编译优化在微信视频号的落地实践
导语:编译优化是通过编译技术获得性能提升的一类性能优化方法,它具有通用性和可持续性强的优势,一次投入后可长期保持稳定的优化效果,可以有效降低性能优化的成本。
本文将回顾视频号推荐模块落地编译优化的历程和成果,也会介绍具体实践中遇到的问题和对应的解决方案,为后续同类应用提供参考。期待后续更多的业务模块能通过编译优化取得性能提升和成本收益。
PART 01 落地成果
我们把编译优化落地路径分为以下几类:
- 升级编译器
- 应用反馈编译优化(PGO/LTO)
- 应用LTO优化
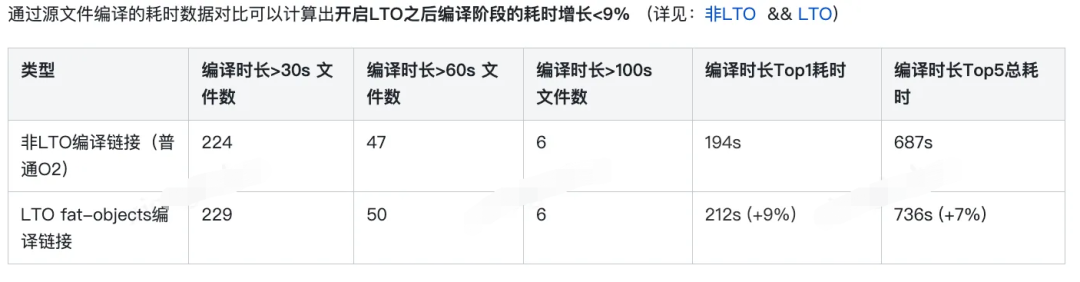
在微信视频号推荐模块我们首先完成了编译器版本升级,从GCC 7.5升级到TGCC(基于GCC 10),随后陆续将PGO/LTO等优化特性应用用到推荐模块的编译过程中,最后取得的性能提升为**20%**。通过对比,多个模块上都可看出相同负载(调用数)下,cpu使用率明显下降。

编译优化是一项发展很成熟的技术,但在实际落地实践中仍面临一系列问题和挑战。我们遇到的问题包括以下几类:
- 编译错误:升级编译和开启PGO/LTO优化后发现了新增的编译错误,有的是业务代码不符合规范被编译器查出来,这部分需要修改代码;有的确认是误报或者暂时无法整改代码,这部分选择了屏蔽告警选项。
- 编译通过但是发现运行问题
- 反馈优化和LTO优化使用中发现的编译器bug
- 编译速度的挑战
我们协同业务团队解决了上述问题,以下将我们的实践经验分享出来。
PART 02 编译速度优化
★ 文件编译时间过长** 微信某些文件(比如mmconfig_finder.ii)编译时间过长,freport-time-details显示pta阶段的占用超过150秒(gcc -c mmconfig_finder.ii -O2 -ftime-report-details)。详见:

经排查发现,该优化pass(PTA)在gcc10得到显著优化改进(Compile-time and memory-hog hog[1])。
解决方案:建议业务团队把编译器升级到gcc10以上版本。
**★ LTO链接耗时变长**
当前的编译并没有加入LTO优化,但是LTO优化带来的效果还是比较明显,测试下来可以看到有5%左右的运行性能提升,但是引入的副作用是链接时间也会明显的变长,影响开发效率。GCC的LTO分为WPA和LTRAN两个阶段,WPA为全局符号分析阶段,目前GCC只支持串行执行;LTRAN为分析后的优化执行阶段,这个阶段可以通过并行来缩短链接时间,打开参数-flto=auto可以让编译器自动根据机器性能设置LTRANS阶段的并行数量,尽量的减小链接耗时带来的负面影响。
