清华大模型报告称,文心一言数学能力与Claude-3并列第一
最近,由清华大学基础模型研究中心联合中关村实验室研制的SuperBench大模型综合能力评测框架,正式对外发布2024年3月版《SuperBench大模型综合能力评测报告》。评测共包含了14个海内外具有代表性的模型,结果显示:文心一言4.0表现亮眼,与国际一流模型水平接近,且差距已经逐渐缩小,名副其实为国内头部模型。
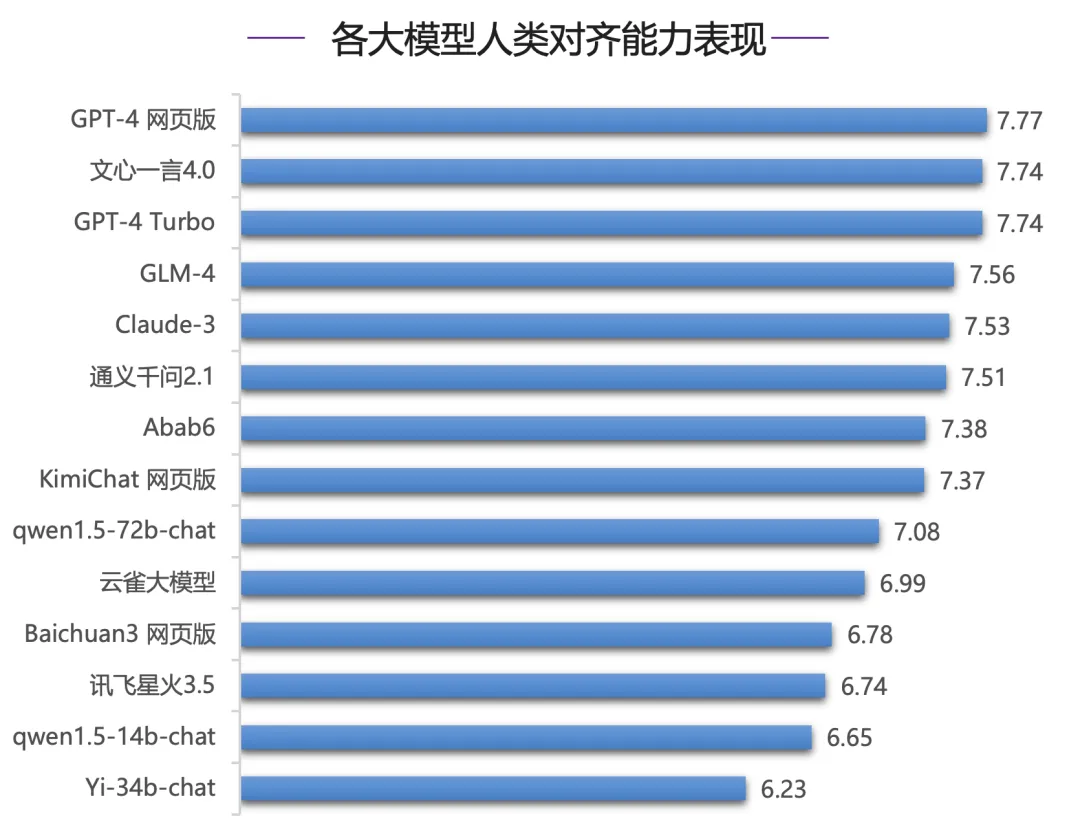
在语义理解中的数学能力上,文心一言4.0与Claude-3并列全球第一;GPT-4系列模型位列第四五,其他模型得分在55分附近较为集中,明显落后第一梯队;而在语义理解中的阅读理解能力上,文心一言4.0超过GPT-4 Turbo、Claude-3以及GLM-4拿下榜首。