Linux内核解读
工作过程中遇到的调度、内存、文件、网络等可以参考。
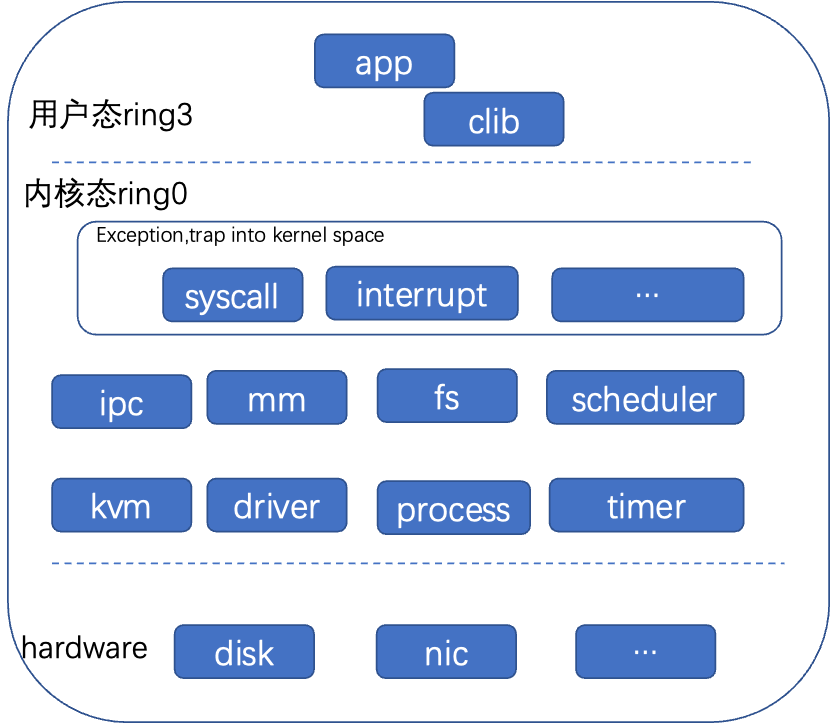
1.os运行态
X86架构,用户态运行在ring3,内核态运行在ring0,两个特权等级。
(1)内核、一些特权指令,例如填充页表、切换进程环境等,一般在ring0进行。内核态包括了异常向量表(syscall、中断等)、内存管理、调度器、文件系统、网络、虚拟化、驱动等。
(2)在ring3,只能访问部分寄存器,做协程切换等。可以运行用户程序。用户态lib、服务等。
(3)用户态crash,重启app即可;系统是安全的。内核态crash,整机需要重启。
(4)通过页表做进程隔离,进程之间内存一般不可见(共享内存除外)。而内核态内存全局可见。
2.调度
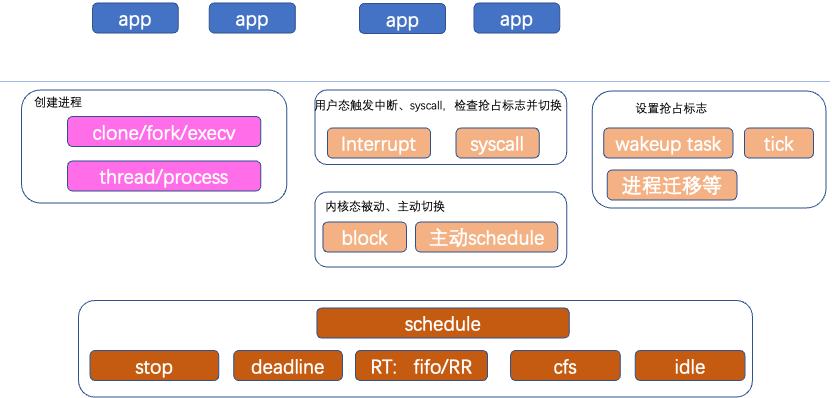
调度器由调度类(例如cfs、rt、stop、deadline、idle等,都是调度类)与通用调度模块组成(主要在core.c)。调度完整运行,需要抢占、切换机制的支持,需要有调度的上下文进程/线程。
首选可以通过clone、fork、execv等创建进程。抢占包括设置抢占标志need_schded、执行抢占两部分。设置抢占标志一般由调度类支持,例如cfs分配的quota到期,设置抢占标志;更高优先级的进程到来,设置抢占标志。
执行抢占,分为用户态抢占和内核态抢占。一般只打开用户态抢占,只有实时性要求非常高的场景,考虑打开内核态抢占。用户态抢占是指:在用户态运行时,由syscall、中断、缺页异常等陷入内核,再返回用户态时(entry_64.S),会判断是否有need_sched抢占标志,如果有,则执行抢占,通过schedule()选择新进程执行。内核态抢占,则是在内核态运行时,触发异常后,执行抢占,例如中断、tick等到来可以执行抢占。
在schedule()完成进程上下文切换,进程A切换到进程B,进程A->schedule()->进程B,保存进程A的寄存器上下文,恢复进程B的寄存器上下文,从而完成切换。
调度类按照优先级,包括stop(主要用于核间通信等)、deadline、RT、cfs、idle等。
