Chromium硬件加速渲染的GPU数据上传机制分析
在Chromium中,WebGL端、Render端和Browser端通过命令缓冲区将GPU命令发送给GPU进程执行。GPU命令携带的简单参数也通过命令缓冲区发送给GPU进程,但复杂参数,例如纹理数据,有可能太大,以致于命令缓冲区无法容纳,因此要通过其它机制传递给GPU进程。本文接下来就主要以纹理数据上传为例,分析WebGL端、Render端和Browser端将GPU命令数据传递给GPU进程的机制。
WebGL端、Render端和Browser端将GPU命令附携带的大数据传递给GPU进程的基本思路通过其它的共享缓冲区进行传递。也就是先将GPU命令携带的大数据写入到共享缓冲区中,然后再将GPU命令携带的大数据参数修改为前面已经写入了数据的共享缓冲区的ID。GPU进程通过这个ID就可以找到对应的共享缓冲区,进而得到真正的GPU命令数据,最后就可以执行对应的OpenGL函数。
有些操作系统对能创建的共享内存的大小有限制。当一个GPU命令携带的数据的大小超过这个限制的时候,那么就不能通过一块共享缓冲区一次性将数据传递给GPU进程。这时候就需要对数据进行分块传输。有些GPU命令的数据本身就支持分块传输,这种情况的处理就比较简单。例如,对于纹理上传命令gles2::cmds::TexImage2D,可以通过gles2::cmds::TexSubImage2D命令对其携带的纹理数据进行分块传输,如图1所示:

图1 纹理数据分块上传机制
在图1中,我们假设一个gles2::cmds::TexImage2D命令要上传的纹理数据可以划分为1、2和3三个子块,每一个子块都可以通过一块共享缓冲区进行传递。这时候一个gles2::cmds::TexImage2D命令就被分拆成三个gles2::cmds::TexSubImage2D子命令,每一个gles2::cmds::TexSubImage2D子命令负责处理一个子数据块。这些gles2::cmds::TexSubImage2D子命令最终在GPU进程中转化为OpenGL函数glTexSubImage2D调用,每一个glTexSubImage2D函数都负责上传一个数据子块到GPU中。
很不幸,并不是所有的GPU命令都像gles2::cmds::TexImage2D命令一样,存在对应的子命令,例如gles2::cmds::ShaderSource命令,它不存在对应的gles2::cmds::ShaderSubSource子命令。这时候就需要使用一种称为Bucket的机制来分块上传GPU命令数据。以gles2::cmds::ShaderSource命令为例,它携带的Shader源代码的分块上传机制如图2所示:

图2 Shader源代码分块上传机制
在图2中,我们同样假设gles2::cmds::ShaderSource命令要上传的数据可以划分为1、2和3三个子块,每一个子都可以通过一块共享缓冲区进行传递。每一个数据子块都是通过一个gles2::cmds::SetBucketData命令保存在GPU进程中的同一个Bucket中的。每一个Bucket都具有一个ID,前面已经准备好了数据的Bucket的ID接下来再通过一个gles2::cmds::ShaderSourceBucket命令传递给GPU进程。GPU进程有了这个Bucket的ID之后,就可以获得它里面的数据,进而可以调用OpenGL函数glShaderSource,从而完成对gles2::cmds::ShaderSource命令的处理。
不难发现,上面描述的两种GPU命令数据分块上传机制都是通过共享缓冲区进行的,这就涉及到这些共享缓冲区的管理问题,也就是分配和释放的问题。为了更好地认识这个问题,我们首先简单介绍一下Chromium的纹理上传机制。Chromium提供了同步和异步纹理上传机制。
我们知道,在Chromium中,所有的GPU命令都是在GPU进程的一个线程中执行的,这个线程称为GPU主线程。将纹理上传命令全部交给GPU主线程执行就称为同步纹理上传,如图3所示:

图3 同步纹理上传
在图3中,我们假设一个命令缓冲区有五个GPU命令需要执行,其中第一个GPU命令是同步纹理上传命令gles2::cmds::TexImage2D,对应的OpenGL函数是glTexImage2D。由于使用的是同步纹理上传方式,因此,在纹理上传命令执行完成之前,后面的四个命令是不能执行的。
与GPU的图形计算和渲染速度相比,将数据从CPU传递到GPU的速度是相当慢的。这就使得纹理上传操作是GPU的一个瓶颈,特别是数据量很大的纹理。对于图3来说,就会造成后面的四个命令需要等待比较长时间才会被执行。
为了解决纹理上传速度慢的问题,Chromium提供了另外一种纹理上传方式----异步纹理上传,如图4所示:
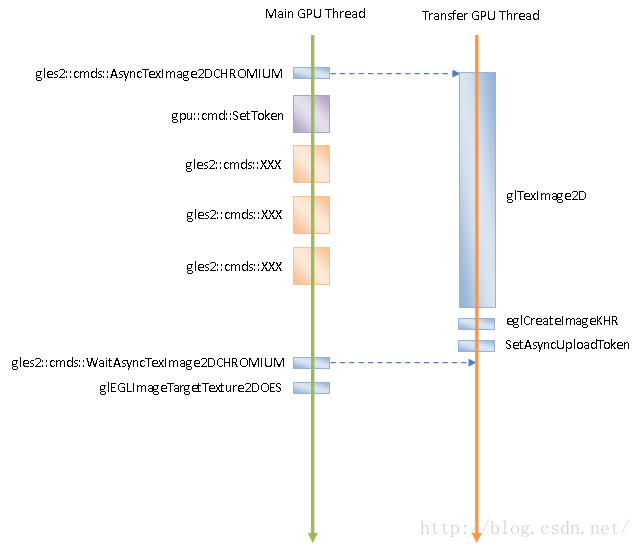
图4 异步纹理上传
在异步纹理上传方式中,GPU进程中使用一个专门的线程用作纹理上传,这个线程称为GPU传输线程。在图4中,我们同样假设一个命令缓冲区有五个GPU命令需要执行,其中第一个GPU命令是异步纹理上传命令gles2::cmds::AsyncTexImage2DCHROMIUM。这个异步纹理上传命令被GPU主线程发送给GPU传输线程处理。GPU传输线程调用OpenGL函数执行异步纹理上传命令。与此同时,GPU主线程也在执行后面的四个命令。
GPU传输线程上传纹理完毕,会将通过EGL函数eglCreateImageKHR将已经上传的纹理封装成一个EGLImageKHR对象。GPU主线程会在空闲的时候检查异步上传的纹理是否已经上传完成。对于已经上传完成的纹理,GPU主线程会通过OpenGL函数glEGLImageTargetTexture2DOES将绑定在当前激活的OpenGL上下文中。这意味着GPU主线程可以访问在GPU传输线程中上传完毕的纹理。这是一种跨线程的纹理共享机制。正是由于这个纹理共享机制,才使得异步纹理上传成为可能。
