Raptor Lake S,再进一步 Intel i9 13900K 全面评测
关于Alder lake系列产品的测评前面我们也已经做过,具体链接如下:
1. https://www.bilibili.com/read/cv13858032?spm\_id\_from=333.999.0.0
2. https://weibo.com/ttarticle/p/show?id=2309404713343930990967#\_0
尽管 Intel 通过 Golden Cove 与 Gracemont 两种微架构的混合产品 12900K 提供了几乎足够与 AMD Ryzen R9 5950X 匹敌多线程性能以及略胜一筹的单线程性能,但是较高的 P core 频率与相对较少 E core 数量使得该产品在相对高压力的性能测试下能效相较于对方略逊一筹。
北京时间 2022.9.28 日,时隔十一个月之后,Intel 发布了他们全新的一代的桌面端产品Raptor lake-S--猛禽湖,在制程没有大的换代的情形下,通过将 Contact Gate Pitch(CPP)进一步从 54 nm 放宽至 60 nm 的方式进一步获得了终极版 10nm 制程,最终提供的相较于 Alder lake 系列产品超过 0.5 Ghz 的 Pcore 频率。与此同时,Intel 还在 i5 i7 i9 产品中翻倍了 Ecore,并提供更多的 L2/L3 缓存,以提高应用与游戏性能,最终使性能达到了一个全新的高度。
当然,在 Raptor lake-S 中,Intel 也修复了一些前代产品中的一些问题。
在产品的发布前,OneRaichu 跟 ECSM_Official 共同合作,我们对 Raptor lake-S 的旗舰产品,Intel Core i9 13900K 进行了相应的测评。
测试平台:
CPU1: Intel Core i9 13900K
CPU2: Intel Core i9 12900KF
DRAM: DDR5-6000 CL30-38-38-76,DDR4-3600 CL17-19-19-39,Trefi=262143,其他小参=Auto。
主板:Z690 Taichi RAZER Editon and Z790 ****
BIOS 版本:12.01 与 ****
GPU:AMD Radeon RX 6900 XTXH OC 2700MHz
散热:NZXT Kraken X73
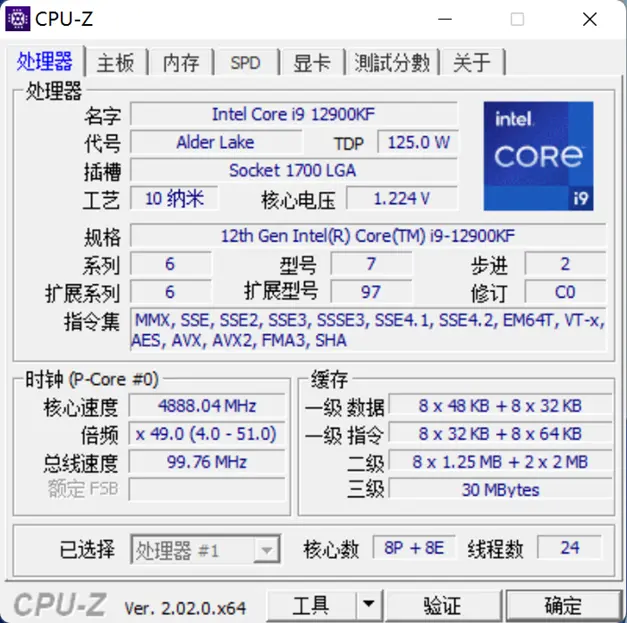
CPU-Z 图:
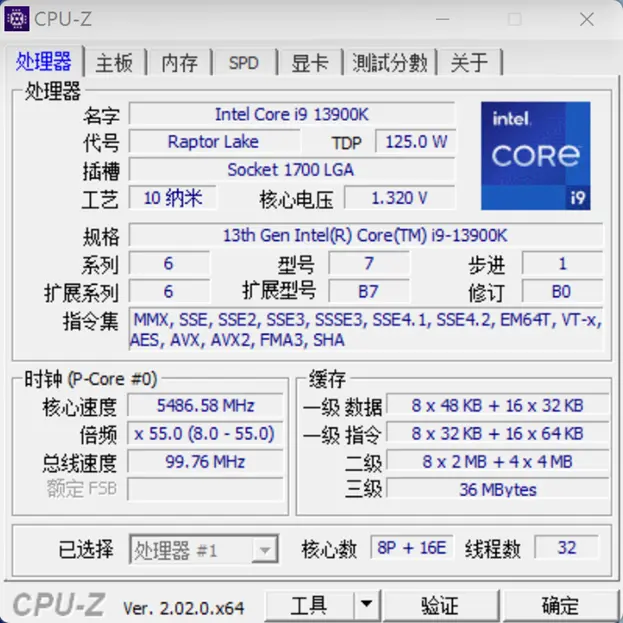
其中 Intel Core i9 13900K 的核心睿频为
P:1-2C 58x,3-8C 55x
E:1-16C 43x
内存默认支持到 JEDEC-5600MHz(即默认内存不超频下能支持的最高频率内存,仅限于 1DPC+2CH 或 2DPC+1CH 时)
Intel Core i9 12900K 的 核心睿频为
P:1C 52x 2C 51x 8C 49x
E:1-4E 39x 5-8E 37x
内存默认支持到 JEDEC-4800MHz(即默认内存不超频下能支持的最高频率内存,仅限于 1DPC+2CH 或 2DPC+1CH 时)
首先是理论测试部分,这一部分由 OneRaichu 进行
一、AIDA64 快餐带宽测试