2.1 cfs
cfs完全公平调度器。
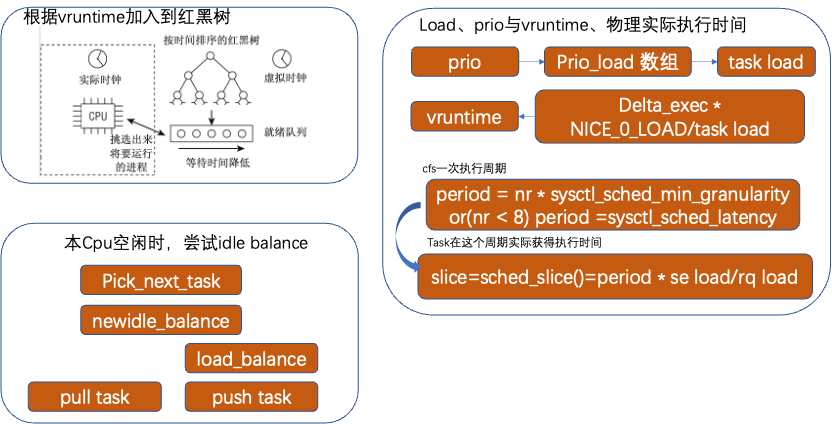
Vruntime。cfs根据虚拟时钟vruntime来决定进程执行顺序,完全公平是指进程运行的vruntime完全相同。vruntime是根据实际执行时间delta_exec、NICE_0_LOAD、task load计算得出:
vruntime = delta_exec * NICE_0_LOAD / load
或者:
(delta_exec * (NICE_0_LOAD * load->inv_weight)) >> WMULT_SHIFT
load有进程prio通过数组sched_prio_to_weight[]和sched_prio_to_wmult[]来计算。Nice值或者优先级越高,load值越大,同样物理执行时间,得到的vruntime值就越小,因此实际执行更久,但是从vruntime角度看,大家都是执行相同的虚拟时间,例如进程A prio为15和进程B prio为18,分配对应的weight值36和18,如果两个进程vruntime均执行1024ms,则对应的实际实际是delta_exec= (vruntime/ NICE_0_LOAD)load,进程A执行时间=(1024/1024)36=36ms,进程B实际执行时间(1024/1024)*18=18ms。
通过红黑树来管理进程vruntime,vruntime值越小,越靠近左侧,做左侧说明需要第一个执行,如果没有更高优先级抢占等排队。
Task一次实际执行时间,即slice。Task在cfs上对应一个调度实体se。当前队列所有进程执行一遍为一个周期period。每个进程获得的slice就是本se的load占比整体rq队列上所有进程load总和的份额,乘以period。
2.2 cfs运行机制
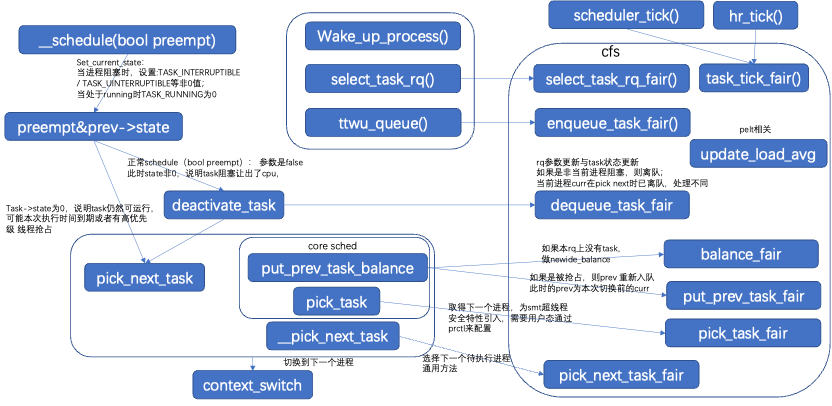
首选是唤醒进程。通过wake_up_process/wake_up_new_process等,唤醒一个进程,通常是资源准备就绪或者等待的锁被释放,然后唤醒睡眠的进程。