有时候,GPU进程的Client端需要知道一个异步纹理上传命令什么时候执行完成,这时候它可以向GPU进程发送一个gles2::cmds::WaitAsyncTexImage2DCHROMIUM。GPU主线程在处理gles2::cmds::WaitAsyncTexImage2DCHROMIUM的时候,就会等待GPU传输线程完成纹理上传。当然,如果这时候GPU传输线程已经完成纹理上传,那么GPU主线程就不用等待。GPU主线程结束等待之后,也会检查已经上传完成的纹理是否已经绑定在当前激活的OpenGL上下文中。如果还没有绑定,那么也会通过OpenGL函数glEGLImageTargetTexture2DOES将绑定在当前激活的OpenGL上下文中。
从图4我们就可以看到,通过异步纹理上传方式,后面的四个命令可以与前面的纹理上传命令并发执行,从而提高了全部五个命令的执行时间,从而可以在一定程度上解决纹理上传速度慢的问题。
GPU进程的Client端向GPU进程发送的同步纹理上传命令gles2::cmds::TexImage2D和异步纹理上传命令gles2::cmds::AsyncTexImage2DCHROMIUM,都指定了一个共享缓冲区,这个共享缓冲区保存了要上传的纹理数据。GPU进程的Client端不知道这个共享缓冲区什么时候释放,因为它不知道GPU进程什么时候使用完成这个共享缓冲区,也就是不知道纹理上传命令什么时候被执行。但是GPU进程的Client端必须知道上述共享缓冲区什么时候使用完成,以便可以对它进行回收。那么GPU进程的Client端是通过什么方式知道一个共享缓冲区什么时候不再被GPU进程使用的呢?我们分同步纹理上传和异步纹理上传两种情况讨论。
在同步纹理上传方式中,GPU主线程执行完成一个gles2::cmds::TexImage2D命令,就意味着该gles2::cmds::TexImage2D命令引用的共享缓冲区已经使用完毕。GPU进程的Client端往命令缓冲区写入一个gles2::cmds::TexImage2D命令之后,会接着在后面再写入一个gpu::cmd::SetToken命令,如图5所示:

图5 同步Token机制
上述gpu::cmd::SetToken命令关联了一个同步Token值。这个同步Token值由GPU进程的Client端维护,并且与前面被gles2::cmds::TexImage2D命令引用的共享缓冲区对应。GPU进程的Client每往命令缓冲区写入一个gpu::cmd::SetToken命令,都会将其维护的同步Token值增加1,作为下一个gpu::cmd::SetToken命令的同步Token值。
GPU主线程处理完成一个gpu::cmd::SetToken命令之后,会在当前激活的OpenGL上下文中记录该gpu::cmd::SetToken命令关联的同步Token值。这样,GPU进程的Client端通过比较一个共享缓冲区的同步Token值与该Client端在GPU进程中对应的OpenGL上下文记录的当前同步Token值的大小,就可以知道该共享缓冲区是否可以进行回收。
在异步纹理上传方式中,通过上述的同步Token机制,不能确定一个共享缓冲区是否能够进行回收,因为紧跟在异步纹理上传命令后面的gpu::cmd::SetToken命令有可能比异步纹理上传命令本身要提前执行完成。这时候需要使用另外一种异步Token机制,如图6所示:

图6 异步Token机制
异步纹理上传命令不仅gles2::cmds::AsyncTexImage2DCHROMIUM不仅指定了一个共享缓冲区,还指定了一个异步Token值。这个异步Token值同样也是由GPU进程的Client端维护的,并且与异步纹理上传命令指定的共享缓冲区相关联。GPU传输线程执行完成一个异步纹理上传命令之后,会通过函数SetAsyncUploadToken将该异步纹理上传命令指定的异步Token值设置到当前激活的OpenGL上下文中去。这样,GPU进程的Client端通过比较一个共享缓冲区的异步Token值与该Client端在GPU进程中对应的OpenGL上下文记录的当前异步Token值的大小,就可以知道该共享缓冲区是否可以进行回收。
通过上述的同步和异步Token机制,GPU的Client端就可以对那些用来传递数据的共享缓冲区进行管理了。接下来我们就首先分析这些共享缓冲区的管理。
在前面Chromium硬件加速渲染的OpenGL命令执行过程分析一文中提到,GPU进程的Client端在初始化OpenGL上下文的过程中,会创建和初始化一个TransferBuffer对象和一个BufferTracker对象,如下所示:
bool GLES2Implementation::Initialize(
unsigned int starting_transfer_buffer_size,
unsigned int min_transfer_buffer_size,
unsigned int max_transfer_buffer_size,
unsigned int mapped_memory_limit) {
......
if (!transfer_buffer_->Initialize(
starting_transfer_buffer_size,
kStartingOffset,
min_transfer_buffer_size,
max_transfer_buffer_size,
kAlignment,
kSizeToFlush)) {
return false;
}
mapped_memory_.reset(
new MappedMemoryManager(
helper_,
base::Bind(&GLES2Implementation::PollAsyncUploads,
// The mapped memory manager is owned by |this| here, and
// since its destroyed before before we destroy ourselves
// we don't need extra safety measures for this closure.
base::Unretained(this)),
mapped_memory_limit));
......
buffer_tracker_.reset(new BufferTracker(mapped_memory_.get()));
......