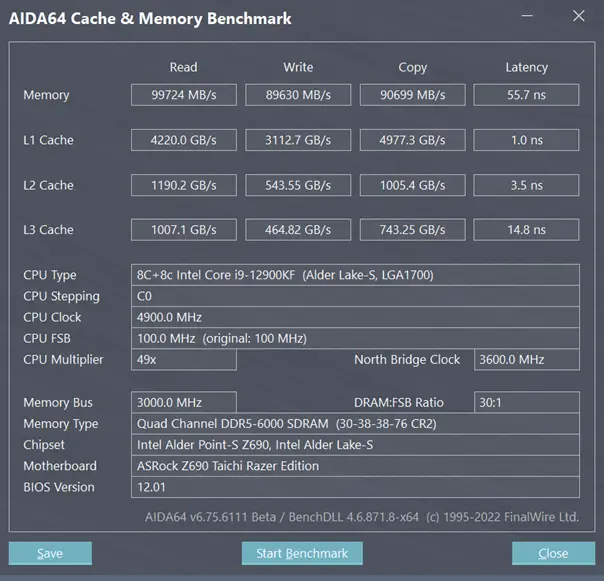
我们首先进行的是 AIDA64 的缓存/内存测试,由于当前的 AIDA64 并不能识别 13900K 的具体型号,许多细节也并不完全正确,这里的对比测试仅供参考。详细的 CPU 带宽/延迟测试,我们会在后面的具体测试中一一进行。
二、CPU 核间延迟测试。
紧接着我们进行了核心间通讯延迟的具体测试,使用的是求秒的延迟测试工具,相较于 microbench 的工具来说准确度更高,延迟均匀性更好,我们的精确度选择了 level 10(最高级)。


相较于 Intel Core i9 12900K 来说,由于 Ring bus 结构与设计的变动,当 Ecore 有负载的时候,Ringbug Frequency 不会再由 4700 MHz 掉至 3600 MHz 这样的大幅度变化,其变化主要由 5000 MHz 变化至 4600 MHz,此时 Ringbus 的延迟将不再成为核心访问延迟的负累,再加上 Ring bus 拓扑结构的可能变动致使 Intel Core i9 13900K 的核心延迟产生了比较有趣的变化。
即 P 与 E 之间的通讯不再存在一个明显的访问惩罚,几乎所有核心间的通讯速度都维持到了一致的水平,大约在 30-33 ns 之间,除了同 Cluster 内的小核心仍旧因为没有总线探听器的缘故具有一定的访问延迟惩罚,而同 Cluster 内的 E 核心延迟也有少许的改进。
三、理论延迟与带宽测试
在核心通讯测试之后,我们进行了两个产品的内缓存延迟测试(使用 Clamchowder 的测试工具)。
首先是默认频率下的情况:
P:

E:
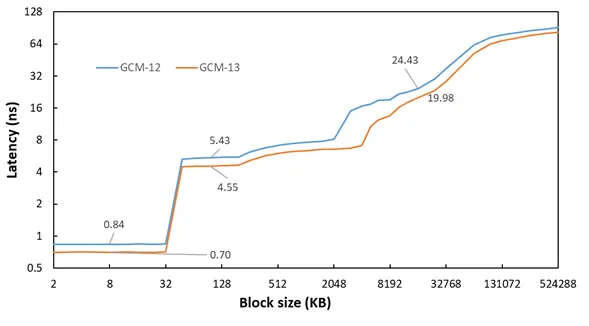
由于实际的频率更高,因此即便是缓存明显增大的情况下,不论是 P/E 核心在全范围内的延迟仍然均低于上一代。
在这里,我们还进行了两代产品同频下的内缓存延迟对比,使用 Cycle(周期)表示延迟情况。
P:

可以看见 13 代 Core 的 Raptor Cove 核心为了增加缓存的容量,在 L2 跟 L3 的同频延迟上实际上对比 12 代的 Golden Cove 有些许的变化,其中 L2 大约多了 1 Cycle,但容量增加了 60%,L3 则是在前半段大约 16M 内平均多 3 cycle,16M 后低 2-3cycle。
E:

如果说 Pcore 的延迟在缓存容量增加时略微做了一些妥协,在不同的部分有增有减,那么 13 代的 Ecore 的延迟几乎在整个 Cache 范围内都优于 12 代 Ecore。其中 L2 在容量翻倍的情况下维持住了延迟不变,L3 延迟甚至在部分场景下比上代低了甚至超过 10 cycle。这种变动对 Ecore 来说无疑会带来相当幅度的同频性能增加。
完成了延迟部分的测试之后,我们还针对缓存/内存的带宽进行了相应的测试。
首先是单线程读取/写入部分。

