一文聊聊代码的可读性
阿里妹导读
作者通过本文聊聊自己写代码的要求及代码的可读性。
观点表达

上图代码中,你觉得左边实现更好,还是右边的实现更好 ?你的代码是更像左边还是更接近右边?
首先说下,这个例子不是很好,但是我觉得又挺好,因为这个例子不够极端,但是针对这样的case去阐述观点,可以更加明确;我的观点,也是本文接下去的观点,是倾向于右边,当然在这个例子中,可能大家会觉得右边的代码有点没有必要的复杂化了,左边的代码非常简洁明晰,这里说下观点背后的思考:
- 右边的代码更好扩展,职责边界清晰,富有层次;
- 右边代码读起来更通俗,更贴近人的语言;
- 右边的代码可以更快的让你知道方法的意图(这里要说下,因为例子简单,可能大家觉得左边代码也很快能get到意图,这里说下1. 如果方法实现稍微复杂一点,左边的理解难度就要高上一点;2. 从扫眼看去,还是右边的意图更直接,虽然这里例子可能差不多了几秒)
虽然可能刚看个头,就会有一些意见上的分歧,但是我觉得本身这个命题还属于开放式的,如果是个封闭式的题目,相关的书应该已经去明确定义清楚如何去coding了,希望大家可以继续辩证地往下看,疑义相与析。
可读性理解
说可读性理解前,我们先来说说重构,我们经常做重构这件事情,小则一个月,长则一年,那我们做重构主要是为了这么几个目标:1. 让代码跑得更快;2. 让代码清爽点,精简点;3. 抽象一些方法,使用一些模式,让代码有更好的复用性和扩展性;4. 让代码读起来更流畅点;说到这里,又想问大家个问题,就上面几个目标,你觉得哪个目标的优先级最高 ?
就我个人来说,以前做重构,为了性能,场景不多,也没有为了精简去重构,精简更多的是重构过程中的一个附带的赠品,更多的是模型的调整,共同方法的抽象、沉淀,调用层次的梳理,比较耳熟能详的分层结构:DAO层、model层、manager层、biz层和service层,再说纯粹为了代码更好的去重构,基本上没有;
就此时此刻,站在一个业务技术团队的开发视角看,可读性是代码的第一优先级要求;
Readability is the code’s aptitude for communicating its intent. This means that if we assume the code works as intended, it is very easy to figure out what the code does.
[可读性是指能很好的让维护者看出代码的意图,并且实际的代码执行逻辑确实是按照维护者所直观感受到的意图来执行的]
以前在编译器还不是那么完善和智能的时候,我们还会去考虑什么样的代码,什么样的语法和调用,可以最大化的提升代码的执行速度,当时真的还蛮乐此不疲的去研究,去get这样的一些小小的提升,感觉自己很“专业”,但是这样的专业,随着时间的发展,基本上compiler目前可以比我们做的更好了,所以我们在如何和机器相处的更好的话题上,以及被compiler完全接管了,那这个时候,我们需要做的更多的是去如何和代码后面的reader(可能是你也可能是别人)做好沟通;
我们现在去迭代开发需求,花的时间的大头不在写代码上,还是在理解代码以及这段代码的上下游代码逻辑上,可能在理解的过程中还会发出一些谩骂声,然后还会下意识的去看看author ~
在我们说的很多的一个词,可维护性Maintainability,可以体现在,在做一个变更的时候,我们需要去阅读多少上下游或者相关的代码,涉及面越广,出错或者遗漏某些潜在变动的概率就大,可维护性就低;从另一个视角看,如果我们在做一个变更的时候,代码可读性越差,花的时间越长,这部分功能或者模块的可维护性就越低;
因此可读性对于维护和迭代来说,都是一个关乎效率和稳定性的关键因素;
如何提升可读性
在show观点的时候,已经提到了可读性体现优势的三个方面:更贴近人的语言(通俗表达)、方法的意图(明确意图)、层次(层次结构);
1. 通俗表达
我认为最通俗的表达,其实就是以前我们会有个习惯,在写代码之前会写伪代码,伪代码就是一种非常对co-worker友好的代码形式的表达,来看看下面这段例子(从现有工程代码里面找的)。