选核。当唤醒一个进程的时候,需要再进程cpu亲和性允许的范围内,选择最空闲或者内存亲和性最合适的cpu,然后添加到此cpu的运行队列rq上。
抢占。当前进程slice执行完毕后,时钟周期tick设置抢占标志,在合理的时机执行抢占。也可以进程主动schedule()让出cpu,或者拿锁等让出cpu。
切换。当前设置了抢占标志,在合适的抢占时机,或者进程主动让出了cpu时,需要选择下一个进程执行,通过schedule()完成切换。
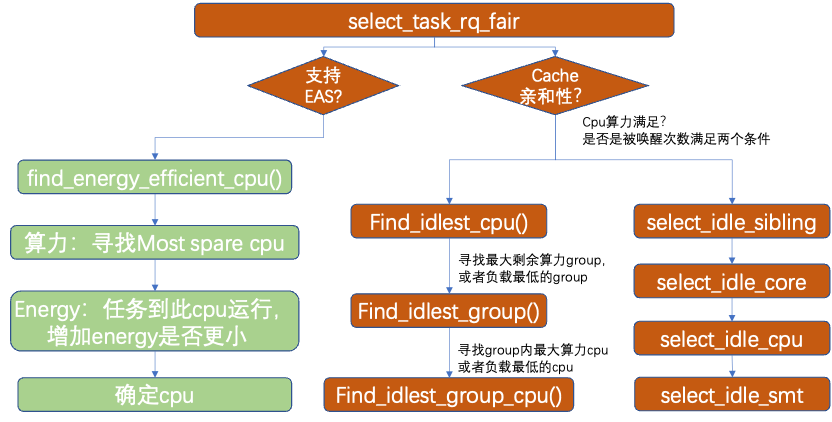
2.3 cfs: select_task_rq_fair
进程唤醒时,需要选择合适的cpu。如果支持EAS,则会选择比较节能的cpu。没有打开EAS支持,则考虑cache亲和性和cpu空闲程度。如果符合cache亲和性要求,则优先选择共享cache的cpu(例如同一个sd_llc域内的),否则选择更空闲的cpu(此时可以选择不同的numa节点上的cpu,不在同一个sd_llc域)。
3.内存管理
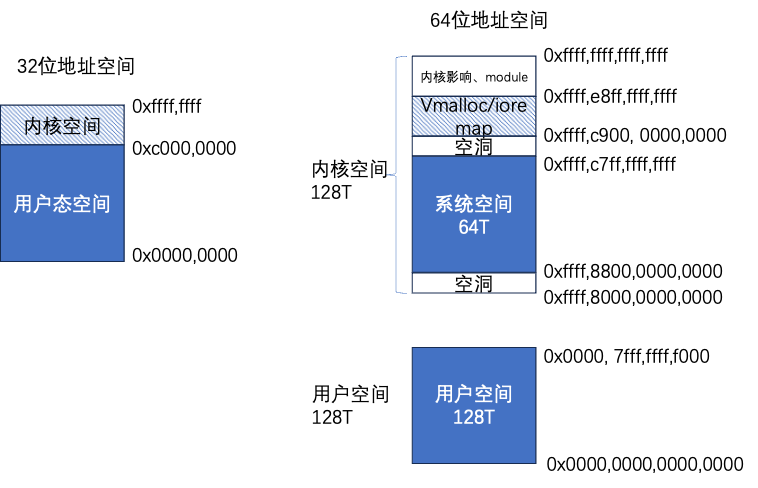
内存管理包括虚拟内存和物理内存。64位地址空间0x0000,0000,0000,0000。
~0x0000, 7fff,ffff,f000为用户态空间地址,0xffff,8800,0000,0000~0xffff,ffff,ffff,ffff为内核态空间地址(除去部分空洞)。
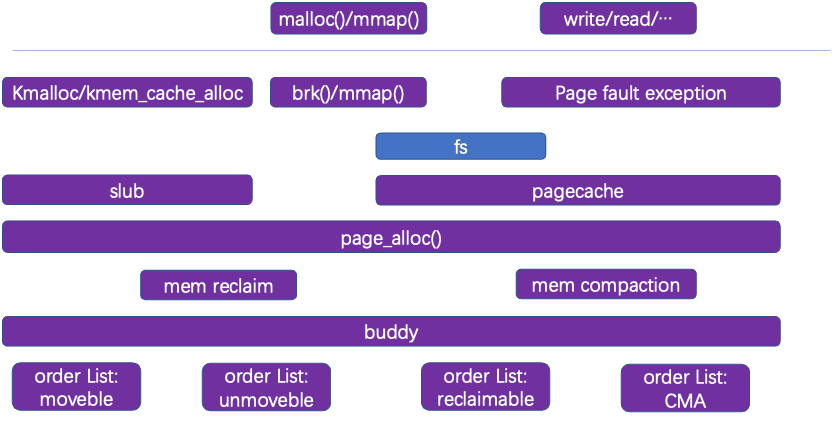
用户态部分,有mmap、malloc(实际brk)、不同语言分配接口等分配虚拟内存。read、write等fs相关系统调用也可以直接访问页缓存。
内核部分,内存管理由slub子系统(支持小内存分配)和伙伴系统buddy(管理所有分配给内核使用的可见页)组成。功能包括了内存映射(map与缺页异常)、内存分配、内存回收、内存迁移等组成。
3.1物理内存类型与组织结构
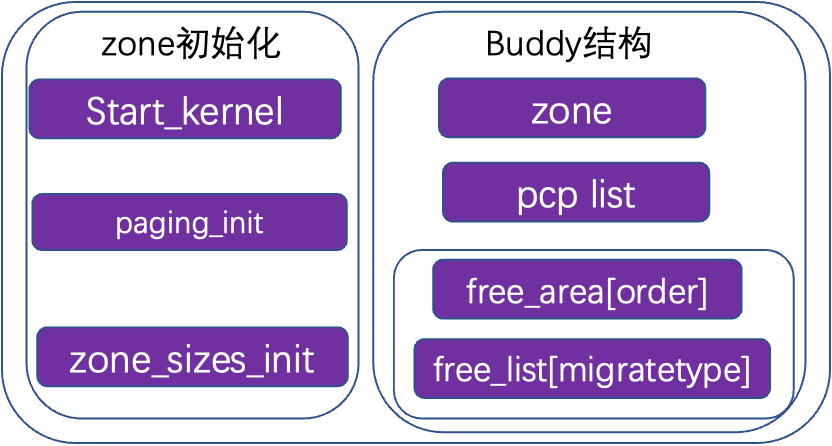
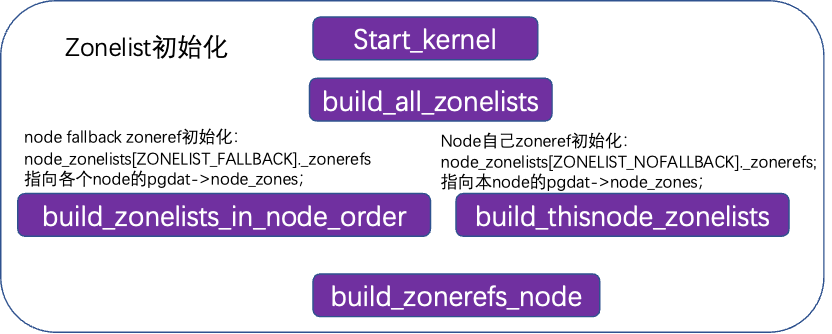
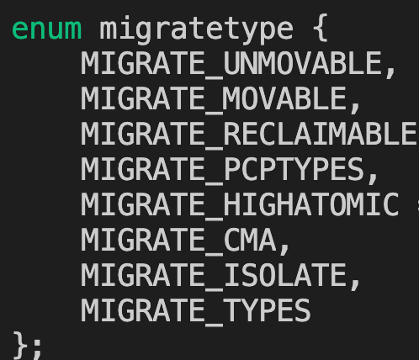