这里我们直接对单线程带宽进行了频率归一化处理,可以看见实际上同频的 12 代 Pcore 的 L1-Read 带宽相较于 13 代 P-core 的 L1-Read 带宽略高一些,L2 的带宽则基本相同,L3 的带宽则略高一些,其中 L1 R 的带宽下降不排除可能是当前 bios 存在的问题所致。
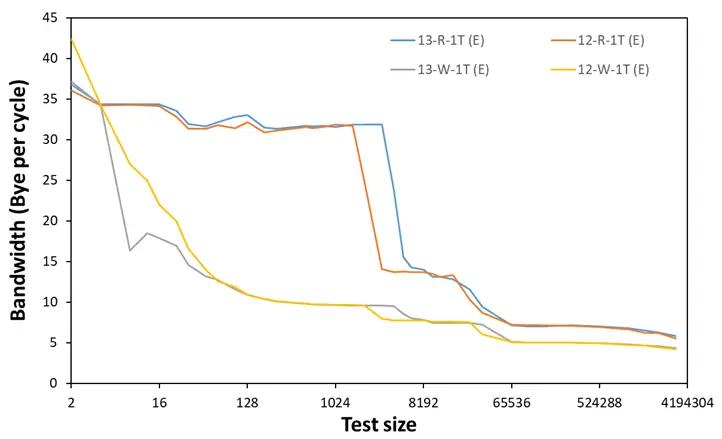
类似的,我们也测试了 Ecore 的 1T 读写带宽,可以看见除了因为缓存容量增加扩大了一些 L2/L3 cover 范围外,没有太多明显的变动。
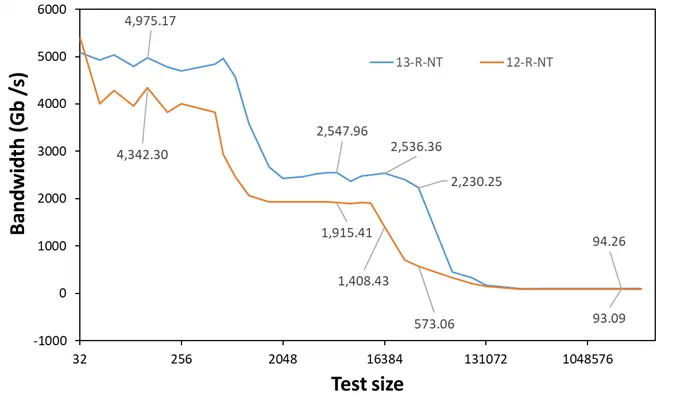
我们还测试了多线程的情况,相较于单线程来说,多线程的情况发生了一点变化。L1/L2 的带宽增加主要由 13 代增加的 E 核心提供,然而 L3 的带宽变化则有所不同,其中 P core 的 L3-Read 带宽在这里也有了一些变化,其由 12 代的 3MB/Core 10 way 64bytes line 64threads 变动为 13 代的 3MB/Core 12way 64bytes line 128threads。
这就导致到了 L3 cover 的范围,13900K P+E 的总带宽在 L3 部分范围甚至翻倍还多,在绝大多数 L3 cover 范围中都是,AIDA64 测试的带宽尽管是纯 Pcore 的范围,但也有类似的体现。
为此,我们还单独测试了纯 Pcore 的情况,结果如图所示:
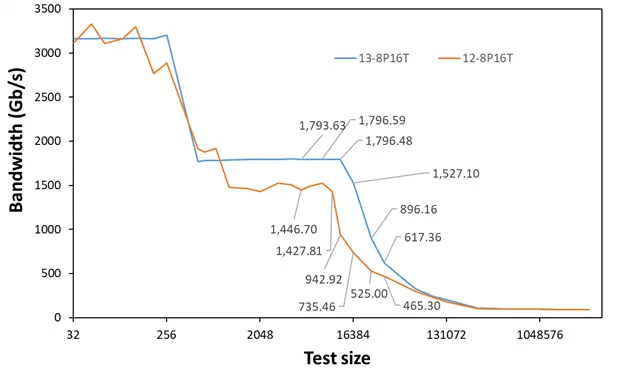
可以看见在整个 L3 覆盖范围内到出 L3 为止,13 代的纯 Pcore L3 多线程读取带宽均为 12 代的 1.5 倍以上。
这种大幅度的 L3 带宽增加,可能会在多线程测试中带来较为明显的变化,尤其是依赖缓存吞吐的相关应用。
关于内存带宽,两者均受限于 DDR5-6000,因此均在 93-94 GB/s 的范围,其中 13 Gen 受益于更高的缓存吞吐速度,因而稍高一些。
四、指令带宽与理论吞吐:
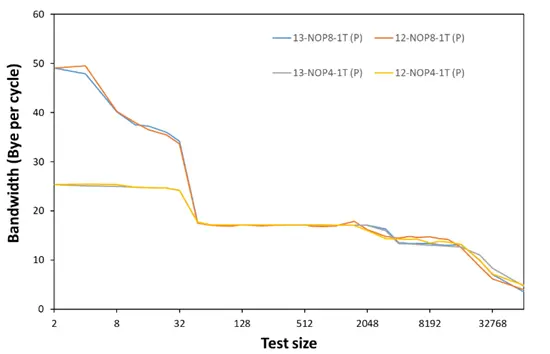
进一步的,我们进行了 NOP 指令的带宽测试,可以看见由于微架构没有明显的改变,在 NOP8/4 的指令测试中两代 P/E core 没有明显的区别,只有在缓存变化的位置有变动。

此外,我们还测试了理论吞吐的情况,可以看见在本测试的条件下(不同平台可能测试结果略微有些许不同),13 代 Pcore 有少数指标对比 12 代略有变化,已经标出,不排除是测试平台带来的误差。
注:测试时均开启小核心,故没有 AVX512 部分。

五:性能测试
完成了上述的理论测试后,我们进入到性能测试的环节,其中我们对 13900K 的测试分为两个挡位
Unlimited power test
此设置下功耗完全放开,无功耗限制。
253w PL2 test
此测试下沿用 13900K 默认的 255W PL2。(敬请期待 测评 part2)
5.1 首先进行的是熟悉的 CB 部分测试


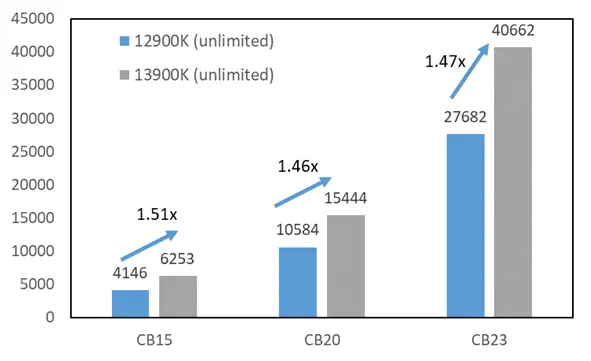
5.2 3DMark 部分
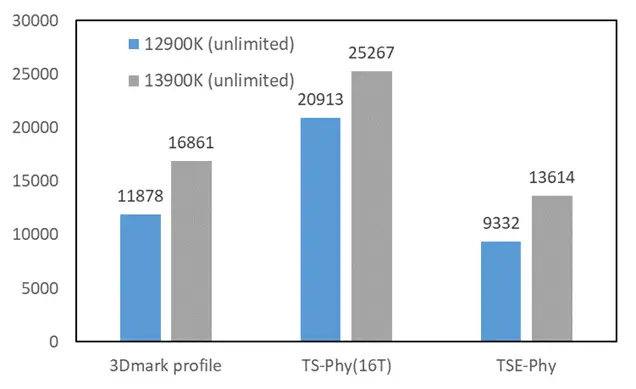
5.3 SuperPI 部分