return true;
} 这个函数定义在文件external/chromium_org/gpu/command_buffer/client/gles2_implementation.cc中。
GLES2Implementation类的成员变量transfer_buffer_指向的是一个TransferBuffer对象,GLES2Implementation类的成员函数Initialize调用它的成员函数Initialize对它进行初始化。这个TransferBuffer对象初始化完成后,GPU进程的Client端就可以通过它分配一些共享缓存区,用来和GPU进程传递数据。
GLES2Implementation类的成员函数Initialize接下来创建了一个MappedMemoryManager对象,并且以这个MappedMemoryManager对象为参数,创建了一个BufferTracker对象,保存在成员变量buffer_tracker_中。以后GPU进程的Client端也可以通过这个BufferTracker分配共享缓冲区,用来和GPU进程传递数据。
接下来,我们就继续分析TransferBuffer类和BufferTracker类的实现,以便了解它们是如何管理共享缓冲区的。
我们从TransferBuffer类的成员函数Initialize开始分析TransferBuffer类的实现,如下所示:
bool TransferBuffer::Initialize(
unsigned int default_buffer_size,
unsigned int result_size,
unsigned int min_buffer_size,
unsigned int max_buffer_size,
unsigned int alignment,
unsigned int size_to_flush) {
result_size_ = result_size;
default_buffer_size_ = default_buffer_size;
min_buffer_size_ = min_buffer_size;
max_buffer_size_ = max_buffer_size;
alignment_ = alignment;
size_to_flush_ = size_to_flush;
ReallocateRingBuffer(default_buffer_size_ - result_size);
return HaveBuffer();
}这个函数定义在文件external/chromium_org/gpu/command_buffer/client/transfer_buffer.cc中。
各个参数的含义如下所示:
default_buffer_size:表示默认分配的共享缓冲区的大小。
result_size:当TransferBuffer用来将数据从GPU进程返回给GPU进程的Client端时,分配出来的缓冲区的头部用来填写返回值。这个头部的大小就由参数result_size描述。
min_buffer_size:表示允许分配的共享缓冲区的最小值。
max_buffer_size:表示允许分配的共享缓冲区的最大值。
alignment:分配出来的共享缓冲区被划分为一个个的子缓冲区进行使用,这些子缓冲区的大小要对齐到参数alignment描述的值。
size_to_flush:当从共享缓冲区分配出去的子缓冲区的大小达到参数size_to_flush描述的值后,GPU进程的Client端就会请求GPU进程执行命令缓冲区的命令,以便可以回收这些命令引用的子缓冲区。
TransferBuffer类的成员函数Initialize将上述参数分别保存在对应的成员变量中后,就调用另外一个成员函数ReallocateRingBuffer分配共享缓冲区,如下所示:
void TransferBuffer::ReallocateRingBuffer(unsigned int size) {
// What size buffer would we ask for if we needed a new one?
unsigned int needed_buffer_size = ComputePOTSize(size + result_size_);
needed_buffer_size = std::max(needed_buffer_size, min_buffer_size_);
needed_buffer_size = std::max(needed_buffer_size, default_buffer_size_);
needed_buffer_size = std::min(needed_buffer_size, max_buffer_size_);
if (usable_ && (!HaveBuffer() || needed_buffer_size > buffer_->size())) {
if (HaveBuffer()) {
Free();
}
AllocateRingBuffer(needed_buffer_size);
}
}这个函数定义在文件external/chromium_org/gpu/command_buffer/client/transfer_buffer.cc中。
TransferBuffer类的成员函数ReallocateRingBuffer首先根据参数size和成员变量resultsize、min_buffer_size_和max_buffer_size_计算出应该分配的共享缓冲区的大小needed_buffer_size。
TransferBuffer类的成员变量usable_ 的值初始化为true,接下来如果因为大小限制不能成功分配到共享缓冲区,那么该成员变量的值就会被设置为false。
当TransferBuffer类的成员变量buffer_的值不等于NULL时,它指向的是一个Buffer对象,该Buffer对象描述的就是一个共享缓冲区,这时候调用TransferBuffer类的成员函数HaveBuffer得到的返回值就为true,并且调用该Buffer对象的成员函数size可以获得的它描述的共享缓冲区的大小。
因此,TransferBuffer类的成员函数ReallocateRingBuffer所做的事情就是判断要求分配的共享缓冲区的大小是否合适。如果合适,并且之前还没有分配过共享缓冲区,或者之前已经分配过,但是分配的大小小于前面计算出来的应该分配的大小,那么就需要重新分配一块大小等于needed_buffer_size的共享缓冲区。当然,如果之前已经分配过共享缓冲区,那么这块共享缓冲区会首先被释放掉,这是通过调用TransferBuffer类的成员函数Free实现的。
最后,TransferBuffer类的成员函数ReallocateRingBuffer通过调用另外一个成员函数AllocateRingBuffer分配一块大小等于needed_buffer_size的共享缓冲区,如下所示:
void TransferBuffer::AllocateRingBuffer(unsigned int size) {
for (;size >= min_buffer_size_; size /= 2) {
int32 id = -1;
scoped_refptr<gpu::Buffer> buffer =
helper_->command_buffer()->CreateTransferBuffer(size, &id);
if (id != -1) {
DCHECK(buffer);
buffer_ = buffer;
ring_buffer_.reset(new RingBuffer(
alignment_,
result_size_,
buffer_->size() - result_size_,
helper_,
static_cast<char*>(buffer_->memory()) + result_size_));
buffer_id_ = id;
result_buffer_ = buffer_->memory();
result_shm_offset_ = 0;
return;
}
// we failed so don't try larger than this.
