OpenAI宣布开源多语言语音识别系统Whisper

(来自:OpenAI Blog)
OpenAI 表示,Whisper 的不同之处,在于其接受了从网络收集的 68 万小时的多语言和“多任务”训练数据,从而提升了该方案对独特口音、背景噪声和技术术语的识别能力。
官方 GitHub 存储库上的概述称:
Whisper 模型的主要目标用户,是研究当前模型稳健性、泛化、能力、偏差和约束的 AI 研究人员。
与此同时,它也很适合作为面向开发者的自动语音识别解决方案尤其是英语语音识别。
感兴趣的朋友,可以从托管平台上下载 Whisper 系统的多个版本,其模型在大约 10 种语言上展现出了强大的 ASR 结果。
此外假如在某些任务上加以微调的话,它们还有望在语音活动检测、讲述者分类等应用场景下表现出额外的能力。
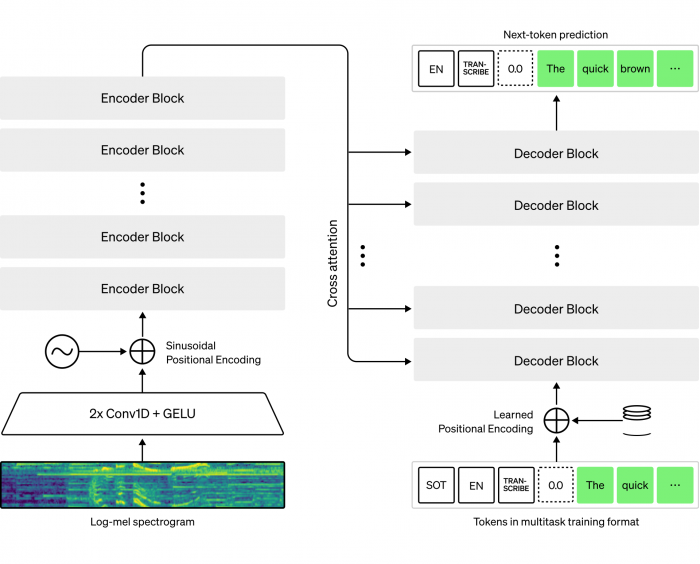
架构示意
遗憾的是,Whisper 尚未在相关领域得到强有力的评估、且模型也有其局限性 —— 有其在文本预测领域。
由于该系统接受了大量“嘈杂”的数据训练,OpenAI 决定提前给大家打一剂预防针,警告称 Whisper 可能在转录中包含实际上未讲述的单词。
原因可能是 Whisper 既试图预测音频中的下一个单词、又试图转录音频本身。

流程示例
此外 Whisper 在不同语言场景下的表现也不大一致,尤其涉及在训练数据中没有很好被代表的语言的讲述者时,其错误率也会更高。
不过后者在语音识别领域早已不是什么新鲜事,即使业内首屈一指的系统,也一直受到此类偏差的困扰。
参考斯坦福大学在 2020 年分享的一项研究结果 —— 相较于黑人,来自亚马逊、苹果、Google、IBM 和微软的系统,针对白人用户的错误率要低得多(大约 35%)。

Whisper 有约 1/3 的音频数据集为非英语
即便如此,OpenAI 还是认为 Whisper 的转录功能,可被用于改进现有的可访问性工具。其在 GitHub 上写道:
尽管 Whisper 模型不适用于开箱即用的实时转录,但其速度和大小表明,其他人可在此基础上构建近乎实时的语音识别和翻译应用程序。
建立在 Whisper 模型之上的有益应用程序,其价值切实地表明了这些模型的不同性能,有望发挥出真正的经济影响力。
我们希望大家能够将该技术积极应用于有益目的,使自动语音识别技术更易获得改进、让更多参与者能够打造出更负责任的项目。
在速度和准确性的双重优势下,Whisper 将允许对大量通信提供可负担得起的自动转录和翻译体验。
相关文章:
[视频]OpenAI展示DALL-E 2:AI图像生成器支持编辑图像了
美国芯片巨头英特尔与中方合作!将在深圳新建芯片创新中心
工信部要求开展 App 备案,微信小程序完成备案后才可上架

家乐福被裁员工曝未拿到补偿金,此前通知补偿金打6折一次性发和全款分12期之间二选一
全球勒索软件攻击创历史新高,美国是全球勒索软件攻击首要目标
美交管局对特斯拉部分车型展开调查,特斯拉部分车型被曝转向失灵
相关标签
相关文章
王慧文病休53天,旗下OneFlow团队重新创业
1年以前 | 1次阅读
智己CEO现场怒怼!不满LS6和小鹏G6当对手
1年以前 | 1次阅读
董明珠回应落榜世界500强:总比爆雷的世界500强好
1年以前 | 1次阅读
阿里云上线 AI 视频生成工具 Live Portait:可一键让照片开口说话
1年以前 | 78次阅读
妙鸭相机将并入神力视界,阿里大文娱CTO郑勇:不是“搬家”是“回家”
1年以前 | 85次阅读
特斯拉上海超级工厂约40秒下线一台车,零部件本土化率超95%
1年以前 | 69次阅读
宁德时代发布神行超充电池,可实现充电10分钟行驶800里
1年以前 | 71次阅读
中科院博士被骗到缅甸已一年!女友:他负债几万,家里条件一般,以为去当翻译
1年以前 | 85次阅读
小鹏汽车否认收购玛莎拉蒂传闻:系谣言
1年以前 | 63次阅读
联想二季度净利润猛降66%,股价应声跳水
1年以前 | 80次阅读
业内人士:视觉中国对不同侵权主体采用差异化策略,老客由销售沟通新客发律师函
1年以前 | 70次阅读
恒大集团在美国申请破产保护
1年以前 | 56次阅读
劳斯莱斯首款纯电轿跑将在北美亮相
1年以前 | 89次阅读
realme印度前CEO确认加盟荣耀,即将推出手机新品
1年以前 | 88次阅读
OpenAI正在测试内容审核系统,一天可以完成六个月的工作
1年以前 | 80次阅读
谷歌百人“复仇者联盟”出击,将发对标GPT-4的大模型,26位研发主管名单流出
1年以前 | 77次阅读
OpenAI收购数字产品公司Global Illumination,为创立以来首笔公开收购
1年以前 | 80次阅读
海口规定:电动汽车充电服务费不得超过0.65元每度
1年以前 | 80次阅读
波音任命柳青为波音中国总裁
1年以前 | 88次阅读
业内人士谈图片复杂代理链:图片代理商越多摄影师分成越少
1年以前 | 67次阅读