提升幅度与比例
5.4 CPU-Z 部分
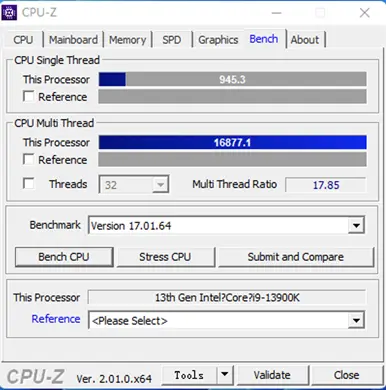
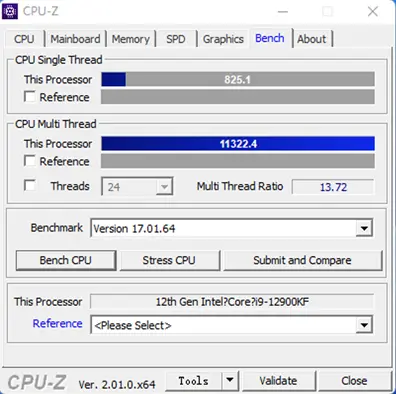
5.5 解压缩部分

5.6 AIDA64 理论测试部分
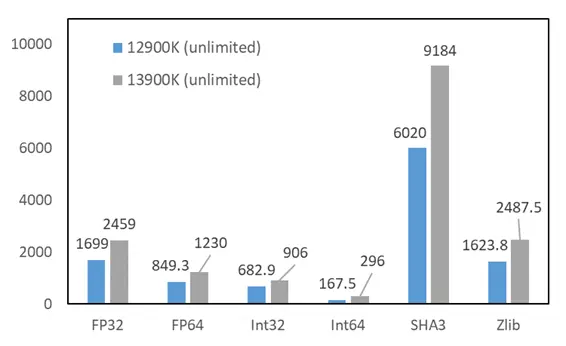
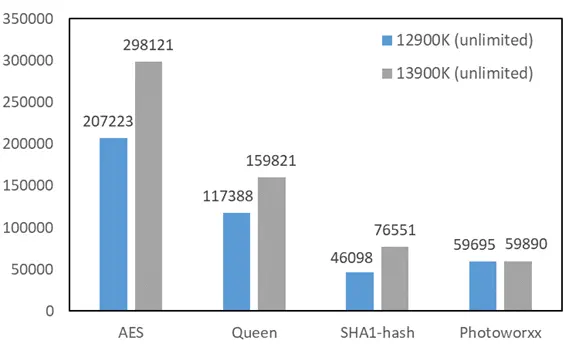
多线程汇总:
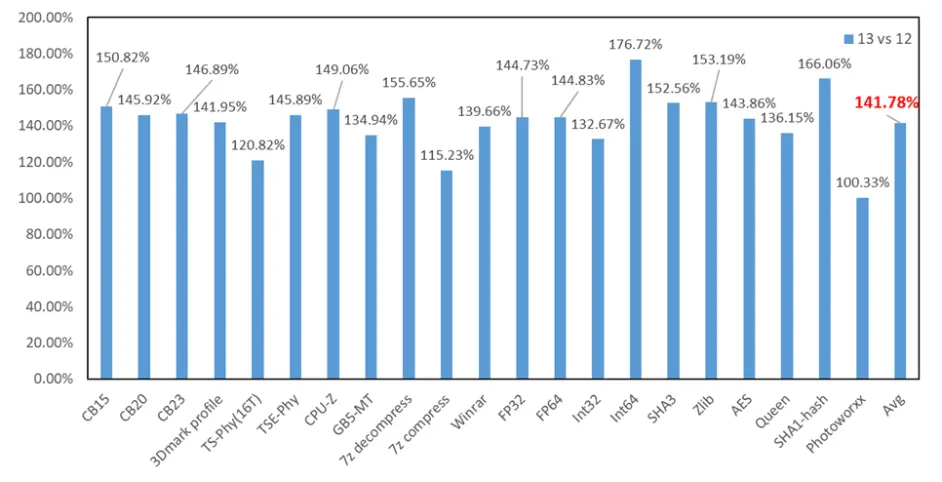
六:IPC 测试
在性能测试的基础上,我们分别使用了 SPEC CPU 2017 1.1.8 以及 Geekbench 5.4.4 进行了对应的 IPC 测试,同时测试了默认频率的情况以及 3.6Ghz 时的情况,仅供参考。
SPEC CPU 2017:
OS:WSL2-Ubuntu 20.04
编译器:GCC/Gfortran/G++ 10.3.0
测试参数:-O3,对应测试与 cfg 附于网盘之中,链接:https://pan.baidu.com/s/1G0yD\_FC3yXOJl3tkkyzjSg 提取码:pa37,欢迎各位取用测试。
P 核心部分:
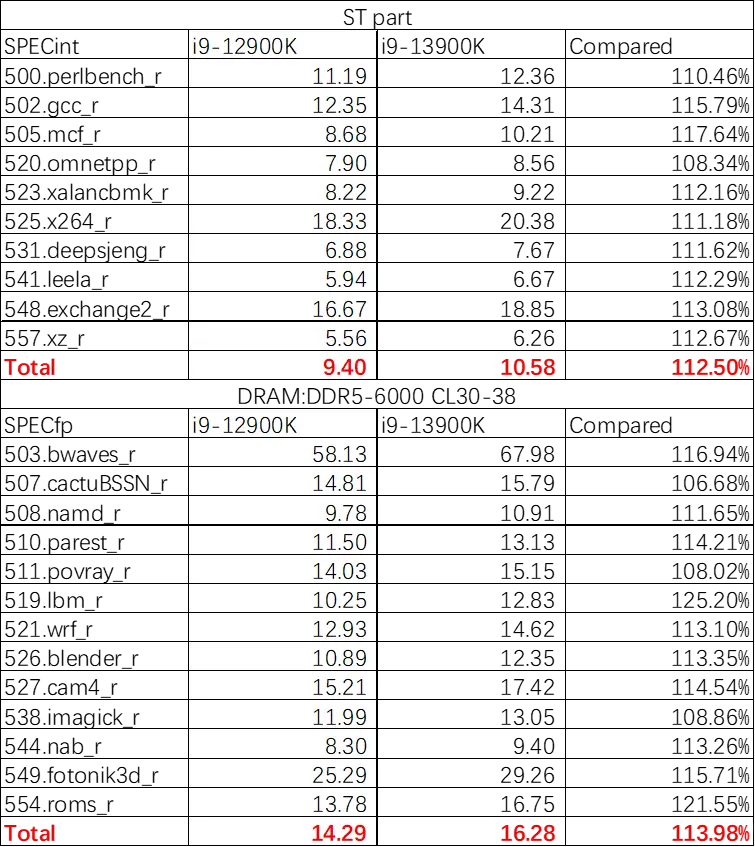
我们首先测试了默认频率下单线程性能,可以看见在默频情形下,提升大约在 12.5% 左右。