max_buffer_size_ = size / 2;
}
usable_ = false;
}这个函数定义在文件external/chromium_org/gpu/command_buffer/client/transfer_buffer.cc中。
TransferBuffer类的成员函数AllocateRingBuffer在保证要分配的共享缓冲区的大小size不小于允许的最小值min_buffer_size_的前提下,分配一个大小等于size的共享缓冲区。
如果能成功分配,那么分配出来的共享缓冲区使用一个Buffer对象来描述。这个Buffer对象保存在TransferBuffer类的成员变量buffer_中。并且分配出的共享缓冲区的ID保存在TransferBuffer类的成员变量buffer_id_中。前面提到,分配出来的共享缓冲区的头部用来保存从GPU进程读取数据时的结果,因此这个头部的地址就等于分配出来的共享缓冲区的起始地址,保存在TransferBuffer类的成员变量result_buffer_中。同时,TransferBuffer类的成员变量result_shm_offset_表示上述用来保存结果的头部位于分配出来的共享缓冲区的偏移位置,它的值被设置为0。
如果不能成功分配,那么就可能是请求分配的大小太大了,于是就尝试减少一半的大小,即以(size / 2)的大小,再次尝试分配。这时候也需要相应地调整允许分配的共享缓冲区的最大值max_buffersize,也就是允许分配的共享缓冲区的最大值max_buffer_size_就等于(size / 2)。这个过程一直持续下去,直到分配成功,或者请求分配的大小小于允许的最小值min_buffer_size_为止。如果是后一种情况,那么TransferBuffer类的成员变量usable_的值就会被设置为false,表示请求分配的共享缓冲区大小不合适,导致不能成功到一块共享缓冲区。
从前面Chromium硬件加速渲染的OpenGL命令执行过程分析一文可以知道,TransferBuffer类的成员变量helper_指向的是一个GLES2CmdHelper对象,调用这个GLES2CmdHelper对象的成员函数command_buffer可以获得一个CommandBufferProxyImpl对象。有了这个CommandBufferProxyImpl对象之后,就可以调用它的成员函数CreateTransferBuffer创建一个能够与GPU进程进行共享的缓冲区,并且这个缓冲区会注册在GPU进程中。
通过CommandBufferProxyImpl类的成员函数CreateTransferBuffer分配的共享缓冲区都有一个相应的ID,以后GPU进程的Client端通过一个ID值就可以告诉GPU进程它是通过哪一个共享缓冲区来传递数据的。关于CommandBufferProxyImpl类的成员函数CreateTransferBuffer的实现,可以参考前面Chromium硬件加速渲染的OpenGL命令执行过程分析一文。
前面提到,分配出来的共享缓冲区是划分成一个个子缓冲区使用的。这些子缓冲区通过一个RingBuffer对象来管理。这个RingBuffer对象保存在TransferBuffer类的成员变量ring_buffer_中。也就是说,以后我们想在上述共享缓冲区拿出一小块来传递数据给GPU进程或者从GPU进程读回数据时,就可以通过TransferBuffer类的成员变量ring_buffer_描述的RingBuffer对象分配这一小块缓冲区,并且在使用完毕时,将这一小块缓冲区重新交给它管理。
GPU进程的Client端可以通过调用TransferBuffer类的成员函数AllocUpTo或者Alloc从它的成员变量ring_buffer_描述的共享缓冲区中分配一小块指定大小的缓冲区,接下来我们就分别分析它们的实现。
TransferBuffer类的成员函数AllocUpTo的实现如下所示:
void* TransferBuffer::AllocUpTo(
unsigned int size, unsigned int* size_allocated) {
......
unsigned int max_size = ring_buffer_->GetLargestFreeOrPendingSize();
*size_allocated = std::min(max_size, size);
bytes_since_last_flush_ += *size_allocated;
return ring_buffer_->Alloc(*size_allocated);
}这个函数定义在文件external/chromium_org/gpu/command_buffer/client/transfer_buffer.cc中。
TransferBuffer类的成员函数AllocUpTo调用成员变量ring_buffer_指向的一个RingBuffer对象的成员函数GetLargestFreeOrPendingSize可以获得该RingBuffer对象描述的共享缓冲区可分配的子缓冲区的最大值max_size,即空闲部分的大小。这时候如果请求分配的大小size大于可分配的最大值max_size,那么实际分配的大小就会调整为可分配的最大值max_size,并且记录在输出参数size_allocated中。
确定了实际要分配的子缓冲区的大小之后,就会调用TransferBuffer类的成员函数AllocUpTo就会调用ring_buffer_指向的RingBuffer对象的成员函数Alloc进行分配。在分配之前,也会相应地增加TransferBuffer类的成员变量bytes_since_last_flush_的值,这个成员变量描述的是自从上次向GPU进程提交新的GPU命令以来,从成员变量ring_buffer_指向的RingBuffer对象描述的共享缓冲区分配出去的子缓冲区的大小。以后会通过这个值来决定是否要向GPU进程提交新的GPU命令。
TransferBuffer类的成员函数Alloc的实现如下所示:
void* TransferBuffer::Alloc(unsigned int size) {
......
unsigned int max_size = ring_buffer_->GetLargestFreeOrPendingSize();
if (size > max_size) {
return NULL;
}
bytes_since_last_flush_ += size;
return ring_buffer_->Alloc(size);
}这个函数定义在文件external/chromium_org/gpu/command_buffer/client/transfer_buffer.cc中。
与前面分析的TransferBuffer类的成员函数AllocUpTo不同,TransferBuffer类的成员函数Alloc如果发现请求分配的子缓冲区的大小size大于可分配的最大值max_size,那么就会导致分配失败。
另一方面,如果请求分配的子缓冲区的大小size小于等于可分配的最大值max_size,那么TransferBuffer类的成员函数Alloc也是通过调用ring_buffer_指向的RingBuffer对象的成员函数Alloc来分配子缓冲区。
RingBuffer类的成员函数Alloc的实现如下所示:
void* RingBuffer::Alloc(unsigned int size) {
......