PART 03 编译器升级后出现的编译错误
★ MMERR打印宏引起编译器ICE(internel compiler error)
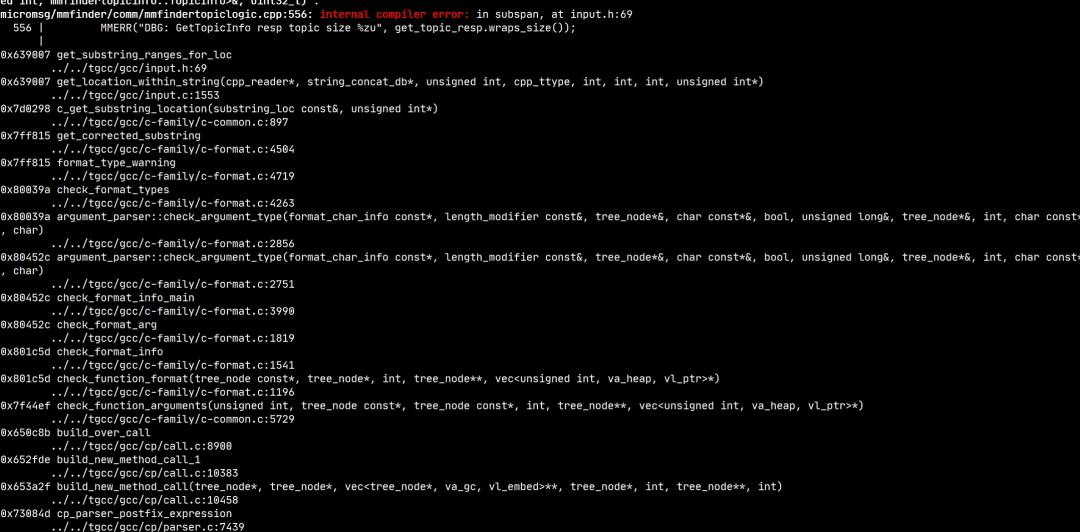
经过分析后确定是已知bug,[9 Regression] ICE in subspan, at input.h:69[2]。该bug属于前端(frontend),由于get_substring_ranges_for_loc 获得的位置信息中列号为0,导致subspan拿到的偏移量为-1。该问题修复patch包含在gcc10.3.0的更新中,tgcc升级基线后问题解决。
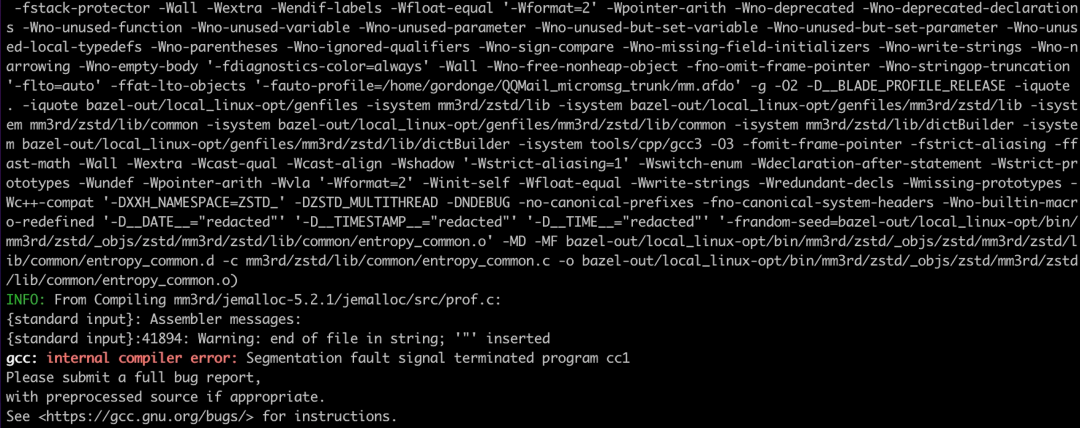
**★ AutoFDO方式编译 jemalloc/src/prof.c时栈溢出错误**
GCC的AutoFDO会将间接调用函数都内联到caller函数中,auto-profile.cc中对于递归函数并没有作特别处理,因此在遇到递归函数时会出现无限内联导致栈溢出Segment fault, GCC12中已经对这个问题作了修复,对于递归函数在AutoFDO的时候跳过内联即可。
我们将这段代码移植到对应的GCC10分支后同样解决了这个问题。
★ gcc: ICE in ipa_profile_write_edge_summary
lto+autoFDO 统一编译的时候报ipa_profile_write_edge_summary 的ICE,但是单独编译无法复现。
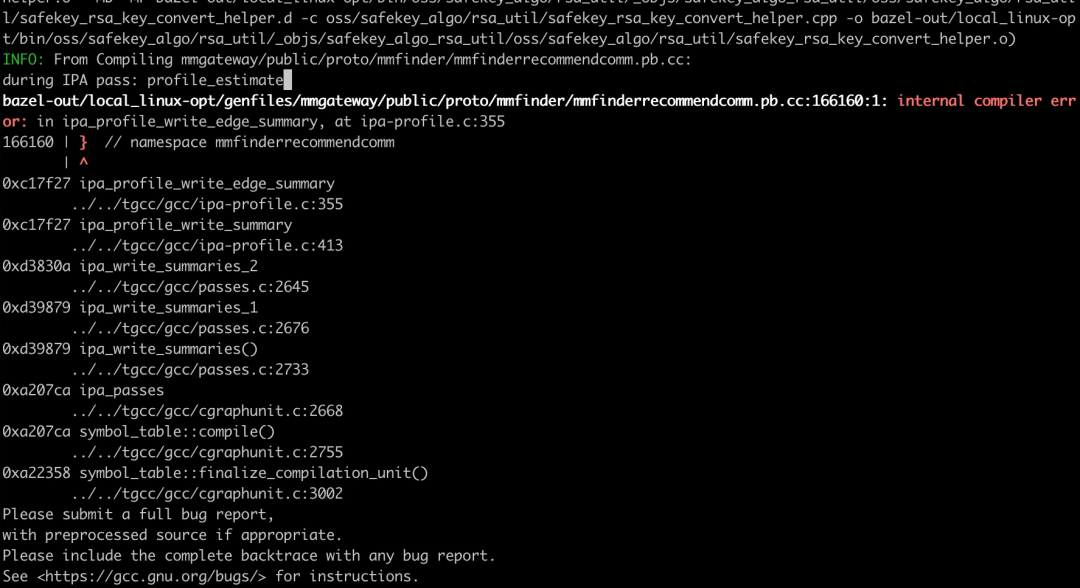
调试后发现GCC在分配indirect_call采样灰度值变量的内存空间不足,autofdo的indirect call只填了四个counter, 但是ipa_profile_genereate_summary会按照TOPN的格式去访问数据,导致访问到第5至第9个未分配内存的区域,越界产生了随机行为,调整变量内存空间后修复了此问题。
xgcc: fatal error: cannot execute '/data/mm64/mmdev/gcc10_debug/./gcc/cc1': execv: Argument list too long
微信的bazel build需要传入非常多的-isystem 参数到gcc中作为预编译头文件。gcc driver在fork后invoke cc1plus的时候参数超过256K的时候就开始报参数过长的错误:“execv: Argument list too long” 但是系统的限制约为2M,单独的测试案例直接invoke cc1plus也只会在2M之后报参数过长,需要分析看GCC在什么地方做了额外的设置导致提前报错。