系统启动的时候,在start_kernel对内存管理进行初始化,通过build_all_zonelists生成buddy结构。伙伴系统buddy结构包括了一个pcp list和free_area[],pcp list直接管理部分页,可以加速单页内存分配,free_area是主要管理结构,以order为索引,每一个数组成员包括了不同内存类型的list,例如unmovable/movable/reclaimable/cma等,均有一个list链表,管理本order size的页。
物理内存类型,可以减少内存碎片,内存类型一般以pageblock为一个单位(1024 page,4M),一个pageblock为一个类型。
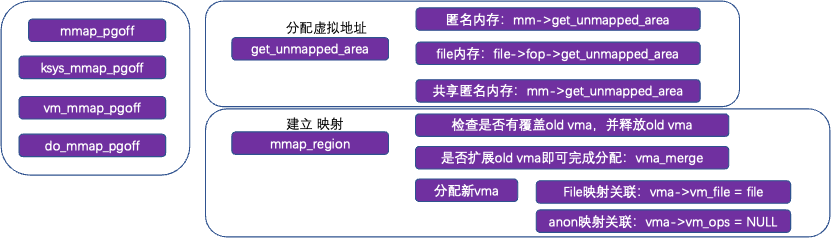
3.2 mmap/malloc与虚拟内存
mm_struct *mm, mm->mm_rb.rb_node,一颗红黑树管理用户态地址空间,已分配的虚拟地址通过vma结构管理,包含一段内存区域,例如:[100, 2000],根据vma对应的虚拟地址加入到红黑树;再次分配的时候,从红黑树找到合适gap(没有添加到树,还未分配)
匿名地址通过进程地址空间mm->get_unmapped_area分配,File虚拟地址通过fs,例如ext4: thp_get_unmapped_area分配,mmap_region:通常只分配虚拟地址,建立虚拟地址与file/anon的关系,实际访问时,缺页异常完成物理地址分配。
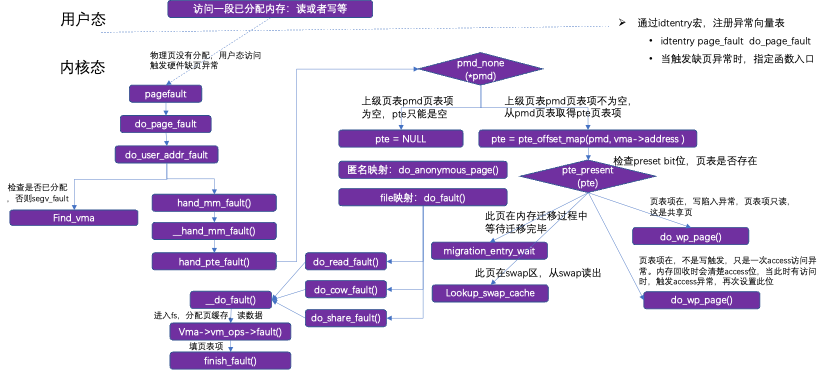
3.3缺页异常
4.fs
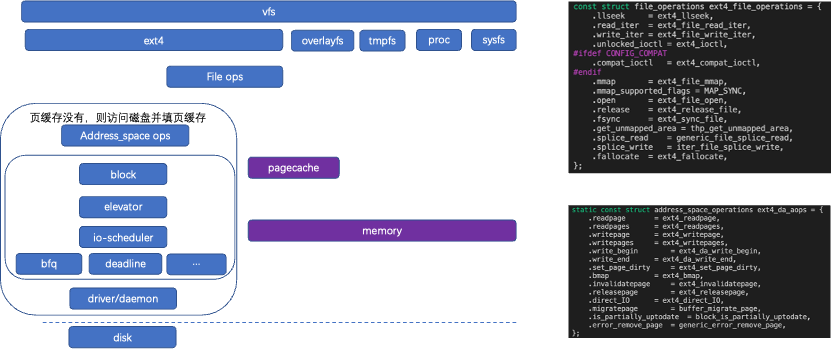
4.1 Fs架构
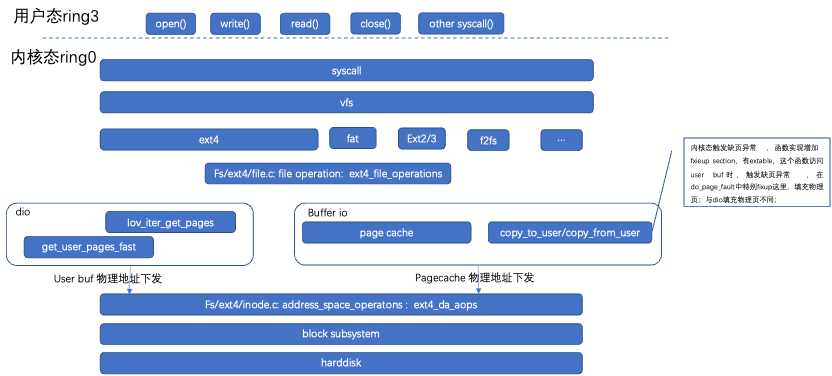
4.2 ext4 块组layout文件组织
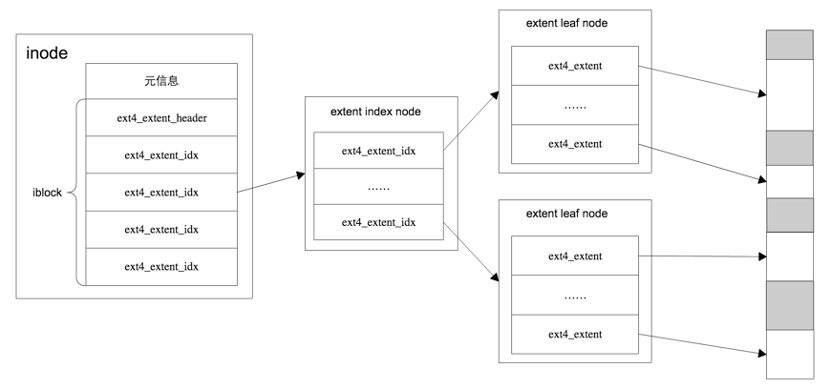
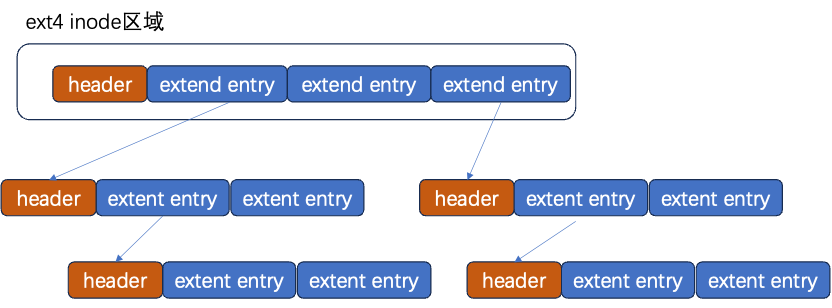
区段extents根据内容分为索引节点 extent_idx ,内容叶子节点extent。