// Similarly to malloc, an allocation of 0 allocates at least 1 byte, to
// return different pointers every time.
if (size == 0) size = 1;
// Allocate rounded to alignment size so that the offsets are always
// memory-aligned.
size = RoundToAlignment(size);
// Wait until there is enough room.
while (size > GetLargestFreeSizeNoWaiting()) {
FreeOldestBlock();
}
if (size + free_offset_ > size_) {
// Add padding to fill space before wrapping around
blocks_.push_back(Block(free_offset_, size_ - free_offset_, PADDING));
free_offset_ = 0;
}
Offset offset = free_offset_;
blocks_.push_back(Block(offset, size, IN_USE));
free_offset_ += size;
if (free_offset_ == size_) {
free_offset_ = 0;
}
return GetPointer(offset + base_offset_);
}这个函数定义在文件external/chromium_org/gpu/command_buffer/client/ring_buffer.cc中。
我们通过图7来理解RingBuffer类的成员函数Alloc的实现,如下所示:
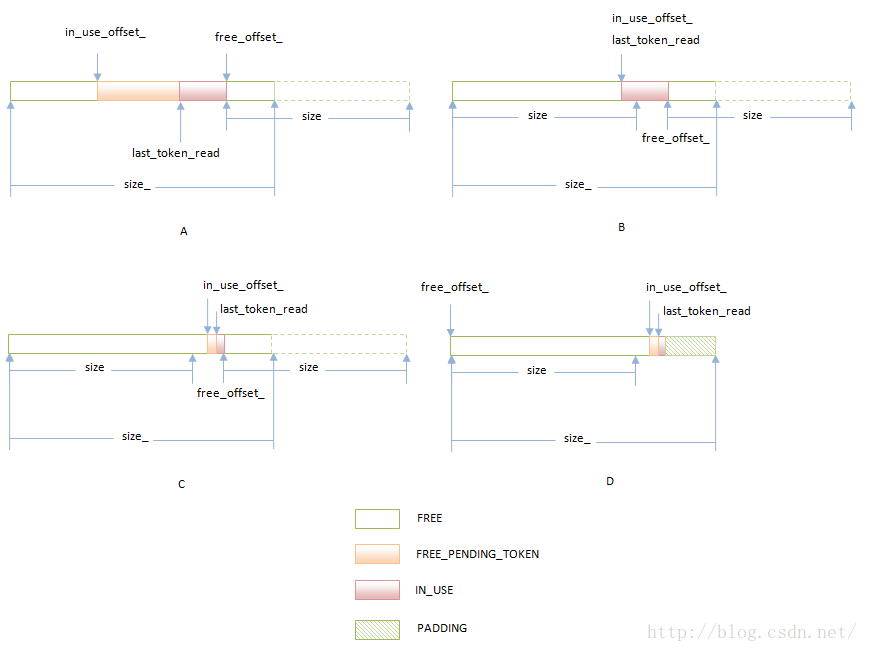
图7 子缓冲区分配过程
整个共享缓冲区的大小为size_,请求分配的子缓冲区的大小为size。当前正在使用的所有子缓冲在地址空间上是连续的。这块连续的地址空间的起始地址为in_use_offset_中。当前空闲的缓冲区可能分为两部分。一部分位于共享缓冲区的头部,另一部分位于尾部。其中,位于尾部的空闲缓冲区紧跟在正在使用的缓冲区的结束位置上。这个位置记录在free_offset_中。
当前正在使用的每一个子缓冲区,也就是分配出去的子缓冲区,都关联有一个Token值,并且它们处于两种状态之一。一种状态是FREE_PENDING_TOKEN,另一种状态是IN_USE。IN_USE是指一个子缓冲区正在被GPU进程的Client端使用,同时也被GPU命令缓冲区引用。FREE_PENDING_TOKEN是指一个子缓冲区不被GPU进程的Client端使用,但是被GPU命令缓冲区引用。
例如,GPU进程的Client端请求GPU进程执行一个纹理上传操作,上传的纹理数据要拷贝到一个子缓冲区去。在拷贝的过程中,这个子缓冲区的状态为IN_USE。拷贝完毕,GPU进程的Client端往GPU命令缓冲区写入到一个gles2::cmds::TexImage2D命令,该命令引用了上述子缓冲区。这时候GPU进程的Client端就将保存了纹理数据的子缓冲区的状态设置为FREE_PENDING_TOKEN,并且在命令缓冲区中写入一个gpu::cmd::SetToken命令,表示虽然GPU进程的Client端不需要使用该子缓冲区了,但是GPU命令缓冲区仍然引用着它。
接下来,GPU进程先后从GPU命令缓冲区将前面写入的gles2::cmds::TexImage2D命令和gpu::cmd::SetToken命令读取出来处理。处理完成gles2::cmds::TexImage2D命令的时候,就意味着该gles2::cmds::TexImage2D命令引用的子缓冲区使用完毕,但是GPU进程的Client端并不知道。处理完成gpu::cmd::SetToken命令的时候,GPU进程将该gpu::cmd::SetToken命令关联的Token值记录为当前激活的OpenGL上下文的Token值。
GPU进程的Client端发现空闲缓冲区大小不足时,就会获得GPU进程为它创建的OpenGL上下文的当前Token值,保存在last_read_token中。如果一个处于FREE_PENDING_TOKEN状态的子缓冲关联的token值小于等于这个last_read_token值,那么就说明这个子缓冲也不再被GPU命令缓冲区引用了,这时候它的状态就可以修改为FREE。
有了上面的背景的知识之后,我们就通过图7来分析RingBuffer类的成员函数Alloc。假设这时候共享缓冲区的状态如A所示。在A中,共享缓冲区连续的可分配的空闲缓冲区大小小于请求分配的子缓冲区的大小size。这时候RingBuffer类的成员函数Alloc就调用成员函数GetLargestFreeSizeNoWaiting回收那些处于FREE_PENDING_TOKEN状态的、并须Token值小于等于last_read_token的子缓冲区。注意,这些子缓冲区是可以马上回收的,不需要等待。
回收了处于FREE_PENDING_TOKEN状态的、并且Token值小于等于last_read_token的子缓冲区之后,假设共享缓冲区的状态如B所示。这时候共享缓冲区连续的可分配的空闲缓冲区大小仍然小于请求分配的子缓冲区的大小size。于是RingBuffer类的成员函数Alloc就调用成员函数FreeOldestBlock回收最早分配出去的子缓冲区。注意,这个子缓冲区的状态有可能是处于FREE_PENDING_TOKEN状态的,但是它的Token值大于last_read_token,也有可能是处于IN_USE状态。无论是哪一种,回收它都需要进行等待,也就是要等待GPU进程处理完毕GPU命令缓冲区中引用了它的命令。
上述过程持续进行,直到共享缓冲区的状态如C所示。这时候共享缓冲区连续的可分配的空闲缓冲区大小大于等于请求分配的子缓冲区的大小size。 但是这部分空闲缓冲区可能是位于共享缓冲区头部的。这意味着尾部的空闲缓冲区由于大小不足,必须要跳过。在跳过之前,它的状态被设置为PADDING。状态为PADDING的子缓冲被当作是已经被分配出去的,但是没有实际使用。等到它前面处于IN_USE状态的子缓冲区被回收后,它们就可以合在一起重新被使用。
跳过尾部大小不足的空闲缓冲区之后,共享缓冲区的状态如D所示。这时候free_offset_被设置为0,表示要从共享缓冲区的起始位置开始分配子缓冲区。
以上就是RingBuffer类的成员函数Alloc的实现逻辑。还有两点需要注意:
1. 请求分配的子缓冲区的大小至少为1个字节,并且需要对齐到前面分析TransferBuffer类的成员函数Initialize时提到的参数alignment的值。
2. 每一个分配出去的子缓冲区都使用一个Block对象描述,并且保存在RingBuffer类的成员变量blocks_描述的一个std::deque中。
从上面的分析我们就可以知道,通过RingBuffer类分配的子缓冲区的主要状态变迁过程为:FREE=>IN_USE=>FREE_PENDING_TOKEN=>FREE。
接下来,我们继续分析RingBuffer类的成员函数FreeOldestBlock的实现,以便了解它是如何回收一个分配出去的子缓冲区的,如下所示:
void RingBuffer::FreeOldestBlock() {
DCHECK(!blocks_.empty()) << "no free blocks";
Block& block = blocks_.front();
DCHECK(block.state != IN_USE)
<< "attempt to allocate more than maximum memory";
if (block.state == FREE_PENDING_TOKEN) {
helper_->WaitForToken(block.token);
}
in_use_offset_ += block.size;
if (in_use_offset_ == size_) {
in_use_offset_ = 0;
}
// If they match then the entire buffer is free.