进一步的,我们进行了 3.6GHz 的同频测试,可以看见 RPC/GLC 两个核心的同频性能基本一致,而 RPC 由于具有更大的 L2 cache 致使其的访存延迟相对更低,再加上更加合理的睿频机制,最终导致其在频率更高,且均跑满的情形下的大部分项目性能损失更低(5.8GHz VS 5.2GHz)。值得注意的是 520/549 子项在这里出现了严重瓶颈,此项目与 L3-DRAM 覆盖范围的延迟性能直接相关。
我们还测试了 E 核心的 IPC:

由于内缓存部分的明显优化,以及核心访问延迟的进一步优化,Ecore 的 IPC 产生了明显的变化,平均 IPC 提升大约在 6% 左右。
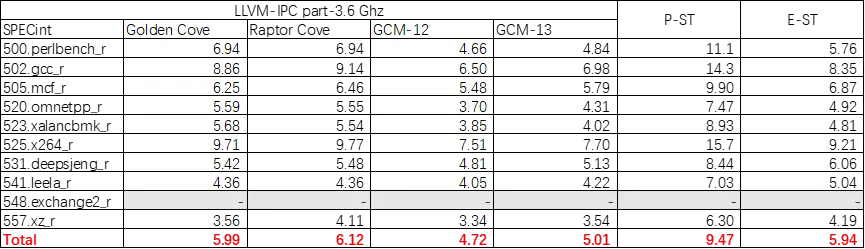
除 GCC 部分外,我们还使用 Clang 10+Gfortran 12 的组合测试了 SPECint2017,在下列的表格中我们去掉了 548.exchange2_r 项目的分数,仅用于比较 C/C++ 项目性能,以便用于与移动端手机 SOC 进行比较。
需要注意的是,本测评使用的内存非 JEDEC-规格,因为性能相较于使用 JEDEC 内存时有些许变化。
Geekbench 5.4.4:
P 核心部分:

我们首先测试了默认频率下单线程性能,可以看见在默频情形下,提升大约在 13% 左右。

进一步的,我们进行了 3.6GHz 的同频测试,与 SPEC2017 的结果一致,可以看见 RPC/GLC 两个核心的同频性能基本一致。RPC 由于具有更大的 L2 cache 致使其的访存延迟相对更低,再加上更加合理的睿频机制,最终导致其在频率更高,且均跑满的情形下的性能损失更低。
我们还测试了 E 核心的 IPC:

由于 Geekbench 的考察更偏向于 ALU 部分,对内缓存的考察相对较弱,这里的结果与 SPEC2017 中有了些许的偏差,在 GB5 中,Ecore 的 int 部分几乎没有变动,而 FP 部分则与 SPEC2017 的结果接近,大约有 6% 的提升。
七:游戏测试
由于 RPL 依旧兼容 DDR4,所以这里额外安排了 DDR4 3600 C17-19-19-39 Trefi 262143 的平台测试。
为了确保测试公平统一,所以均采用游戏内自带的 Demo 和帧数统计,并且每款游戏均运行五次 Demo,取平均值,如成绩出现与其他四次较大的差距,那么本次成绩无效,补测一次,若游戏本身帧数统计包含小数,则会保留相应位数的小数,否则一律四舍五入。