extent内容包含了起始的block地址和length,length占16个字节,因此对于4KB的block,每个extent能定位128M连续的寻址空间。
inode默认有4个extent,每个extent可以直接指向一段连续的block;如果这4个extent不能满足文件大小,则extent变成extent_idx索引节点 ,形成一个BTree。
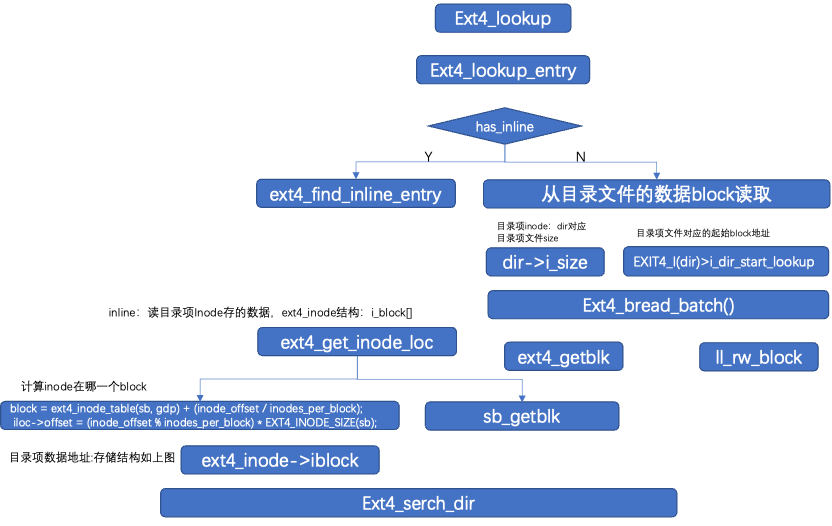
4.3目录项结构


4.4文件:内存组织形式
地址空间:struct adress space:page->mapping
读写文件分两级:页缓存、磁盘页缓存。
通过基数树管理mapping->i_page。基数树索引:page->index = offset >> PAGE_SHIFT;page通过index加到树上;Index即为文件内偏移(不同的访问,index语义不同);磁盘(页缓存没有缓存或者数据不是updated);逻辑块地址:iblock:page->index <<(PAGE_SHIFT - BBITS);ext4通过extent树管理。

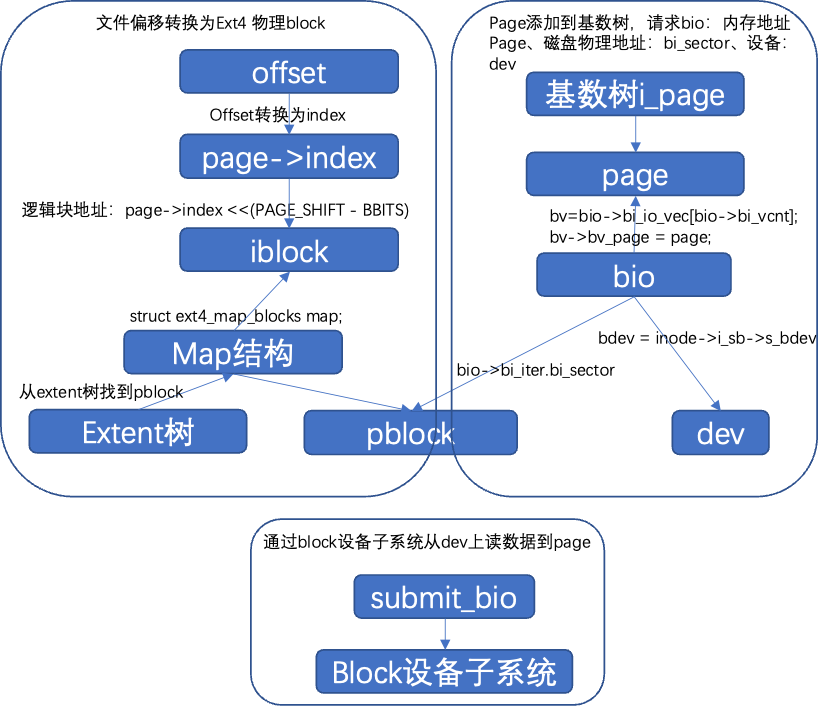
4.5 extent树:文件的磁盘组织结构
inode:对应一个文件,文件元数据管理结构。Extent树:EXT4_I(inode)->i_es_tree,区域树保存在ext4 磁盘inode info结构中,根据逻辑block号,把区域结构添加到区域树,区域结构:struct extent_status,包含了逻辑块号、物理块号、区域的块数,可能是索引块,也可能是叶子节点,通过区域树上的节点对应的物理block来存储文件数据。
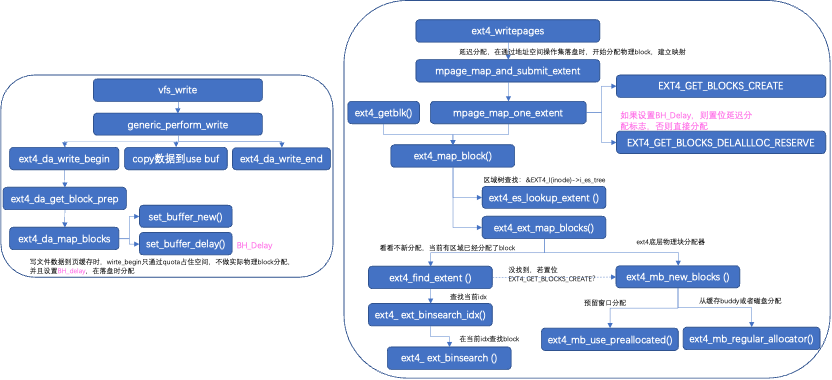
文件系统包括写页缓存,落盘两部分。写页缓存对应file operations操作集,把数据copy到页缓存。落盘把数据回写磁盘,对应fs地址空间操作集。
5. 网络
5.1 Tcp/ip协议层次结构
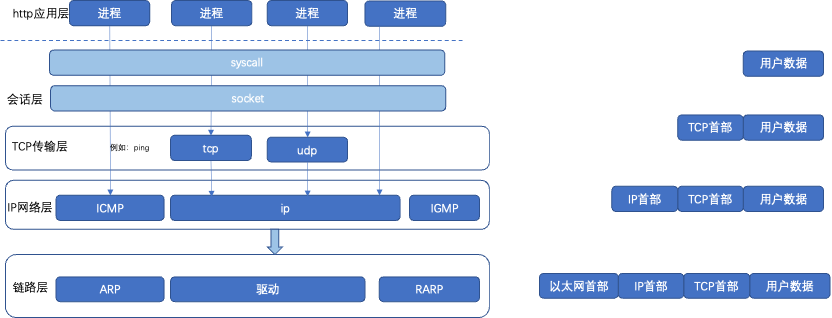