if (in_use_offset_ == free_offset_) {
in_use_offset_ = 0;
free_offset_ = 0;
}
blocks_.pop_front();
}这个函数定义在文件external/chromium_org/gpu/command_buffer/client/ring_buffer.cc中。
前面提到,所有已经分配出去的子缓冲区保存在RingBuffer类的成员变量blocks_描述的一个std::deque中。其中,最早分配出去的子缓冲区保存这个std::deque的头部。在调用RingBuffer类的成员函数FreeOldestBlock的时候,必须要保证头部的子缓冲区不是处于IN_USE状态的。如果不是处于IN_USE状态,那么根据前面的分析,就是处于PADDING或者FREE_PENDING_TOKEN状态。处于PADDING状态的子缓冲区没有实际使用,因此可以直接回收。但是处于FREE_PENDING_TOKEN状态的子缓冲区,正在被GPU命令缓冲区引用,因此需要进行等待。等待结束后,就重新设置共享缓冲区的状态,即相应地调整in_useoffset、free_offset_的值,以及将位于头部的子缓冲区从成员变量blocks_描述的一个std::deque移除。
等待GPU命令缓冲区使用完毕一个子缓冲区是通过调用RingBuffer类的成员变量helper_描述的一个GLES2CmdHelper对象的成员函数WaitForToken实现的。GLES2CmdHelper类的成员函数WaitForToken是从父类CommandBufferHelper继承下来的,因此接下来我们分析CommandBufferHelper类的成员函数WaitForToken的实现,如下所示:
void CommandBufferHelper::WaitForToken(int32 token) {
......
if (token > token_) return; // we wrapped
if (last_token_read() >= token)
return;
Flush();
command_buffer_->WaitForTokenInRange(token, token_);
}这个函数定义在文件external/chromium_org/gpu/command_buffer/client/cmd_buffer_helper.cc中。
后面我们会看到,参数token描述的Token值是通过CommandBufferHelper类的成员函数InsertToken分配出来的。CommandBufferHelper类的成员函数InsertToken每次被调用时,都会将成员变量token_的值加1,然后将得到的结果返回给调用者。CommandBufferHelper类的成员变量token_是一个int32值,它不能无限增加。当增加到最大值0x7FFFFFFF时,就需要重置为0,然后开始新一轮的递增。当CommandBufferHelper类的成员变量token_被重置为0的时候,CommandBufferHelper类的成员函数InsertToken会请求GPU进程处理GPU命令缓冲区的所有新写入的命令,以便保证前面写入的所有gpu::cmd::SetToken命令都已经处理完毕。这样,当参数token的值大于CommandBufferHelper类的成员变量token_的时候,就意味着CommandBufferHelper类的成员函数WaitForToken不需要等待,因为这时候可以确保参数token关联的子缓冲区已经不再被GPU命令缓冲区引用了。
当参数token的值小于等于CommandBufferHelper类的成员变量token_的时候,CommandBufferHelper类的成员函数WaitForToken调用成员函数last_token_read获得GPU进程为当前OpenGL上下文记录的Token值。如果这个Token值大于等于参数token的值,那么就说明CommandBufferHelper类的成员函数WaitForToken不需要等待,因为条件已经满足。否则的话,接下来就会调用另外一个成员函数Flush请求GPU进程执行GPU命令缓冲区的命令。关于CommandBufferHelper类的成员函数Flush的实现,可以参考前面Chromium硬件加速渲染的OpenGL命令执行过程分析一文。
请求了GPU进程执行GPU命令缓冲区的命令之后,CommandBufferHelper类的成员函数WaitForToken调用成员变量command_buffer_描述的一个CommandBufferProxyImpl对象的成员函数WaitForTokenInRange等待GPU进程处理GPU命令缓冲区的命令,直到处理到一个Token值设置为token的gpu::cmd::SetToken命令。
CommandBufferProxyImpl类的成员函数WaitForTokenInRange的实现如下所示:
void CommandBufferProxyImpl::WaitForTokenInRange(int32 start, int32 end) {
......
TryUpdateState();
if (!InRange(start, end, last_state_.token) &&
last_state_.error == gpu::error::kNoError) {
gpu::CommandBuffer::State state;
if (Send(new GpuCommandBufferMsg_WaitForTokenInRange(
route_id_, start, end, &state)))
OnUpdateState(state);
}
......