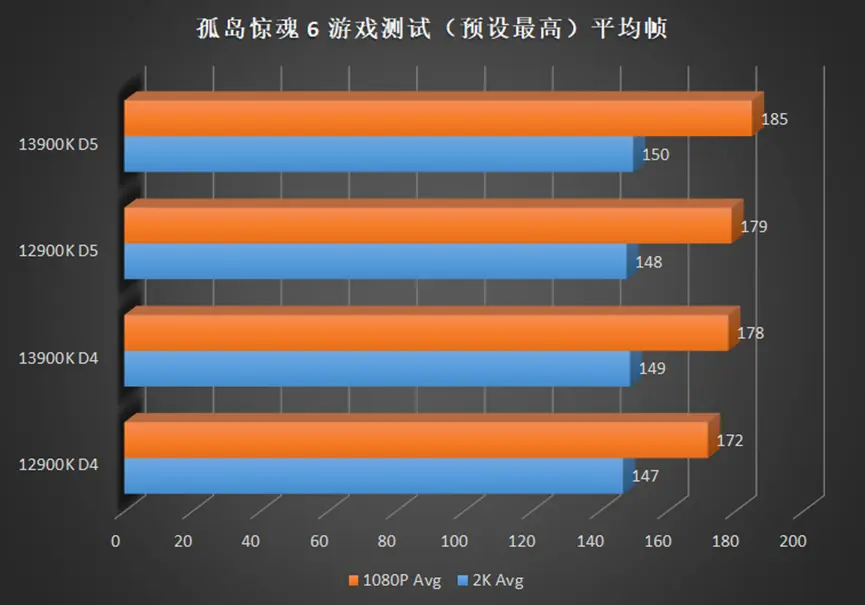
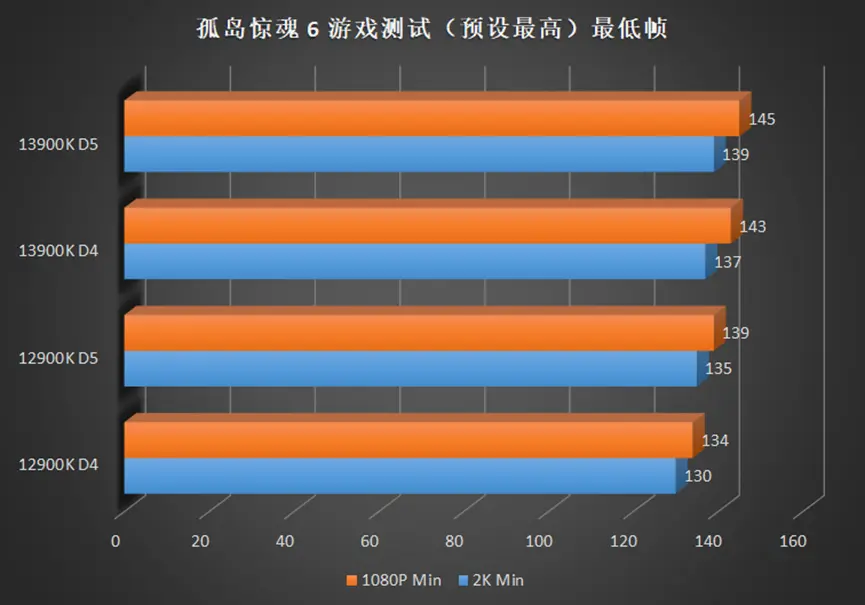
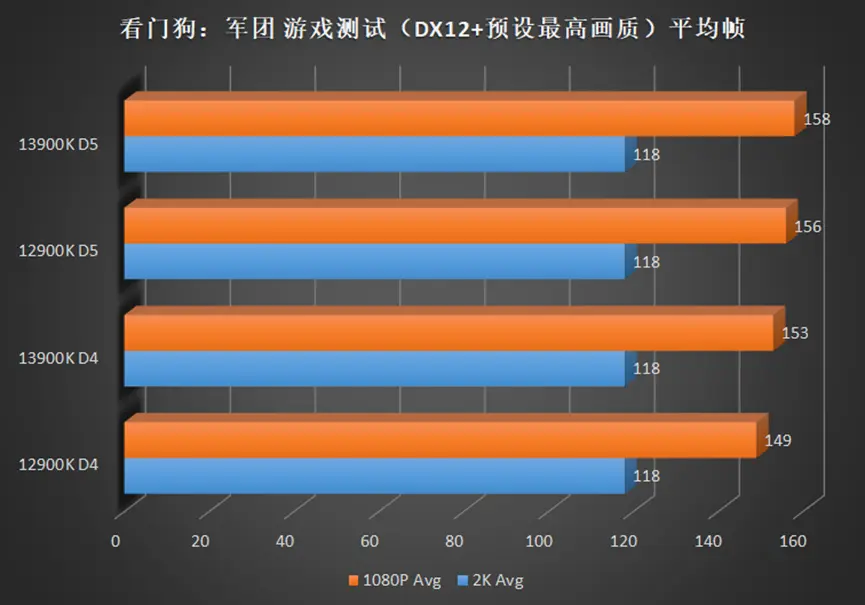
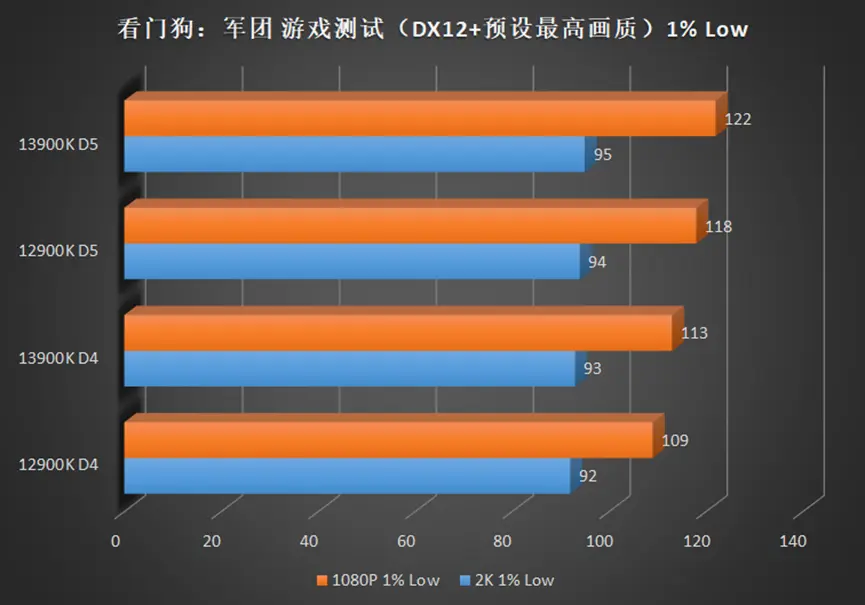