网络协议栈分层,分为http应用层、会话层、tcp传输层、ip网络层、链路层。每一层协议,数据报文对应右边的组成。
5.2建立连接
建立连接
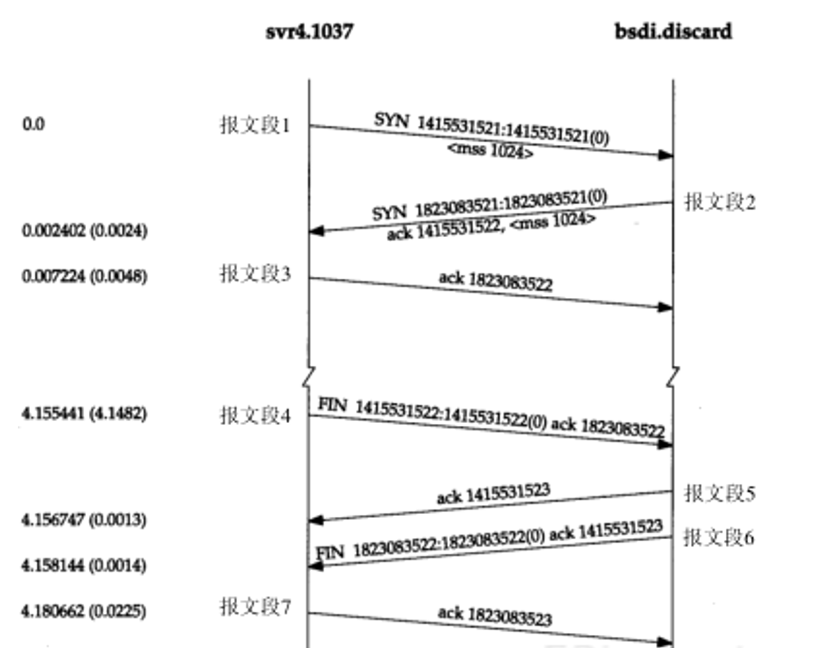
请求端(通常称为客户)发送一个SYN段指明客户打算连接的服务器的端口,以及初始序号(ISN,在这个例子中为1415531521)。这个SYN段为报文段1。
服务器发回包含服务器的初始序号的SYN报文段(报文段2)作为应答。同时,将确认序号设置为客户的ISN加1以对客户的SYN报文段进行确认。一个SYN将占用一个序号。
客户必须将确认序号设置为服务器的ISN加1以对服务器的SYN报文段进行确认(报文段3)。
这三个报文段完成连接的建立。这个过程也称为三次握手(three-way handshake)。
终止连接
终止一个连接要经过4次握手。这由TCP的半关闭(halfclose)造成的。
TCP连接是全双工(即数据在两个方向上能同时传递),因此每个方向必须单独地进行关闭。
原则就是当一方完成它的数据发送任务后就能发送一个FIN来终止这个方向连接。当一端收到一个FIN,它必须通知应用层另一端几经终止了那个方向的数据传送。发送FIN通常是应用层进行关闭的结果。
5.3概念
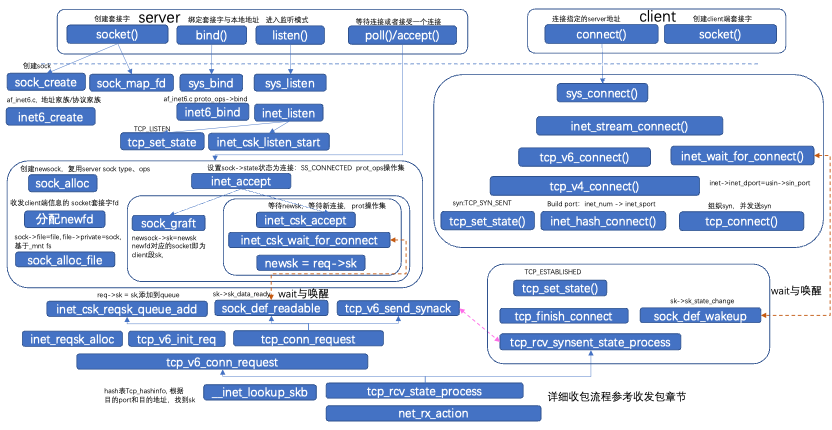
窗口分为滑动窗口和拥塞窗口。滑动窗口是接受数据端使用的窗口大小,用来告知发送端接收端的缓存大小,以此可以控制发送端发送数据的大小,从而达到流量控制的目的。tp->snd_wnd:发送窗口大小、tp->snd_una:执行已发送但未收到确认的第一个字节 序列号,实际为滑动窗口起始序列号(连续收到了,要向右滑动)tp->nxt:执行未发送但可发送的第一个字节序列号;tp->rcv_wnd:接受窗口大小、tp->rcv_nxt:期望从发送方发送的下一个序列号报文、rcv_wup:上一个窗口更新的rcv_nxt;数据的发送端是拥塞窗口,拥塞窗口不代表缓存,拥塞窗口指某一源端数据流在一个RTT内可以最多发送的数据包数。
RTT(Round Trip Time)
往返时延,也就是数据包从发出去到收到对应 ACK 的时间。RTT 是针对连接的,每一个连接都有各自独立的 RTT。