}这个函数定义在文件external/chromium_org/content/common/gpu/client/command_buffer_proxy_impl.cc中。
CommandBufferProxyImpl类的成员函数WaitForTokenInRange首先调用另外一个成员函数TryUpdateState获得GPU进程的状态。获得的状态信息记录在CommandBufferProxyImpl类的成员变量last_state_描述的一个State对象。这个State对象的成员变量token记录了GPU进程为当前OpenGL上下文记录的Token值。如果这个Token值处于参数start和end描述的范围中,那么CommandBufferProxyImpl类的成员函数WaitForTokenInRange就不用等待了。否则的话,CommandBufferProxyImpl类的成员函数WaitForTokenInRange就会向GPU进程发送一个类型为GpuCommandBufferMsg_WaitForTokenInRange的同步IPC消息,等待GPU进程为当前OpenGL上下文记录的Token值处于参数start和end描述的范围中。
类型为GpuCommandBufferMsg_WaitForTokenInRange的IPC消息是由与当前正处理的CommandBufferProxyImpl对象对应的一个运行在GPU进程中的GpuCommandBufferStub对象的成员函数OnMessageReceived接收的,如下所示:
bool GpuCommandBufferStub::OnMessageReceived(const IPC::Message& message) {
......
bool handled = true;
IPC_BEGIN_MESSAGE_MAP(GpuCommandBufferStub, message)
......
IPC_MESSAGE_HANDLER_DELAY_REPLY(GpuCommandBufferMsg_WaitForTokenInRange,
OnWaitForTokenInRange);
......
IPC_MESSAGE_UNHANDLED(handled = false)
IPC_END_MESSAGE_MAP()
CheckCompleteWaits();
......
return handled;
} 这个函数定义在文件external/chromium_org/content/common/gpu/gpu_command_buffer_stub.cc中。
从这里可以看到,GpuCommandBufferStub类的成员函数OnMessageReceived将类型为GpuCommandBufferMsg_WaitForTokenInRange的IPC消息分发给成员函数OnWaitForTokenInRange处理。
GpuCommandBufferStub类的成员函数OnWaitForTokenInRange的实现如下所示:
void GpuCommandBufferStub::OnWaitForTokenInRange(int32 start,
int32 end,
IPC::Message* reply_message) {
......
wait_for_token_ =
make_scoped_ptr(new WaitForCommandState(start, end, reply_message));
CheckCompleteWaits();
}这个函数定义在文件external/chromium_org/content/common/gpu/gpu_command_buffer_stub.cc中。
GpuCommandBufferStub类的成员函数OnWaitForTokenInRange首先将参数start、end和reply_message封装在一个WaitForCommandState对象中,并且将该WaitForCommandState对象保存在成员变量wait_for_token_中,接着调用另外一个成员函数CheckCompleteWaits检查GPU进程是否已经处理了GPU命令缓冲区中的一个Token值介于start和end之间的gpu::cmd::SetToken命令。
GpuCommandBufferStub类的成员函数CheckCompleteWaits的实现如下所示:
void GpuCommandBufferStub::CheckCompleteWaits() {
if (wait_for_token_ || wait_for_get_offset_) {
gpu::CommandBuffer::State state = command_buffer_->GetLastState();
if (wait_for_token_ &&
(gpu::CommandBuffer::InRange(
wait_for_token_->start, wait_for_token_->end, state.token) ||
state.error != gpu::error::kNoError)) {
ReportState();
GpuCommandBufferMsg_WaitForTokenInRange::WriteReplyParams(
wait_for_token_->reply.get(), state);
Send(wait_for_token_->reply.release());
wait_for_token_.reset();
}
......
}
}这个函数定义在文件external/chromium_org/content/common/gpu/gpu_command_buffer_stub.cc中。
在前面Chromium硬件加速渲染的OpenGL命令执行过程分析一文中,我们分析过GpuCommandBufferStub类的成员函数CheckCompleteWaits是如何处理成员变量wait_for_get_offset_不等于NULL的情况的。当GpuCommandBufferStub类的成员变量wait_for_get_offset_不等于NULL的时候,它指向的也是一个WaitForCommandState对象,表示GPU进程的一个Client端正在等待GPU进程处理新提交的GPU命令,以便在GPU命令缓冲区中腾出更多的空闲空间来。
GpuCommandBufferStub类的成员函数CheckCompleteWaits处理成员变量wait_for_token_不等于NULL的情况也是类似的,它首先调用成员变量command_buffer_指向的一个CommandBufferService对象的成员函数GetLastState获得GPU命令缓冲区的处理状态信息。获得的状态信息封装在一个State对象中,这个State对象的成员变量token记录的就是最后一个处理的gpu::cmd::SetToken命令设置的Token值。如果这个Token值介于成员变量wait_for_token_描述的WaitForCommandState对象指定的范围,那么就可以向正在等待的Client端发送一个IPC消息,作为该Client端之前发送过来的类型为GpuCommandBufferMsg_WaitForTokenInRange的IPC消息的回复。Client端收到这个回复消息之后,就可以结束等待了。
以上我们分析的就是通过TransferBuffer类的成员函数AllocUpTo和Alloc从一个共享缓冲区中分配子缓冲区的过程,接下来我们继续分析通过TransferBuffer类的成员函数FreePendingToken释放子缓冲区的过程,它的实现如下所示:
void TransferBuffer::FreePendingToken(void* p, unsigned int token) {
ring_buffer_->FreePendingToken(p, token);
if (bytes_since_last_flush_ >= size_to_flush_ && size_to_flush_ > 0) {
helper_->Flush();
bytes_since_last_flush_ = 0;
}
}这个函数定义在文件external/chromium_org/gpu/command_buffer/client/transfer_buffer.cc中。
TransferBuffer类的成员函数FreePendingToken首先调用成员变量ring_buffer_指向的一个RingBuffer对象的成员函数FreePendingToken释放参数p描述的子缓冲区,并且给该子缓冲区关联一个Token值。
TransferBuffer类的成员函数FreePendingToken接下来判断从上次请求GPU进程处理GPU命令缓冲区的命令以来,又分配出去的子缓冲区的字节数bytes_since_last_flush_是否已经超出预先设定的阀值size_toflush。如果超出的话,就再次调用成员变量helper_指向的一个GLES2CmdHelper对象的成员函数Flush请求GPU进程处理GPU命令缓冲区的新命令,并且将成员变量bytes_since_last_flush_的值重置为0。
接下来,我们继续分析RingBuffer类的成员函数FreePendingToken的实现,以便可以了解子缓冲区释放的过程,如下所示:
void RingBuffer::FreePendingToken(void* pointer,
unsigned int token) {
Offset offset = GetOffset(pointer);
offset -= base_offset_;
......
for (Container::reverse_iterator it = blocks_.rbegin();
it != blocks_.rend();
++it) {
Block& block = *it;
if (block.offset == offset) {
......
block.token = token;
block.state = FREE_PENDING_TOKEN;
return;
}
}
......