内核对环境变量参数字符串长度有限制。execv在fork新的进程之前会调用copy_strings把argv和envp都拷贝到内核空间,argv的长度通过修改linux内核已经提高到2M了,但是envp的长度是由MAX_ARG_STRLEN来控制的,这个宏在devcloud机器上面是PAGESIZE*32, 也就是128K,但是在微信的编译机器上面变成了256K(微信编译机采用了修改过的Kernel,并没有用默认的MAX_ARG_STRLEN)

gcc在调用execv fork cc1前会调用libc的系统函数“putenv”设置一个很长的环境变量COLLECT_GCC_OPTIONS(相当于输入参数的长度),这个环境变量是GCC必须的,当COLLECT_GCC_OPTIONS的长度超过内核的限制时就会报参数过长的错误。
建议的解决方案为:修改linux kernel拷贝环境变量的字符串长度限制。
**★ profile-use+LTO ICE in lto-partion.c**
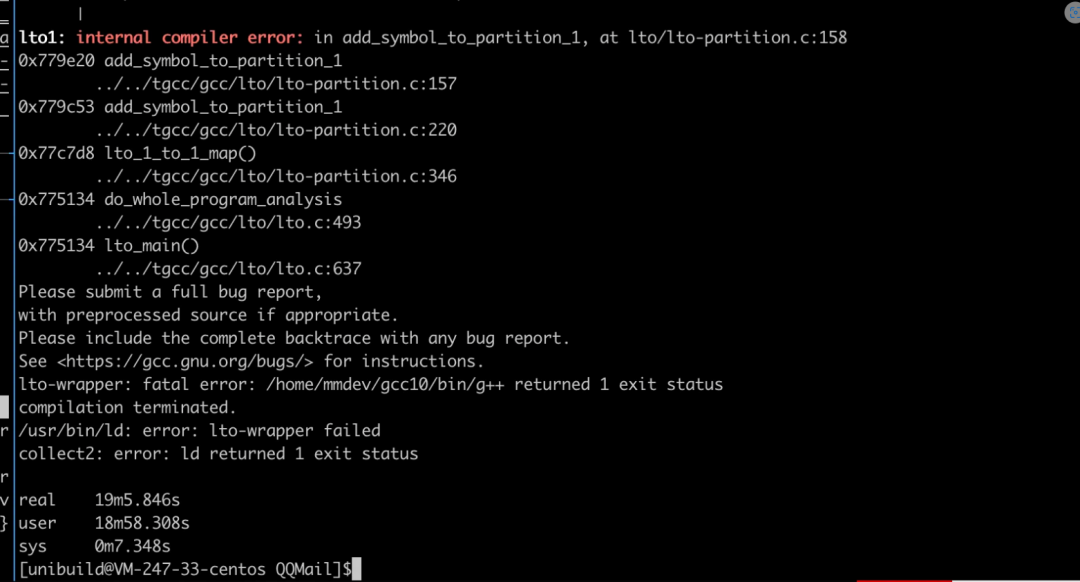
这个ICE发生在LTO的WPA阶段,牵涉到了很多链接文件,非常的难查,社区里面也经常遇到,但是并没有特别好的解决办法[3]。
视频号的推荐模块用到了2000多个静态库,包括了大量的重名函数分布在不同的库文件中,导致很难reduce成小的测试案例,不过通过隔离文件的方法找到了一种成功链接的结果用于对比,比较后发现在ipa-profile pass时两边同样的节点信息还是完全一致,但是ipa-visibility这个pass运行结束成功链接和失败链接对应函数节点的comdat group信息出现了差异,进一步跟踪后发现相同的函数节点和属性但是不同的访问顺序会导致comdat的消除出现不同的结果,原因是externally_visable变量在使用时还没有更新到预期的值,因此调整update_visibility_by_resolution_info中的检查函数来消除节点访问顺序造成的影响[4]。
PART 04 编译器升级后出现的运行问题
★ coredump**
视频号推荐模块升级到tgcc后,发现运行错误“illegal instruction",导致coredump
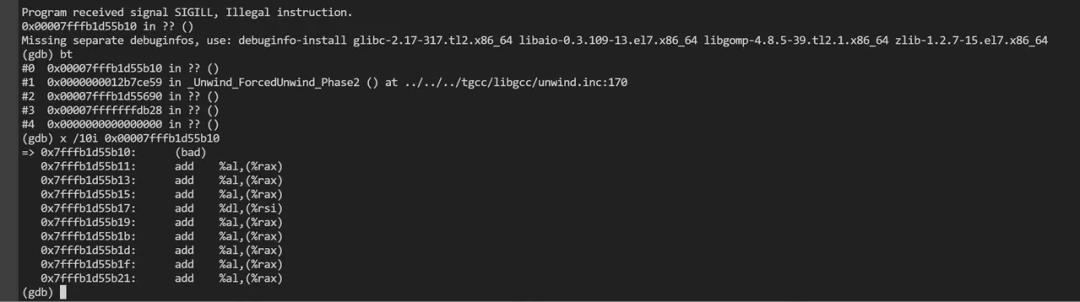
经过反复排查,发现是某个函数没有提供返回值导致。
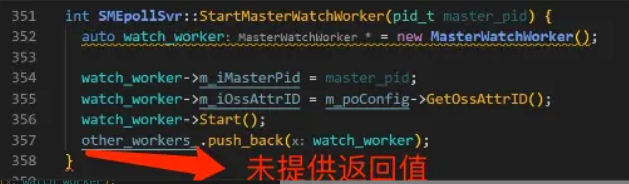