从这个例子看到,最通俗的表达是哪个?应该是1-9这几个comments,次之是各个备注下面的方法的命名(因为可能中翻英不是那么地道);
我们代码中对自己人最友好的就是备注,(但是有时候也会有意外,如果这个备注是过期的话),备注下方对应的方法名,可能不一定对人那么友好,一个原因是我们对于中文翻译到英文,如何翻译得准确和地道,其实拿捏不好,因为有时候我们翻译能力受限的时候是拼音+英文混搭的;另外一个原因是我们在定义方法名称的时候,没有描述到位这个方法所做的事情,要么就是描述一半,要么描述很抽象,似乎get到了点什么,似乎好像看了又等于没看;
通俗的表达的前提是有层次、有抽象、有封装,这块具体下面来讲,可以体感下这个例子:

这段代码算通俗吗?也许可能每一行都能读懂什么意思,但是整体在一起,这个if到底判断了啥,是不知道的(当然,我很取巧的把注释给你们拿了哈,这里其实这个注释的英文命名就是这个if语句条件抽象成的方法的最好定义)
这里对于通俗的表达的定义涵盖两个方面:1. 足够友好的能让后面读你代码的人能够读懂,并且是直观的通顺的理解;2. 足够准确的去描述这个方法所做的事情;再者,像遵循约定、变量/方法/类的合理命名、定义完整的文件名、规范的格式和空格空行的运用、备注等,都能帮助后续别人在读你的代码的时候,可以轻松并且明确的驾驭你的意图的;
*2. 明确意图
明确的意图本质上是现实和预期的匹配:
- 现实:代码作者在写这个方法的具体实现;
- 预期:读代码的人在看到这个方法的时候心里预期的实现;
两者如何是匹配的,那我们定义为这段代码是有明确意图,并且没有side effect的;side effect就是副作用,也可以理解为是否在明确定义的方法之下有夹带行为,这类事情其实代码中犯的很多,而且属于大家觉得不应该犯,但是多多少少个人在写的时候,都是潜意识的没注意到,看下这个例子,非常典型:
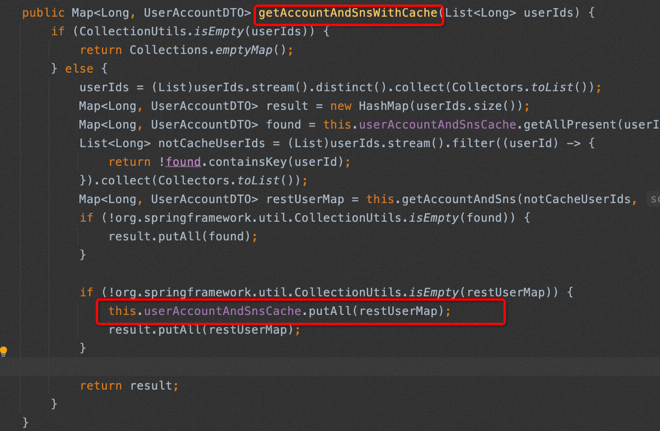
因为我们用cache、tair用的就比较多,对于tair的常规更新策略都是读未命中之后溯源查询之后回写,然后名称可以保证90%以上的都是getXXXFromCache,但是里面做着更新的事情,但是这个事情又说回来,如果整体团队都形成共识,这样的共识如果变成一种约定,可能倒也不算在side effect的范畴,但是这里我只是举了个例子;
上面说的这类是属于方法的名称没有明确的去表达方法内部的实现的范畴,还有一类,其实属于Functional Programming的范畴(FP本身是另外一个领域,这里不细说),在FP中有一个严格的要求和规范,就是不能变更入参,要保证多次执行之后的结果是一致的(框架实现中的基于context传递的面向过程的编程方式不在此列),看下下面这个例子:
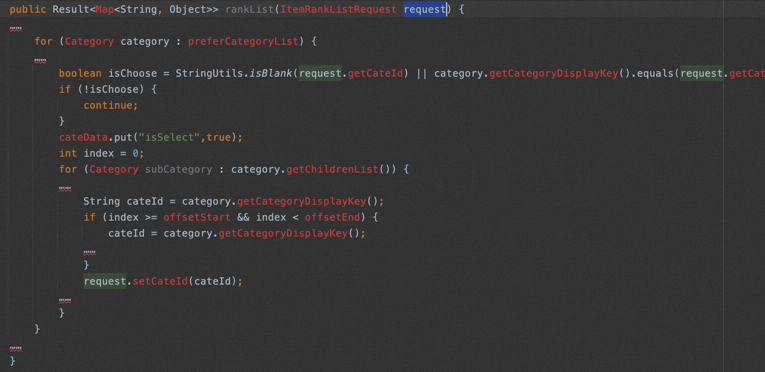
代码比较长,我把其他代码删除了,这个对于入参的修改还是比较隐形的,但是本质上是违背了FP的原则,同时后续迭代的人是不知道这个逻辑的,非常容易踩坑,因为在这里被变更掉的request的成员,可能会在之后的流程中成为重要的处理对象,但是如果后面迭代同学的预期是这个成员变量要和接口入参一致的时候,他会一脸懵逼的发现情况有点超乎自己的想象,这时候要么arthas,要么就是debug了;
side effect最大的问题大于惯性犯错,因为我们都是秉持相信上一代作者的设计、意图和结构,去做后面的需求迭代的,这时候意图的错误传达,会导致异常乃至故障的发生,同时这样的问题还非常不好排查,因为这个漏洞属于存在于惯性思维的掩护之下的;
3. 层次结构
这里说的层次结构是复杂方法内的代码层次结构,不是以前我们说的比较多的应用分层的层次结构,从一个例子入手:
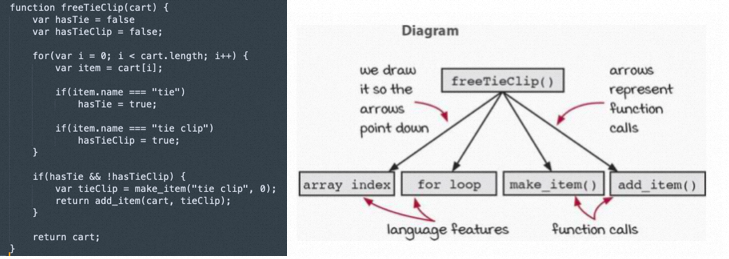
这个方法freeTieClip内部实现,调用了两个封装的方法,分别是make_item和add_item,在这个方法之前,是一段购物车商品的遍历,array_index和for loop其实和后面两个的方法调用,应该不属于一个层次的抽象,因为前两者是直接的pass through的调用(可以理解为通过 . 来执行调用的),后者属于function call,因此正确的层次描述如下:

那针对这个freeTieClip方法的层次结构优化手段也很简单,就是给前面两个的pass through调用封装一个方法:
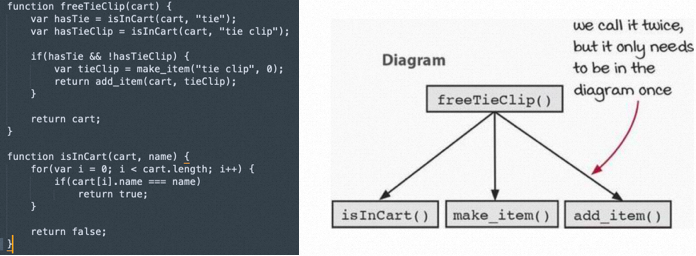
接着,如果我们要增加一个从购物车中按照name来删除一个商品的方法remove_item_by_name,大致的逻辑如下:
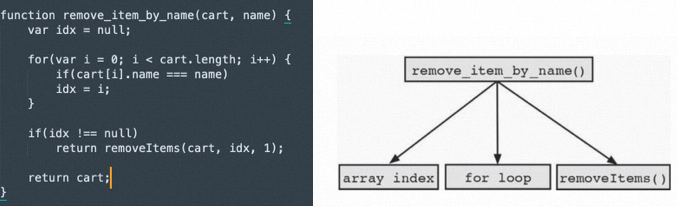
那这个方法应该是处于哪一个层次结构呢?可能的结果有如下几种:

从方法的命名的业务语义上来说,上面两层new layer above和top layer都不太合适,那从直观来说,应该是bottom layer比较符合,因为再往下down的一层new layer below是属于base的实现了;最终的层次如下所示:
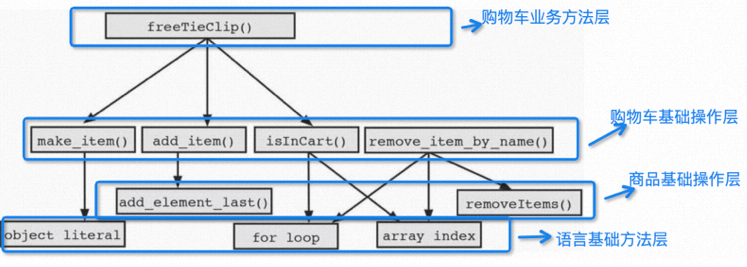
例子中所描述的分层的方法,具体在实践中可以参考,倒是不用这么严格地去做,但是这个思路还是非常有借鉴意义的,至少是赋予了一个模糊的、不好定义的可读性设计和实现提供了一种方法论;
执行过程中的建议
上面给了一些定义说明和一种分层方式,但是部分靠理解,另外一部分靠实践慢慢来体会和熟练,都属于不是马上可以应用上的,那面向如何快速在实践中做一些针对可读性的提升和做可读性待提升代码的识别,下面给几条tips,完全是for实操,背后不一定有理论能对应背书的;
- Five Lines
a.直接解释,方法实现不要超过5行,非常极端的要求,但是不是去follow这个规范,拿这个标准可以去识别潜在的可被优化的代码,帮助你去嗅到bad smell;
- Either call or pass
a.这个和上面说的分层比较像,但是没有分层那么逻辑严谨,只是一个底线可识别的逻辑,在java中可以以. 符号调用为基础操作,call具体方法,视为高级操作,下图有示意,尽量避免两种调用方式在同一个方法内;

- Use pure conditions
a.pure conditions是指该条件的运行没有额外的影响,这个和fp的要求一致,多次运行这个条件判断,1.结果是幂等的,2.没有其他隐含的行为动作,纯判断;no side effect;
- if only at the start
a.方法里面如果有if语句,尽量在方法的开头,如果在方法体中间有,那么需要把if整块语句拆分出去一个方法;

- Stay Away From Commentsa.远离注释(非方法声明注释),是个理想主义要求,但是这个tips得出的逻辑是:1.好的代码可以非常直接的表明自身的作用;2.注释是有时效性的,会随着代码的迭代而失去维护,过期,不正确;3.一个有误导的,不正确的注释会带来比较大的后续影响;
b.同样的,可以重新审视有注解的代码块,看看是否有优化的空间;
代码生成的结合
面向可读性的重构,其实是对代码结构的重新梳理,让方法更内聚,让层次更合理,目前业界用的比较多的代码生成工具是github copilot,底层基于GPT3,代码生成工具的强项其实还是在所谓的基础方法生成的范畴,业务方法的生成,应该还是离直接使用比较难,因为业务代码的生成,需要理解业务,理解商业,这个考虑到目前各类copilot训练的数据集来说,基本上不太可能完成;
从上面的层次结构的划分来说,其实copilot针对上面的“购物车基础操作层”、“商品基础操作层”中的方法,应该都可以比较好的去生成对应的代码,并且能具备比较好的代码接受率,同时这类方法都是比较容易通过单测来保障实现的正确性的;
基于以上,个人觉得后面业务团队的编码方式会产生这样的变化:业务技术同学实现业务语义到通俗编程语言语义的转换,主要包括方法的定义(包含方法的职责,实现的功能定义),方法的调用顺序(主要面向业务规则和需求),方法调用失败或异常的处理等,然后具体的子方法的内部实现,可以通过各类的代码生成工具进行,并且可以通过工具生成对应的单测,也许后面更进一步,业务产品定义代码执行流程,技术同学都不需要做programming,只需要去做验证生成的代码是否正确的debug工作。
结语
作为程序员,我们对于自己写的代码有这么几层要求:
- 1、我们的代码是可以正常运行并且能满足业务要求的;
- 2、你写的代码结构是要符合当前应用或者当前架构的规范和约束的,比如包规范、命名规范、格式规范,嵌套不能多于3层,单方法不能超过10行等约束;
- 3、你写的代码是要具备比较高的可读性的,其他程序员可以非常直白的读懂你的代码(这里绝不是指一行行读完,然后去猜想你的代码所表达的业务逻辑,而是非常直观的能get到你的代码逻辑和设计意图);
高可读性的代码编写虽说是一种技能,但是要落更多靠的还是氛围和土壤,因为本质上大家应该都能写出可读性高的代码,有时候是因为没有主动认知到,有时候是惯性的follow原系统中的“风格”,这里个人比较建议的做法是在第一遍实现代码完成自测满足业务诉求之后,回头立马针对可读性重构下自己的代码,这时候成本比较小,效果也非常不错,如果重构范围能稍微延伸到一定范围内的上下游关联代码,那更好,供借鉴;欢迎大家基于上面的表述给予建议。