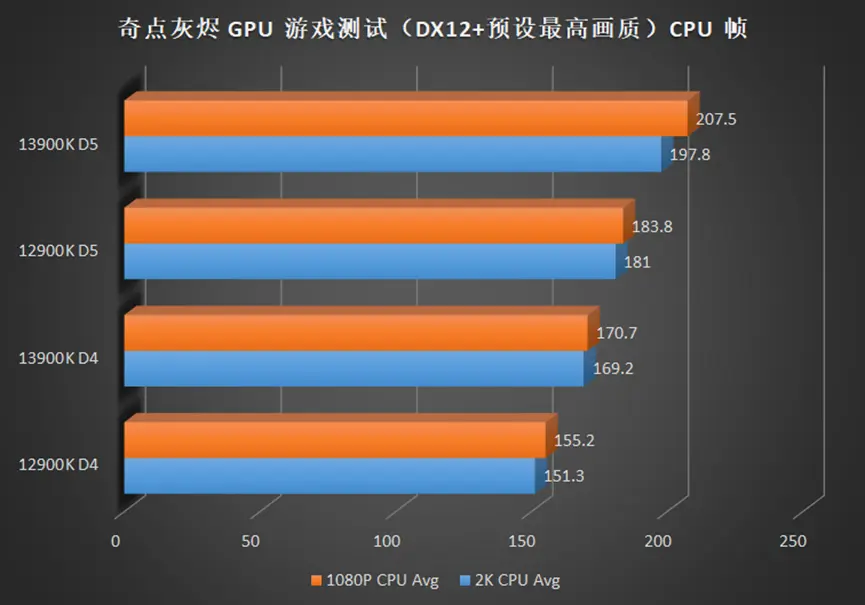


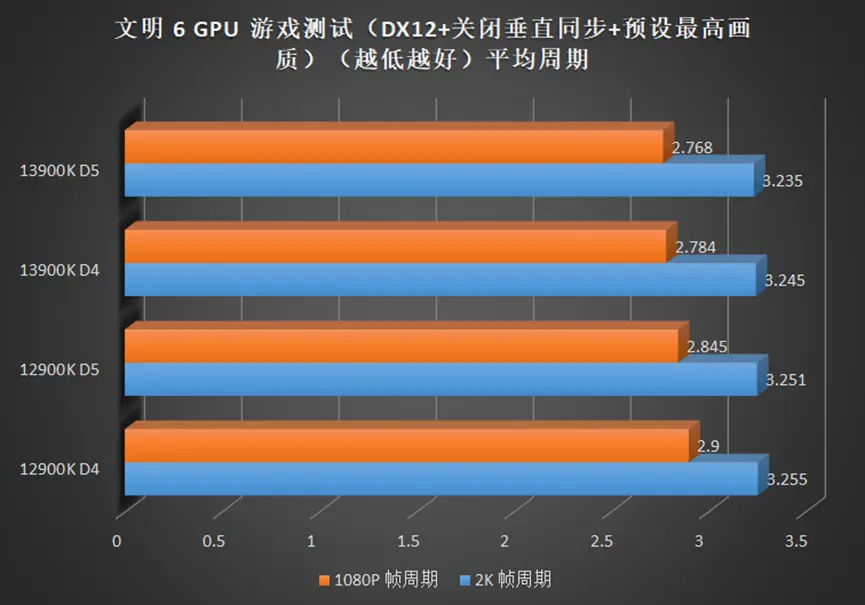
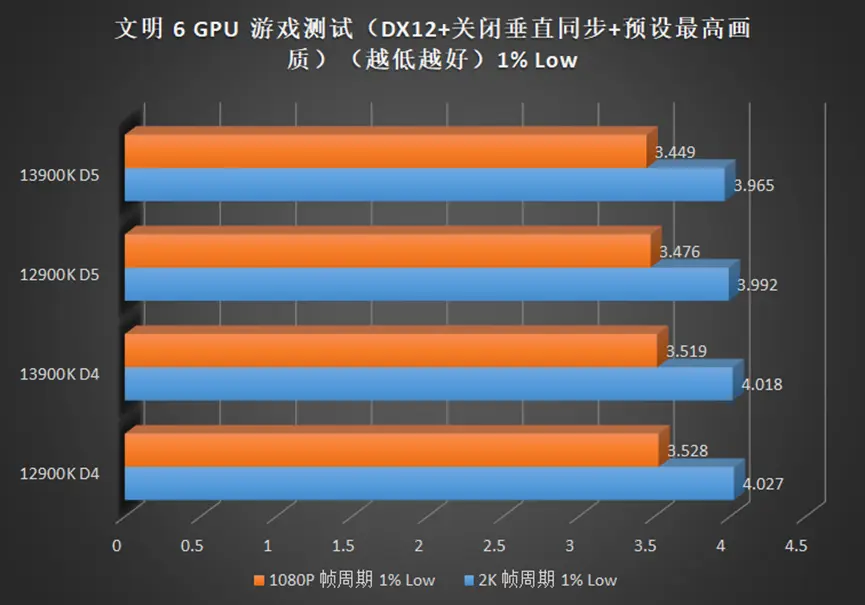

