabbitMQ:由 Erlang(有着和原生 Socket 一样低的延迟)语言开发基于 AMQP 协议的开源消息队列系统。能保证消息的可靠性、稳定性、安全性。高并发的特性,毋庸置疑,RabbitMQ 最高,原因是它的实现语言是天生具备高并发高可用的erlang 语言,天生的分布式优势。
- Bull: Bull[5] 是基于 Redis 实现的一个快速且强大的消息系统(队列)。Bull 提供了可以很简单就能使用的消息队列、延时任务和定时任务。
bull.js使用
const Bull = require('bull');
const queueOptions = {
// limiter: { max: 2, duration: 10000 }, // 设置并发执行数为5
redis: {
port: 5816,
host: 'xx.xxx.xx.xx', // 连接IP
password: 'xxxxxxxxxxx', // 没有密码就填null
db: 10, // 使用区间库
},
defaultJobOptions: {
attempts: 1,
removeOnComplete: true,
backoff: false,
delay: 0,
},
};
const myQueue = new Bull('test-queue',queueOptions);
// 假设我们有10000个秒杀请求过来要处理,我们可以将任务放入队列,挨个去处理
for (let i = 0; i < 10000; i++) {
myQueue.add({ data: i });
}
myQueue.process(async (job) => {
console.log('<',job.data);
await asyncHandle(job);
});
async function asyncHandle(job){
await handleJSError(job)
}
function handleJSError(job) {
return new Promise((resolve,reject)=>{
setTimeout(()=>{
console.log('>',job.data);
resolve()
},5000)
})
}参考资料
- [1] nodejs事件循环: https://blog.csdn.net/i10630226/article/details/81369841
- [2] nodejs 消息队列: https://www.imooc.com/article/296194
- [3] NodeJS事件循环机制: https://juejin.cn/post/6844903999506923528
- [4] nodejs worker_threads: https://juejin.cn/post/7062733724504293413
- [5] Bull: https://blog.csdn.net/weixin_43698328/article/details/125193000