RTO(Retransmission Time Out)
重传超时。TCP协议,这种算法的基本要点是TCP监视每个连接的性能(即传输时延),由此每一个TCP连接推算出合适的RTO值,当连接时延性能变化时,TCP也能够相应地自动修改RTO的设定,以适应这种网络的变化。使用自适应算法(Adaptive Retransmission Algorithm)以适应互联网分组传输时延的变化。
5.4数据传输
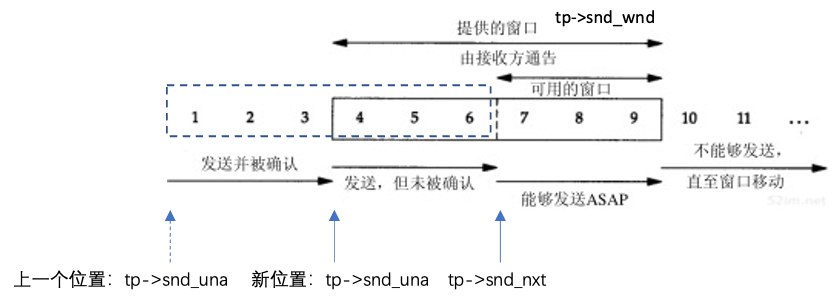
发送方首先传送3个数据报文段(4~6)。下一个报文段(7)仅确认了前两个数据报文段(确认序号为2048而不是3073)。
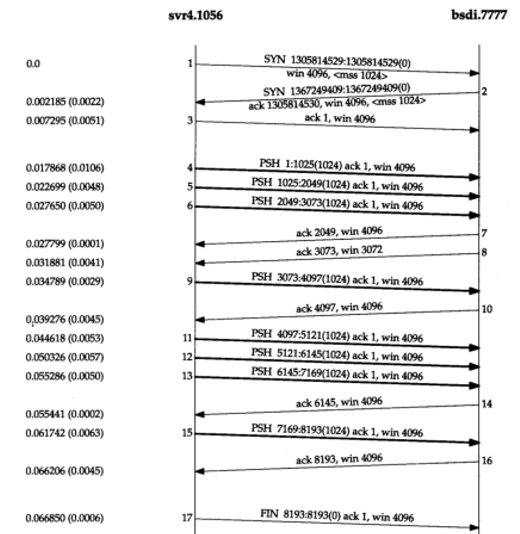
报文段8中的窗口大小为3072,表明在TCP的接收缓存中还有1024个字节的数据等待被应用程序读取。
报文段11~16说明了通常使用的“隔一个报文段确认”的策略。报文段11、12和13到达并被放入IP的接收队列。当报文段11被处理时,连接被标记为产生一个经受时延的确认。当报文段12被处理时,它们的ACK(报文段14)被产生且连接的经受时延的确认标志被清除。报文段13使得连接再次被标记为产生经受时延。但在时延定时器溢出之前,报文段15处理完毕,因此该确认立刻被发送
报文段7、14和16中的ACK确认了两个收到的报文段是很重要的。使用TCP的滑动窗口协议时,接收方不必确认每一个收到的分组
收发包流程
5.5拥塞算法
慢启动算法
窗口cwnd
当拥塞发生时,我们希望降低分组进入网络的传输速率.
慢启动将根据这个往返时间中所收到的确认的个数增加cwnd,发送方发送一个报文段,收到该ACK时,拥塞窗口从1增加为2,即可以发送两个报文段。当收到这两个报文段的ACK时,拥塞窗口就增加为4等
拥塞避免算法
拥塞避免算法要求每次收到一个确认时将cwnd增加1/cwnd
拥塞发生
如果超时,发送方仍未收到确认报文,那么TCP就会认为当前网络已经发生拥塞。采用慢开始算法进行处理。
收到连续3个重复的ACK报文如果发送方收到了连续3个重复的ACK报文,那么TCP也会认为当前网络发生了拥塞.