}这个函数定义在文件external/chromium_org/gpu/command_buffer/client/ring_buffer.cc中。
RingBuffer类的成员函数FreePendingToken首先找到参数pointer描述的子缓冲区在成员变量base_offset_描述的共享缓冲区中的偏移位置,然后根据这个偏移位置从成员变量blocks_描述的一个std::deque中找到一个对应的Block对象,最后将参数token描述的Token值设置给前面找到的Block对象,并且将该Block对象的状态设置为FREE_PENDING_TOKEN。这相当于是将一个子缓冲区从状态IN_USE修改为FREE_PENDING_TOKEN,这也意味着该子缓冲区还没有真正释放掉,因为这时候它可能还被GPU命令缓冲区引用。
以上我们分析的就是通过TransferBuffer类的成员函数FreePendingToken释放一个从共享缓冲区中分配出来的子缓冲区的过程。为了方便GPU进程的Client端释放一个子缓冲区时,自动往GPU命令缓冲区插入一个gpu::cmd::SetToken命令,以及关联一个Token值,Chromium提供了一个工具类ScopedTransferBufferPtr,用来分配和释放子缓冲区。
当我们创建一个ScopedTransferBufferPtr对象时,会通过它的构造函数自动从一个共享缓冲区中分配一个子缓冲区,如下所示:
class GPU_EXPORT ScopedTransferBufferPtr {
public:
ScopedTransferBufferPtr(
unsigned int size,
CommandBufferHelper* helper,
TransferBufferInterface* transfer_buffer)
: buffer_(NULL),
size_(0),
helper_(helper),
transfer_buffer_(transfer_buffer) {
Reset(size);
}
......
};这个函数定义在文件external/chromium_org/gpu/command_buffer/client/transfer_buffer.h中。
参数transfer_buffer指向的是一个TransferBuffer对象,该TransferBuffer对象内部创建有一块共享缓冲区,参数size表示要从上述共享缓冲区中分配的子缓冲区的大小,另外一个参数helper指向的是一个GLES2CmdHelper对象,用来往GPU命令缓冲区插入gpu::cmd::SetToken命令。
ScopedTransferBufferPtr类的构造函数调用另外一个成员函数Reset从参数transfer_buffer指向的TransferBuffer对象中分配一个子缓冲区,它的实现如下所示:
void ScopedTransferBufferPtr::Reset(unsigned int new_size) {
Release();
buffer_ = transfer_buffer_->AllocUpTo(new_size, &size_);
}这个函数定义在文件external/chromium_org/gpu/command_buffer/client/transfer_buffer.cc中。
ScopedTransferBufferPtr类的成员函数Reset调用成员变量transfer_buffer_描述的一个TransferBuffer对象的成员函数AllocUpTo分配一块大小为new_size的子缓冲区,分配出来的子缓冲区用一个Buffer对象描述,该Buffer对象保存在成员变量buffer_中。
注意,当前正在处理的ScopedTransferBufferPtr有可能之前已经分配过子缓冲区,这时候在分配新的子缓冲区之前,需要调用另外一个成员函数Release释放旧的子缓冲区。后面我们再分析ScopedTransferBufferPtr类的成员函数Release的实现。
当一个ScopedTransferBufferPtr对象超出其生命周期范围时,会通过它的析构函数自动释放之前分配的子缓冲区,如下所示:
class GPU_EXPORT ScopedTransferBufferPtr {
public:
......
~ScopedTransferBufferPtr() {
Release();
}
......
};这个函数定义在文件external/chromium_org/gpu/command_buffer/client/transfer_buffer.h中。
ScopedTransferBufferPtr类的析构函数调用另外一个成员函数Release释放之前通过构造函数分配的子缓冲区,如下所示:
void ScopedTransferBufferPtr::Release() {
if (buffer_) {
transfer_buffer_->FreePendingToken(buffer_, helper_->InsertToken());
buffer_ = NULL;
size_ = 0;
}
}这个函数定义在文件external/chromium_org/gpu/command_buffer/client/transfer_buffer.cc中。
当成员变量buffer_不等于NULL的时候,就说明当前正在处理的ScopedTransferBufferPtr对象之前从成员变量transfer_buffer_描述的一个TransferBuffer对象中分配过子缓冲区,因此这时候就需要调用该TransferBuffer对象的成员函数FreePendingToken释放该子缓冲区。在释放之前,还会调用成员变量helper_指向的一个GLES2CmdHelper对象的成员函数InsertToken往GPU命令缓冲区写入一个gpu::cmd::SetToken命令。等到该gpu::cmd::SetToken命令被GPU进程处理后,ScopedTransferBufferPtr类的成员变量buffer_描述的子缓冲区才可以真正释放。
接下来我们继续分析GLES2CmdHelper类的成员函数InsertToken的实现,以便可以了解gpu::cmd::SetToken命令的处理过程。
GLES2CmdHelper类的成员函数InsertToken是从父类CommandBufferHelper继承下来的,因此接下来我们分析CommandBufferHelper类的成员函数InsertToken的实现,如下所示:
int32 CommandBufferHelper::InsertToken() {
......
token_ = (token_ + 1) & 0x7FFFFFFF;
cmd::SetToken* cmd = GetCmdSpace<cmd::SetToken>();
if (cmd) {
cmd->Init(token_);
if (token_ == 0) {
TRACE_EVENT0("gpu", "CommandBufferHelper::InsertToken(wrapped)");
// we wrapped
Finish();
DCHECK_EQ(token_, las