返回值未声明未void函数,实际却没有提供返回值,这在c++标准中属于未定义行为。在该函数加上返回值后,经测试确认coredump不再发生。对于此类问题,建议打开编译选项 -Werror=return-type检查此类错误,使问题可以在编译期暴露。出处:Flowing off the end of a value-returning function (except main) without a return statement is undefined behavior. return statement - cppreference.com[5]
★ 运行时火焰图函数缺失问题
微信后台开启LTO优化后符号丢失,火焰图上显示调用栈不完整或明显错误。通过分析二进制反汇编发现函数没有使用FP指针保存上下文环境,进一步发现链接选项里没有加上-fno-omit-frame-pointer,导致调用栈不能正确获取。
加上编译选项后,该问题已解决。
**★ ParseFromArray fail**
这个问题困扰了我们较长的时间,表现现象为下游返回的protobuf包数据格式不对导致解析失败,最开始出现在试用O3优化选项的时候,后面不得不回退到相对保守的O2的优化选项。
然后在灰度profile-use的时候在某些模块上面再一次出现,由于在新的模块上编译和测试时间相对短了很多,因此方便了对选项进行隔离排查。profile-use会打开20个[6]优化子选项,对这些选项进行二分隔离后定位到-ftree-loop-vectorize, 结合微信部门同事提供的问题可能在用到的第三方snappy库中,进一步确定了1.0.4版本代码的源文件中的IncrementalCopyFastPath函数由于写法有问题,强制使用了aligned的访问方式,导致源地址和目标地址重叠的时候生成了不安全的向量化指令操作。
禁掉vectorize或版本升级(1.1.4+)都可以解决此问题,但从代码安全角度考虑,采取了snappy版本升级到1.1.8的策略。

PART 05 二进制文件大小的优化
编译得到的mmfinderrecommend_1117_O2_PUSE二进制文件大小为2.6G,尽管相对于最初的GCC10 O2+LTO的3.6G减小了1G,还是显得有点大,分析二进制文件的具体内容可以发现debug信息占了将近90%的内容,binutils中的objcopy提供了一个压缩功能选项: objcopy --compress-debug-sections [xxx] [xxx.gz] 对二进制文件中的DWARF块进行zlib压缩,可以再次大幅减小二进制文件到1.2G。

各debug段具体压缩明细:有两种方式可以实现dwarf信息压缩:
- 上文提到的“objcopy --compress-debug-sections”