平时两个算法切换,至少一个算法生效
拥塞发生时(超时或收到重复确认),ssthresh被设置为当前窗口大小的一半,如果是超时引起了拥塞,则cwnd被设置为1个报文段(这就是慢启动)
当新的数据被对方确认时,就增加cwnd,依赖于是否正在进行慢启动或拥塞避免。如果cwnd小于或等于ssthresh,则正在进行慢启动,否则正在进行拥塞避免。慢启动一直持续到我们回到当拥塞发生时所处位置的半时候才停止,然后转为执行拥塞避免。
5.6拥塞状态
open状态:
open状态是常态, 这种状态下tcp 发送放通过优化后的快速路径来接收处理ack,当一个ack到达时, 发送方根据拥塞窗口是小于还是大于 满启动阈值,按照慢启动或者拥塞避免来增大拥塞窗口。
disorder 状态:
当发送方收到 DACK 或者SACK的时候, 将变为disorder 状态, 再次状态下拥塞窗口不做调整,但是没到一个新到的段 就回触发发送一个新的段发送出去此时TCP 遵循发包守恒原则,就是一个新包只有在一个老的包离开网络后才发送;拥塞窗口恒定,网络中数据包守恒。
cwr 状态:
发送发被通知出现拥塞通知, 直接告知!!比喻通过icmp 源端抑制 等方式通知,当收到拥塞通知时,发送方并不是立刻减少拥塞窗口, 而是每个一个新到的ack减小一个段 知道窗口减小到原来的一半为止,发送方在减小窗口过程中如果没有明显重传,就回保持cwr 状态, 但是如果出现明显重传,就回被recovery 或者loss 中断而进入 loss recovery 状态;拥塞窗口减小,且没有明显的重传。
recovery状态:
在收到足够多的连续重复的ack 后,发送方重传第一个没有被确认的段,进入recovery 状态,默认情况下 连续收到三个重复的ack 就回进入recovery状态,在recovery状态期间,拥塞窗口的大小每隔一个新到的确认就会减少一个段, 和cwr 一样 出于拥塞控制期间,这种窗口减少 终止于大小等于ssthresh,也就是进入recovery状态时窗口的一半。发送方重传被标记为丢失的段,或者根据包守恒原则 发送数据,发送方保持recovery 状态直到所有recovery状态中被发送的数据被确认,此时recovery状态就回变为open,超时重传可能中断recovery状态。
Loss 状态 :
当一个RTO到期,发送方进入Loss 状态 , 所有正在发送的段都被标记为丢失段,拥塞窗口设置为一个段。发送方启动满启动算法增大窗口。Loss 状态是 拥塞窗口在被重置为一个段后增大,但是recovery状态是拥塞窗口只能被减小, Loss 状态不能被其他状态中断,所以只有所有loss 状态下开始传输的数据得到确认后,才能到open状态, 也就是快速重传不能在loss 状态下触发。当一个RTO 超时, 或者收到ack 的确认已经被以前的sack 确认过, 则意味着我们记录的sack信息不能反应接收方实际的状态,此时就回进入Loss 状态。
5.7拥塞传输场景
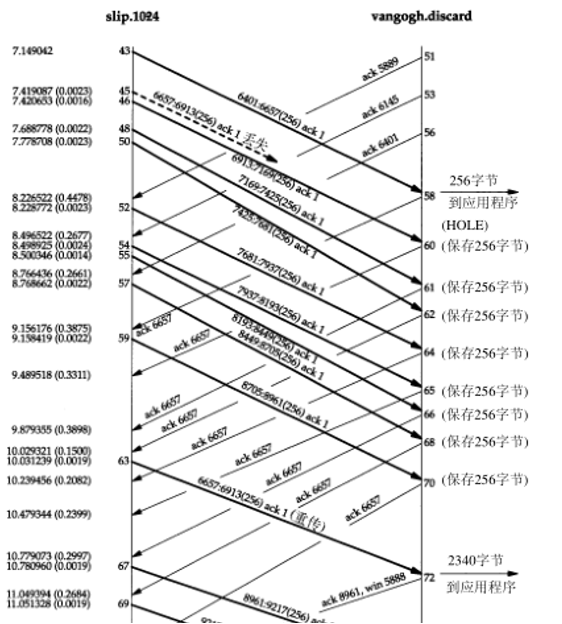
报文段45丢失或损坏;接收到报文段62,也就是第3个重复ACK,引起自序号6657开始的数据报文段(报文段63)进行重传。在重传后(报文段63),发送方继续正常的数据传输(报文段67、69和71)。TCP不需要等待对方确认重传。当缺少的报文段(报文段63)到达时,接收方TCP在其缓存中保存第6657~8960字节的数据,并将这2304字节的数据交给用户进程。所有这些数据在报文段72中进行确认。请注意此时该ACK通告窗口大小为5888(8192-2304)。
5.8定时器
创建超时定时器
cp_v4_init_sock
|-> tcp_init_sock
|-> tcp_init_xmit_timers
|-> inet_csk_init_xmit_timers
在初始化连接时,设置三个定时器实例的处理函数:
icsk->icsk_retransmit_timer的处理函数为tcp_write_timer()
icsk->icsk_delack_timer的处理函数为tcp_delack_timer()
sk->sk_timer的处理函数为tcp_keepalive_timer()删除超时定时器
tcp_done
tcp_disconnect
tcp_v4_destroy_sock
|-> tcp_clear_xmit_timers
|-> inet_csk_clear_xmit_timers
void inet_csk_clear_xmit_timers(struct sock *sk) { struct inet_connection_sock *icsk = inet_csk(sk); icsk->icsk_pending = icsk->icsk_ack.pending = icsk->icsk_ack.blocked = 0; sk_stop_timer(sk, &icsk->icsk_retransmit_timer); sk_stop_timer(sk, &icsk->icsk_delack_timer); sk_stop_timer(sk, &sk->sk_timer); }激活超时定时器
icsk->icsk_retransmit_timer和icsk->icsk_delack_timer的激活函数为inet_csk_reset_xmit_timer(),
超时重传定时器在以下几种情况下会被激活:
1.发现对端把保存在接收缓冲区的SACK段丢弃时。
2.发送一个数据段时,发现之前网络中不存在发送且未确认的段。
之后每当收到确认了新数据段的ACK,则重置定时器。
3.发送SYN包后。
4.一些特殊情况。