在侧重 CPU 较多的高帧游戏中,例如奇点灰烬,CSGO 等,13900K 相较于 12900K 的提升可以在 10%+,如果将显卡换成更高端的型号,那么这个差距将继续被放大。
2K 分辨率依旧难以被撼动,均帧除了 CSGO,提升都在个位数,但是 13900K 同样也带来了最低帧提升,也就是说,使用 13900K 的游戏体验会更流畅。
Intel 通过魔改 Ring 总线,带来 Ecore 访问延迟的降低,同时 RPL 的 Ring 频率和 Ecore 脱钩,不会再出现 ADL 上小核负载时 Ring 大幅度降速的问题。
不过 RPL 还是会降速,13900K 会从 Auto 5000MHz 降频至 4600MHz,但是相对于 12900K 的提升大很多,但这意味着你依旧可以通过关闭 Ecore 来提升游戏性能。
除了魔改 Ring 总线以外,Intel L2 增量,L3 增速都会给游戏带来一定的提升,尤其是在 DDR5 平台下,L3 的增速将会放大 DDR5 带来的优势。
八:能效测试:
我们首先进行了简单的功耗测试:
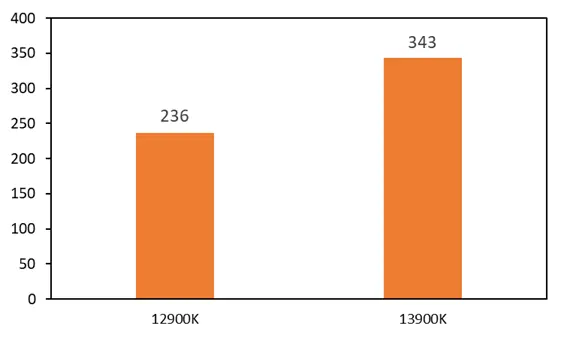
在 AIDA64 FPU 场景下,13900K DDR5 的功耗约为 253w,此时的各核心频率约为 *** 与 ***。
在 Z690 主板搭配八月份的 BIOS 中,解锁功耗墙之后的功耗约为 343w,此时的电压在 1.4V 附近,各核心频率约为 P 核心 5.5 GHz,E 核心 4.3 GHz。
随后,我们同时使用 Geekbench 5 多线程 int 与 Cinebench R23 的分数进行能效测试,用以模拟轻/重负载下的性能,不同功耗下的轻重负载性能(百分比)如图所示:
(图文省略.jpg)
问:数据呢?图呢?为什么我看不见 253w 的性能和能效/功耗曲线?
答:为了准确的测试相关功耗数据,我们使用了新到的 Z790 主板进行了相关测试,然而该主板仍处于 NDA 状态中,因此暂时无法展示相关数据,我们将在解禁后的第一时间内补上关于能效测试的部分。
以下是小剧场:
描:我搞了一张 Z790 板子,顺便还更新到了最新版 BIOS,能效有些变化,电耗子我们用那个测吧,肯定准!
雷:大描老师,测啊测啊!刚好我还没测完能效。
结果虽然什么都测了,但是这一部分的数据是在 Z790 上测试的,可因为板子有 NDA,跟大描老师商量之后决定暂时不放出来相关的数据。
剩下的部分,请期待我们的第二部分测评-能效与对决。
大描老师:Part2 不仅会加入能效部分的测试,同时会加入不知名 16C CPU 的对比,但是由于 NDA 的问题,这个时间点可能需要等到红厂新品正式发布之后。
九:结语
在 Alder lake 产品发布的一年之后,Intel 通过进一步放宽 CPP 的 10nm Enhanced Super Fin plus(Intel 7+)工艺,获得了频率更高,能效也来的更好的新一代产品 Raptor lake。通过增加频率和小核心的数量,在提升大约 12% 的单线程性能时,又一次大幅的提升多线程性能,用以与超威半导体今年发布的新品 Zen 4 进行竞争。
不论本世代最终鹿死谁手,谁又将成为本世代的单线程/多线程性能之王,我想这都应当都是近十年来半导体发展最好的时代。
因为这是竞争最激烈的时代,自然也是对消费者最有利的时代,有了激烈的竞争,才会有不断的进步,不论什么领域均不外如是。
其实我们很早就展开了联合测试,并且在月初就完成了数据统计和问题分析,也考虑到并猜测了 AMD 的 FCLK 带来的相关限制,所以原来的结果均在 6400 C34 下测出,但是我们实在是没想到 Zen4 的甜点仅有 6000MHz,所以我们掀掉了以往的测试结果,通宵将 6000 C30 重测出来,我感受到了 AMD 深深的背刺。
此时此刻,描和雷的眼圈又黑了一度。
最后,也感谢每一位读者对本评测的阅读,以上的所有数据均由 ECSM_Official & OneRaichu 提供,测试的结果可能有所不同,与不同的软硬件有关。
如有不对,劳烦指正,如有不足,敬请谅解。
美国芯片巨头英特尔与中方合作!将在深圳新建芯片创新中心
工信部要求开展 App 备案,微信小程序完成备案后才可上架

家乐福被裁员工曝未拿到补偿金,此前通知补偿金打6折一次性发和全款分12期之间二选一
全球勒索软件攻击创历史新高,美国是全球勒索软件攻击首要目标
美交管局对特斯拉部分车型展开调查,特斯拉部分车型被曝转向失灵
相关标签
相关文章
王慧文病休53天,旗下OneFlow团队重新创业
1年以前 | 1次阅读
智己CEO现场怒怼!不满LS6和小鹏G6当对手
1年以前 | 1次阅读
董明珠回应落榜世界500强:总比爆雷的世界500强好
1年以前 | 1次阅读
阿里云上线 AI 视频生成工具 Live Portait:可一键让照片开口说话
1年以前 | 78次阅读
妙鸭相机将并入神力视界,阿里大文娱CTO郑勇:不是“搬家”是“回家”
1年以前 | 85次阅读
特斯拉上海超级工厂约40秒下线一台车,零部件本土化率超95%
1年以前 | 69次阅读
宁德时代发布神行超充电池,可实现充电10分钟行驶800里
1年以前 | 71次阅读
中科院博士被骗到缅甸已一年!女友:他负债几万,家里条件一般,以为去当翻译
1年以前 | 85次阅读
小鹏汽车否认收购玛莎拉蒂传闻:系谣言
1年以前 | 63次阅读
联想二季度净利润猛降66%,股价应声跳水
1年以前 | 80次阅读
业内人士:视觉中国对不同侵权主体采用差异化策略,老客由销售沟通新客发律师函
1年以前 | 70次阅读
恒大集团在美国申请破产保护
1年以前 | 56次阅读
劳斯莱斯首款纯电轿跑将在北美亮相
1年以前 | 89次阅读
realme印度前CEO确认加盟荣耀,即将推出手机新品
1年以前 | 88次阅读
OpenAI正在测试内容审核系统,一天可以完成六个月的工作
1年以前 | 80次阅读
谷歌百人“复仇者联盟”出击,将发对标GPT-4的大模型,26位研发主管名单流出
1年以前 | 77次阅读
OpenAI收购数字产品公司Global Illumination,为创立以来首笔公开收购
1年以前 | 80次阅读
海口规定:电动汽车充电服务费不得超过0.65元每度
1年以前 | 80次阅读
波音任命柳青为波音中国总裁
1年以前 | 88次阅读
业内人士谈图片复杂代理链:图片代理商越多摄影师分成越少
1年以前 | 67次阅读