- --compress-debug-section这个功能已经集成在gcc编译选项中,在链接的linker_flags中加入-gz选项可以实现同样的效果。


进一步打开gc-sections优化可以将二进制文件优化到1G以内,大幅改进文件传输时间和镜像部署效率。783M Nov 30 13:13 bazel-bin/.../mmfinderrecommend结论:微信后台二进制占比最大的部分是调试信息,通过压缩调试信息和链接优化,二进制尺寸从3.6GB缩小为800MB,减少将近80%。
PART 06 总结
视频号推荐模块的PGO优化方案包含了编译器升级(GCC7 -> GCC10)和选项优化(PGO)两部分内容,在实施过程中面临了比较多的问题。
版本的升级一般来说都会带来各方面性能的提升,包括编译速度,运行速度,更高级的优化选项以及生成更高效的指令代码。但同时也可能高版本的编译器的检查选项更严格,有些以前没有暴露的错误被暴露出来,导致编译报错,有时是源代码本身的问题,也有些可能是编译器内部的问题,需要按照特定情况去解决。
在视频号模块上我们成功的实现了版本升级适配以及20%的综合性能提升,优化后的二进制文件大小减少了80%,显著的改进了部署效率。
参考
- [patch] lto: Don't run ipa-comdats pass during LTO
- Optimize Options (Using the GNU Compiler Collection (GCC))
- [RFC PATCH] ipa-visibility: Fix ICE in lto-partition caused by incorrect comdat group solving in ipa-visibility
- [1] https://gcc.gnu.org/bugzilla/show_bug.cgi?id=91257
- [2] https://gcc.gnu.org/bugzilla/show_bug.cgi?id=96935
- [3] https://gcc.gnu.org/pipermail/gcc-patches/2021-December/586302.html
- [4] https://gcc.gnu.org/pipermail/gcc-patches/2023-March/614666.html
- [5] https://en.cppreference.com/w/cpp/language/return
- [6] https://gcc.gnu.org/onlinedocs/gcc/Optimize-Options.html